Advancing Mathematics by Guiding Human Intuition with AI
Alex Davies, Petar Veličković, Lars Buesing, Demis Hassabis, Pushmeet Kohli et al. — Nature 2021 (DeepMind)
2021 年 12 月,DeepMind 在 Nature 发表了一篇不寻常的论文。它没有刷新任何 benchmark,也没有提出新的网络架构,而是展示了一件更具想象力的事:用机器学习帮助数学家发现新定理。论文在纽结理论和表示论两个截然不同的纯数学领域验证了这一框架的通用性,直接催生了两项顶级数学发现。
研究动机
数学研究的核心驱动力是发现模式、提出猜想并证明定理。虽然计算机早就被用于穷举验证猜想(如千禧年大奖难题中的 Birch-Swinnerton-Dyer 猜想),但 AI 一直未在猜想生成中扮演核心角色。
现有方法的痛点:
- 维数灾难与认知极限:在高维空间或极复杂的图结构中,传统的数据驱动方法失效,人类专家也无法通过"肉眼看数据"发现规律
- AI 在纯数领域的缺位:先前生成猜想的系统要么方法无法泛化,要么给出的猜想在数学上缺乏深度(如只找到平凡的等式)
本文的核心思路:不尝试打造"自动定理证明机",而是将 AI 定位为数学家的"直觉放大器"——首创 Human-AI Symbiosis(人机共生)的纯数学研究范式。
核心框架
论文提出了一个极其通用、优雅的 AI 引导直觉工作流,分为数学家负责的步骤和 AI 负责的步骤:
| 步骤 | 负责方 | 内容 |
|---|---|---|
| 1. 提出假设 | 数学家 | 猜测 和 之间可能存在映射 |
| 2. 生成数据 | AI | 按分布 大量采样 数据对 |
| 3. 监督学习 | AI | 训练神经网络 ,验证关系是否存在 |
| 4. 归因分析 | AI | 用梯度显著性定位关键输入特征 |
| 5. 提出猜想 | 数学家 | 根据归因结果缩小排查范围,提出精确猜想 |
| 6. 证明定理 | 数学家 | 完成纯数学证明 |
若模型预测准确率远高于随机猜测,则暗示输入输出之间存在深刻的数学联系——这给予了数学家深入研究的信心。若归因分析无法提供有价值的线索,则回到数据收集环节调整数据分布或重新审视假设。
形式化建模
| 数学符号 | 语义 |
|---|---|
| 待研究的基础数学对象(纽结、排列群的区间等) | |
| 从对象 提取的已知属性集合(模型输入特征) | |
| 试图预测或关联的目标属性(模型标签/输出) | |
| 训练得到的深度学习近似函数, | |
| 对象 在数据生成过程中的采样分布 |
特征归因:从黑盒到线索
归因分析是框架中最核心的一步。为了搞清楚黑盒网络到底学到了什么,使用梯度显著性(Gradient Saliency)分析。对于输入特征 ,其重要性得分 的计算公式为:
即损失函数对该特征的梯度绝对值在整个数据集上的平均。归因得分高的特征 为数学家指明了最值得关注的方向。
实验一:纽结理论
背景
数学中的"纽结"是三维空间中不自我相交的闭合环。数学家定义了许多纽结不变量(Knot Invariants)来描述和区分纽结,这些不变量来自不同的数学分支——代数和几何。核心挑战在于:这些来自不同领域的不变量之间是否存在未知的深刻联系?
