Competition-Level Code Generation with AlphaCode
Yujia Li et al. — Science 2022 (Google DeepMind)
AlphaCode 真正让人震撼的,并不是“模型终于会写几段代码”,而是它第一次把代码生成推进到了 编程竞赛级别。竞赛题不是补全几个 API 调用,也不是把注释翻译成样板函数,而是要求系统在全新题面上理解约束、设计算法、处理边界条件,并最终通过隐藏测试。对这样的任务来说,单次生成的流畅与否远远不够,真正关键的是:如何在巨大的候选空间里找到最可能解对题的程序。
如果说 Codex 把代码生成的评估方式从“像不像参考答案”推进到了“能不能跑、能不能过测试”,那么 AlphaCode 则进一步回答了一个更难的问题:面对需要算法创造力和有限提交预算的竞赛场景,代码模型应该怎样组织自己的候选空间。论文给出的答案不是更激进的单次解码,而是一整套“生成、执行、打分、聚类、选择”的系统流程。这也是今天很多代码 Agent、自动修复系统与执行反馈工作流的思想源头之一。
研究动机
在 AlphaCode 之前,代码模型已经能在函数补全、docstring-to-code 之类的任务上取得可观效果,但编程竞赛暴露了另一层难度。它至少比普通代码生成多出三个约束:
- 题面更长、约束更复杂:模型需要先理解自然语言问题、输入输出格式和边界条件,再决定算法思路。
- 正确性标准更苛刻:代码不是“看起来合理”就够了,而是必须通过隐藏测试。
- 提交预算有限:竞赛通常只允许有限次数提交,因此系统必须尽量把正确解稳定排进前几名候选。
这也解释了为什么 AlphaCode 不满足于沿用 ,而是引入更贴近竞赛提交约束的 。两者关注的问题并不一样:
| 指标 | 含义 | 更适合描述什么 |
|---|---|---|
| 前 个候选里至少有一个正确 | 函数级代码生成里“有没有抽到可用答案” | |
| 前 个提交里至少有 个正确 | 竞赛场景里“有限提交位下的稳定命中能力” |
换句话说,AlphaCode 真正想解决的,不是“模型能不能偶尔写对一道题”,而是 模型能否在全新题面上提出一组有竞争力的候选,并把最可能正确的那些放到最前面。
核心方法/模型架构
从形式上看,AlphaCode 的生成器仍然是标准的条件序列建模。给定题目描述 ,模型按自回归方式生成代码序列 :
但论文真正的贡献,并不只在这条公式,而在于它围绕这条生成过程搭起了一条完整系统链路:
- 生成器 根据题目描述采样出海量候选程序。
- 执行过滤 用公开测试快速剔除明显错误的候选。
- 判别与排序 用正确性信号和 reranker 估计哪些程序更可能真的解对题。
- 聚类选择 在保留高分候选的同时压制重复思路,提升提交多样性。
从结构上看,AlphaCode 并没有提出全新的神经网络骨架,而是采用了 Transformer 编码器-解码器。这并不是一个无关紧要的实现细节。竞赛题面通常比最终代码更长、更啰嗦,系统需要先“读懂题”,再逐 token 写程序,因此 encoder-decoder 结构天然适合把“理解题面”和“生成代码”拆成两个相对清晰的子问题。
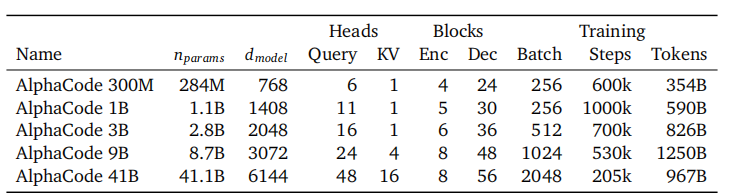
论文在配置上也体现了这种任务特性:编码器层数较少,解码器层数较多;编码器处理更长的题面序列,解码器负责更密集的程序生成。下面这张图展示了 AlphaCode 不同规模模型的大致配置,也能看出论文真正关心的不只是“参数更大”,而是 参数规模、训练 token 数和解码器容量 如何一起服务于长序列代码生成:
组件详解
两阶段训练:先学会编程,再学会比赛
AlphaCode 的训练不是直接拿竞赛题从零开始学,而是先做大规模通用代码预训练,再做竞赛专项微调。
第一阶段使用公开 GitHub 代码库快照做自监督训练,让模型掌握多种语言的语法结构、常见实现模式和库调用方式。第二阶段再切换到 CodeContests 数据集,把这些通用编程知识重新组织成“题意理解 -> 算法实现”的竞赛能力。
CodeContests 的价值非常高,因为它不只提供题面,还同时提供:
- 正确提交与错误提交
- 公开测试与隐藏测试
- 来自多个竞赛平台的真实题目分布
这意味着模型学到的不只是“什么样的代码像代码”,还包括“什么样的代码更可能解对题”。从方法论上看,这一步其实已经把 AlphaCode 从普通语言模型拉向了 面向功能正确性的程序生成系统。
编码器-解码器:把“读题”和“写代码”分开
论文坚持使用 encoder-decoder 的一个重要原因,是竞赛题并不是短 prompt 补全,而是更接近“长题面到程序”的翻译问题。编码器负责把题目描述压缩成可查询的语义表示,解码器则在这些表示上自回归生成代码。
这种结构与 AlphaCode 的任务特性高度一致:
- 编码器 负责吃下长题面、输入输出约束和背景描述。
- 解码器 负责逐 token 生成程序,并维护代码前缀的一致性。
- cross-attention 负责把“当前要生成的代码位置”与“题面的关键信息”对齐起来。
相比纯 decoder-only 方案,这种分工对长题面和复杂约束更自然,也更方便做容量上的不对称配置。也正因为如此,AlphaCode 的重点并不是“把补全模型直接放大”,而是让生成器更像一个真正会读题的程序求解器。
正确性信号与 reranker:从“像代码”走向“像正确解”