实验设置
- 任务类型:多分类任务(将 Signature 的离散整数值作为类别标签)
- 输入特征 :几何不变量——体积(Volume)、经度平移(Longitudinal translation)、子午线平移(Meridional translation)、短测地线(Short geodesic)、单射半径(Injectivity radius)等,复数特征拆分为实部和虚部
- 输出 :代数不变量——符号数(Signature )
- 数据集:Regina 普查数据(约 170 万个交叉数 的纽结)+ SnapPy 随机生成的 80 交叉数纽结(约 100 万个)+ 特殊辫群数据(约 3.5 万个)
- 模型:3 层前馈神经网络(每层 300 个神经元,Sigmoid 激活),Cross-Entropy 损失 + Adam 优化器
归因发现与新定理
模型在测试集上达到 78% 准确率(随机基线仅 25%),证明了几何与代数不变量之间确实存在强关联。
通过梯度归因分析,网络将高度注意力集中在了 3 个几何特征上:子午线平移的实部与虚部、经度平移。
数学家受此引导,定义了一个新的几何量"自然斜率"(Natural Slope):。绘制散点图发现它与 呈高度线性关系。最终数学家证明了以下定理:
这是一个全新的不等式,建立了几何不变量与代数不变量之间的定量关系——而这个发现的线索完全来自 AI 的归因分析。
实验二:表示论
背景
组合不变性猜想(Combinatorial Invariance Conjecture)已悬而未决 40 年。它认为 Kazhdan-Lusztig(KL)多项式可以完全由未标记的 Bruhat 区间(一种有向无环图)推导出来。
实验设置
- 任务类型:图级别回归/分类任务,预测 KL 多项式的各个系数
- 输入 :未标记的 Bruhat 区间图(节点表示排列,边表示反射,仅保留入度和出度特征)
- 输出 :KL 多项式系数( 前的常数)
- 数据集:遍历对称群至 ,通过等价类合并保留 24,322 个非同构图代表,80%/20% 划分训练/测试集
- 模型:消息传递神经网络(MPNN),双向传播,隐藏层维度 128,传播步数 4 步,带残差连接
GNN 预测结果
MPNN 的预测准确率远超随机基线,尤其在添加二面角注释后接近完美:
| 评估设置 | ||||
|---|---|---|---|---|
| 随机基线 | 21% | 12% | 29% | 88% |
| 全区间测试集 | 98% | 63% | 72% | 98% |
| 二面角注释测试 | 99.9% | 96.5% | 95.6% | 99.4% |
超立方体分解
通过对边特征进行归因分析(将归因度超过全局 99% 的节点及其子图定义为显著子图 ),发现了一个反直觉的现象:极端反射(Extremal reflections)在显著子图中出现的频率远超普通边。
顺着这个线索,数学家将图分解为两部分:一个由超立方体(Hypercube)构成的结构,和一个与 同构的结构,并提出了新定理:每一个 Bruhat 区间都允许沿着极端反射进行规范的超立方体分解,可以直接从中计算 KL 多项式。该猜想已在包含多达 个区间(直至 )的计算机验证中得到确认。
讨论与展望
创新之处
- 哲学视角的突破:摒弃"AI 替代数学家证明"的不切实际幻想,将 AI 定位为"直觉放大镜"。这种 Human-in-the-loop 研究范式切中要害
- 工程实现的巧妙:论文中的深度学习技术(三层 MLP、基础 MPNN、Vanilla Gradient 归因)非常基础甚至老派。正是这种"奥卡姆剃刀"式的选择极大提升了模型的可解释性——如果使用黑盒 Transformer,数学家反而难以做归因分析
- 硬核成果背书:真正推导出了基础数学领域的两项新发现并在顶刊发表
不足与局限
- 数据可计算性瓶颈:框架强依赖于"能够廉价、大量地生成带标注样本"。如果某个前沿数学猜想连计算 的数据都耗时以年计,该框架将无米之炊
- 归因方法的局限:仅使用了简单的基于梯度的显著性。这类归因方法容易受到噪声干扰,在更复杂的映射中可能需要 Integrated Gradients 或 SHAP 才能避免误导
启示
在大模型横行的时代,这篇论文揭示了一个反直觉的洞见:模型不需要完美,它只需要"比瞎猜好"就能引发科学发现。纽结实验中预测准确率只有 78%;KL 多项式 系数的准确率只有 63%。但对数学家而言,这种偏离随机分布的微弱信号(63% vs 12%),就如同暗夜里微弱但确定的灯塔——它宣告两个相隔千里的概念之间一定存在映射。
该框架可以平移到代数几何、数论等拥有海量结构化可计算对象的分支。未来还可以引入符号回归(Symbolic Regression),不仅提供 Saliency 权重,还直接向数学家"吐出"候选解析公式。
代码实战
完整的代码实战复现了论文的核心方法论,包含两个实验:
![]()
实验 1:纽结不变量预测
用合成数据模拟论文的纽结理论实验。构造 30 个几何特征,其中仅 3 个与输出存在真实依赖关系:
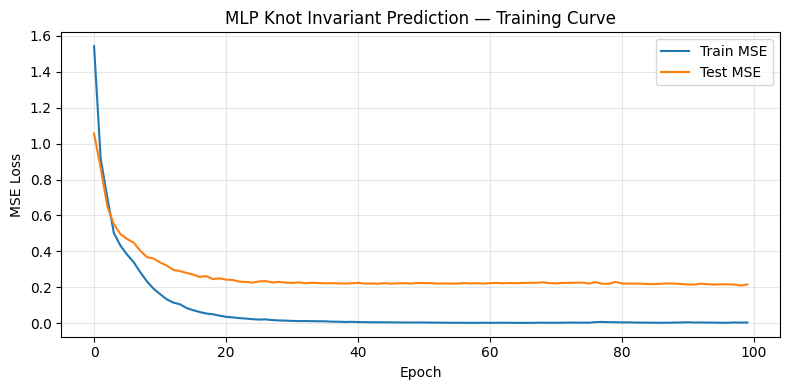
训练 MLP(30 → 128 → 128 → 128 → 1)后,在测试集上达到 ,证明关系可学习:
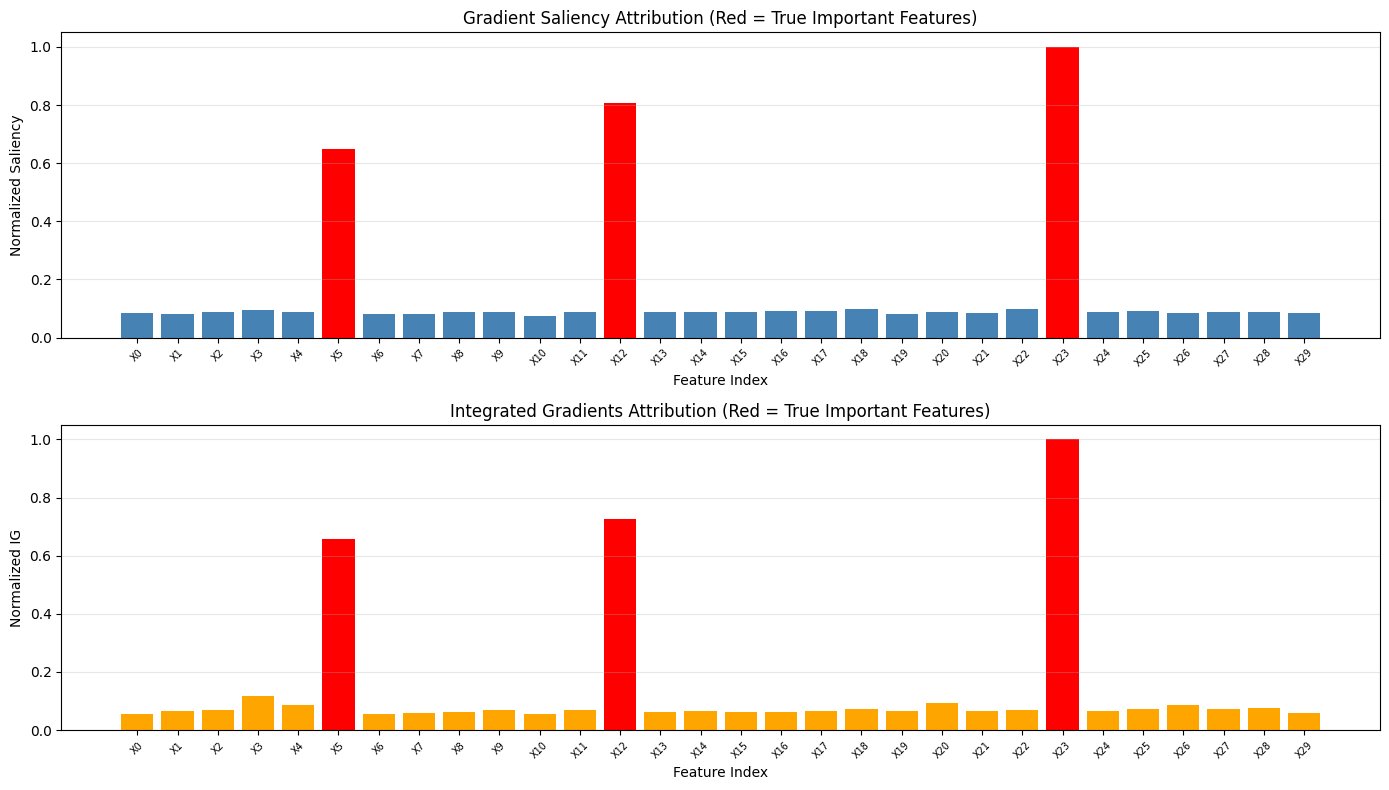
使用 Captum 库进行归因分析——Saliency 和 Integrated Gradients 两种方法均成功识别出全部 3 个真实重要特征(红色柱),与 27 个噪声特征形成鲜明对比:
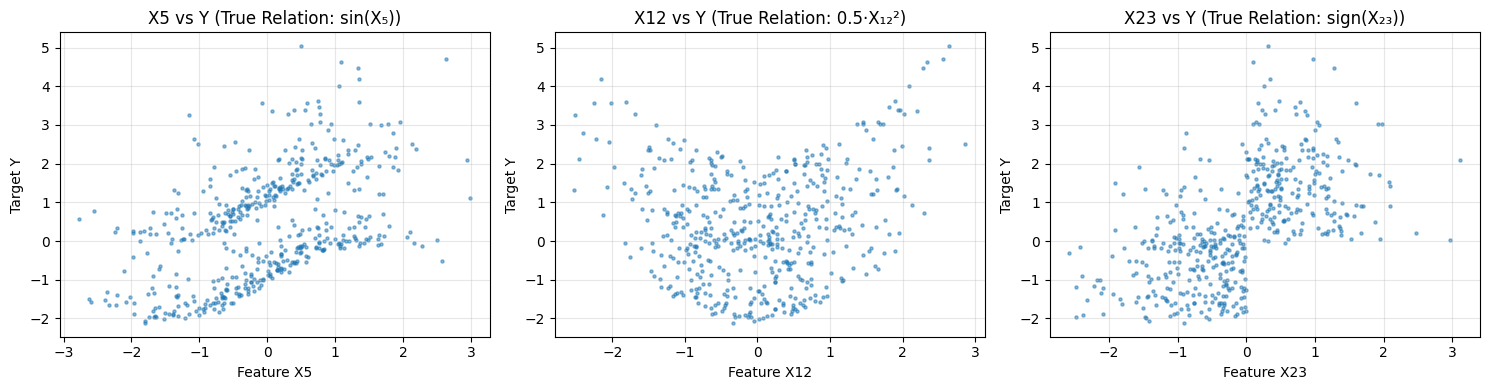
进一步绘制特征与目标的散点图,可以直观看到各特征与目标的非线性关系,为数学家提出精确猜想提供线索:
归因分析的核心代码:
from captum.attr import Saliency, IntegratedGradients
model.eval()
saliency = Saliency(model)
ig = IntegratedGradients(model)
# Saliency: 单点梯度的绝对值
saliency_attr = saliency.attribute(test_input, target=None, abs=True)
mean_saliency = saliency_attr.mean(dim=0).detach().cpu().numpy()
# Integrated Gradients: 从基线到输入的路径积分
ig_attr = ig.attribute(test_input, target=None, n_steps=50)
mean_ig = ig_attr.abs().mean(dim=0).detach().cpu().numpy()实验 2:图结构性质预测
用合成图数据模拟论文的表示论实验:
- 从 Erdos-Renyi 随机图中提取 10 个统计特征(节点数、边数、密度、聚类系数等)
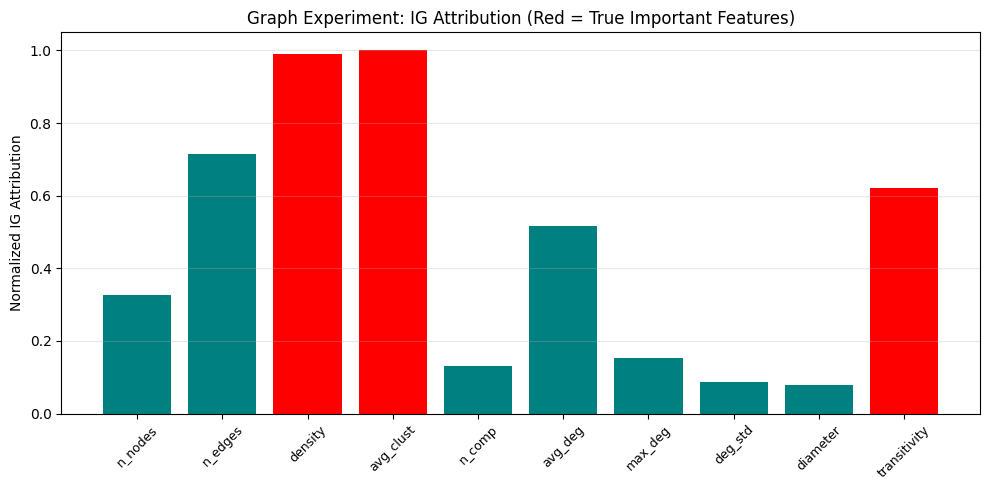
- 目标值仅依赖其中 3 个特征:
- 模型测试
Integrated Gradients 归因再次准确识别出真实重要特征:
两种归因方法对比
| Saliency | Integrated Gradients | |
|---|---|---|
| 计算方式 | 单点梯度的绝对值 | 从基线到输入的路径积分 |
| 公理满足 | 不满足完整性公理 | 满足完整性公理 |
| 计算成本 | 低(一次反向传播) | 高(多次反向传播) |
| 稳定性 | 可能受局部噪声影响 | 更稳定、更全局 |
参考文献
- Davies, A., Veličković, P., Buesing, L., et al. (2021). Advancing mathematics by guiding human intuition with AI. Nature, 600, 70-74.
- 李沐. AI for Math 论文精读. Bilibili.
- Captum. Model Interpretability for PyTorch. PyTorch official attribution library.