AlphaCode 的一个关键改进,是它不满足于语言模型只学“下一个 token 像不像代码”,而是试图额外引入“这段代码是否更可能解对题”的信号。笔记里可以把这种训练目标写成下面三部分:
这里的直觉很直接:
LM Loss保证输出像一段语法正确、风格合理的程序。Cls Loss试图把“这段代码像不像正确解”并入训练信号。reranker则在推理阶段单独承担二次打分职责。
也就是说,AlphaCode 并不是像 GAN 那样把生成器和判别器放进同一个对抗回路,而是采取 先生成,再过滤,再评分,再排序 的系统式组合方式。它真正关心的不是某一段代码局部上是否更像训练语料,而是整个候选池中哪些程序更值得进入最终提交列表。
候选生成:为什么要故意制造多样性
AlphaCode 并不押注单次输出,而是故意制造一个尽可能多样化的候选空间。论文里一个很有代表性的技巧,是在生成前加入随机化元数据,例如语言、难度评级和标签等,让模型从不同条件分布出发生成解法。
可以把这种输入头部理解成下面这类带元数据的题面模板:

这背后的思想并不复杂:如果总是从同一个固定 prompt 出发,模型很容易在高概率区域里反复生成相似代码;而随机化元数据后,候选分布会被主动拉开,从而为后续的测试过滤和聚类选择留下空间。换句话说,AlphaCode 并不是把“多样性”当成副作用,而是把它当成成功概率的一部分主动去设计。
过滤、聚类与 :AlphaCode 真正强的地方
这部分是 AlphaCode 与普通“代码生成模型”最不一样的地方。它真正强的不是单个样本质量,而是整个候选池的组织方式。
论文笔记里的筛选流程可以压缩为五步:
- 大量生成:先采样出海量候选程序。
- 去重与编译检查:剔除重复、语法错误或无法运行的程序。
- 公开测试过滤:先用 public tests 快速淘汰明显错误解。
- 聚类保多样性:把语义或行为相近的程序聚成簇,避免前几名候选全是同一路思路的小变体。
- 排序后提交:综合 reranker 分数、聚类结构与测试结果,决定最终提交顺序。
而 则可以写成一个更贴近竞赛提交预算的概率问题:
其中 是候选总数, 是正确候选数, 是允许保留的提交位。和 相比,它更强调:正确解能不能稳定地排进前列,而不是偶尔抽中一次。
从今天回看,这一整套设计的意义非常大。它等于明确告诉大家:面对需要真实执行验证的任务时,模型本身往往只是候选生成器,真正决定系统上限的是后续的测试、反馈和筛选机制。
实验结果
AlphaCode 的评测选择了 10 场位于训练数据截止日期之后的 Codeforces 竞赛,这意味着它面对的是 训练中没有见过的全新题目。这一点极其关键,因为如果题目在训练集中出现过,模型就可能只是在复述或拼接已有解法,而不是展示真实的泛化能力。
最终结果之所以有冲击力,不是因为某一个 benchmark 数字特别高,而是因为 AlphaCode 在这种全新竞赛题设置下,平均表现已经接近 人类参赛者中位水平。这说明它已经不是“会生成看起来像代码的文本”,而是能够在一定程度上提出真正可提交、可竞争的程序候选。
当然,这个结果也有清晰边界:
- 它依赖大规模采样和复杂后处理,不是单次前向传播就能解决问题。
- 它主要证明“竞赛级代码生成是可能的”,并不意味着通用软件工程任务已经被彻底解决。
- 它的强项是候选生成与筛选系统,而不是稳定地产生唯一最优解。
也正因为这些边界存在,AlphaCode 才更像一篇“系统范式论文”,而不只是一次“模型规模竞赛”。
总结
AlphaCode 的核心贡献,不是再造一个更大的代码模型,而是把代码生成推进到了 系统工程阶段。它让研究者看到:面对需要算法创造力、执行验证和有限提交预算的任务时,单纯提高单样本质量并不够,真正有效的路线是把生成、执行、判别、聚类和排序串成一个闭环。
从这个角度看,AlphaCode 的意义甚至不只属于编程竞赛。它更像是在提前展示一种后来越来越常见的范式:让模型先提出候选,再让外部工具帮助验证和筛选。今天很多代码 Agent、自动修复工作流和执行反馈系统,本质上都在沿着这条路线往前走。
代码实战
如果只看 AlphaCode 的 headline result,很容易把它理解成“更大的模型 + 更多的采样”。但真正值得动手的,不只是把生成器跑起来,而是同时理解三件事:encoder-decoder 为什么适合竞赛题、正确性信号为什么重要、候选池为什么必须经过过滤和重排。下面这个 Notebook 就沿着这三条线并行展开。
完整代码实战:
![]()
学习路径:先把 encoder-decoder 与因果约束讲清楚
第一段最值得看的代码,不是训练循环,而是解码器怎样同时处理 causal mask 和 cross-attention。它对应的是 AlphaCode 成立的最小结构骨架:编码器先读题,解码器再在题意约束下逐步写代码。
def decode(self, tgt_ids, memory, memory_pad_mask):
tgt_pad_mask = tgt_ids.eq(PAD_ID)
tgt_mask = causal_mask(tgt_ids.size(1), tgt_ids.device)
x = self.embed_tokens(tgt_ids)
for block in self.decoder_blocks:
x = block(x, memory, tgt_mask, tgt_pad_mask, memory_pad_mask)
return x如果你在面试里需要解释为什么竞赛任务更适合 encoder-decoder,而不是纯 decoder-only,这一段就是最直接的落点:模型不是只在续写代码,它还必须持续回看题面表示。
学习路径:把“解对题”信号并入训练目标
第二段代码对应的是 AlphaCode 最关键的方向性改造:代码生成模型不该只学语法流畅度,还应该有某种“正确性偏置”。Notebook 用一个教学化的 correctness signal,把语言建模损失和辅助分类损失结合起来:
lm_loss = F.cross_entropy(
logits_pos.reshape(-1, model.vocab_size),
tgt_out.reshape(-1),
ignore_index=PAD_ID,
)
cls_logits = torch.cat([cls_pos, cls_neg], dim=0)
cls_targets = torch.cat([
torch.ones_like(cls_pos),
torch.zeros_like(cls_neg),
], dim=0)
cls_loss = F.binary_cross_entropy_with_logits(cls_logits, cls_targets)
total_loss = lm_loss + lambda_cls * cls_loss这当然不是论文中完整 reranker 流程的工业复刻,但它很好地把论文想表达的方向展示了出来:对代码任务来说,“像代码”与“像正确解”并不是同一个目标。
工程路径:用 nn.Transformer 快速搭一个 baseline
第三段代码对应工程路径。真实项目里很多时候并不会从零手写完整 AlphaCode,而是先用高层 API 搭一个可运行 baseline,再观察哪些模块是真正不可省的。Notebook 用 nn.Transformer 压缩了主干,只保留位置编码、mask 和生成逻辑这些真正决定行为的部分:
def decode(self, tgt_ids, memory, memory_pad_mask):
tgt_pad_mask = tgt_ids.eq(PAD_ID)
tgt_mask = nn.Transformer.generate_square_subsequent_mask(
tgt_ids.size(1), device=tgt_ids.device
)
tgt_emb = self.embed_tokens(tgt_ids)
dec_out = self.transformer.decoder(
tgt=tgt_emb,
memory=memory,
tgt_mask=tgt_mask,
tgt_key_padding_mask=tgt_pad_mask,
memory_key_padding_mask=memory_pad_mask,
)
return dec_out这条路径的价值,不在于“更高级”,而在于它能帮你快速回答一个工程问题:如果我已经理解 AlphaCode 的核心机制,怎样最短路径做出一个能运行、能讲清楚的 baseline。
系统层:用 把候选池质量量化出来
Notebook 最有 AlphaCode 味道的部分,是它没有停在模型前向传播,而是继续做了 toy 版的 public tests、聚类和 评估。最后这一段函数,正好把“有限提交位里的成功概率”写成了可直接计算的形式:
def n_at_k(total_candidates, correct_count, n, k):
from math import comb
if total_candidates == 0 or k > total_candidates or n > k:
return 0.0
denom = comb(total_candidates, k)
prob_less_than_n = 0.0
for i in range(n):
if correct_count >= i and (total_candidates - correct_count) >= (k - i):
prob_less_than_n += comb(correct_count, i) * comb(total_candidates - correct_count, k - i) / denom
return 1.0 - prob_less_than_n相比只看单次输出是否正确,这种写法更贴近 AlphaCode 的真实目标:候选池是否足够强,能不能把正确解稳定推到前面。这也是整篇论文最值得迁移到今天代码 Agent 语境中的思想之一。
参考文献
- Li, Y., et al. (2022). Competition-Level Code Generation with AlphaCode. Science / arXiv.
- Google DeepMind. Competitive programming with AlphaCode.
- Google DeepMind. code_contests.
- Li, Y., et al. (2022). Competition-level code generation with AlphaCode. Science.
- 李沐. DeepMind AlphaCode 论文精读. Bilibili.