Attention Is All You Need
Ashish Vaswani, Noam Shazeer, Niki Parmar, Jakob Uszkoreit, Llion Jones, Aidan N. Gomez, Łukasz Kaiser, Illia Polosukhin — NIPS 2017 (Google Brain / Google Research)
Transformer 由 Google 团队于 2017 年在论文《Attention Is All You Need》中提出,完全摒弃了 RNN 和 CNN,仅基于注意力机制构建序列到序列模型。这一架构后来成为 BERT、GPT 等大型语言模型的基础,彻底改变了 NLP 领域的发展方向。
研究动机
Transformer 的提出源于对 RNN 和 CNN 在序列建模中局限性的思考。
RNN 的局限:
- 难以并行:RNN 按时间步逐个计算隐藏状态 ,天然的时序依赖使其无法并行处理。
- 长距离依赖困难:历史信息通过隐藏状态逐步传递,序列越长,早期信息越容易丢失。增大隐藏状态维度虽可缓解,但会显著增加内存开销。
CNN 的局限:
- 感受野有限:卷积每次只关注局部窗口,两个距离较远的位置需要堆叠多层卷积才能建立联系。
Transformer 的注意力机制在单层内即可建模序列中任意两个位置的关系,同时通过多头机制模拟 CNN 的多通道特性,兼顾全局建模能力和多模式捕捉能力。
模型架构
编码器-解码器结构
Transformer 采用经典的 Encoder-Decoder 结构:
- 编码器(Encoder):将输入序列 编码为连续表示序列 ,其中每个 是对应词的向量表示。
- 解码器(Decoder):接收编码器输出 ,自回归(auto-regressive)地逐个生成输出序列 。输出长度 与输入长度 可以不同(例如翻译任务中,一个英语单词不一定对应一个中文字)。
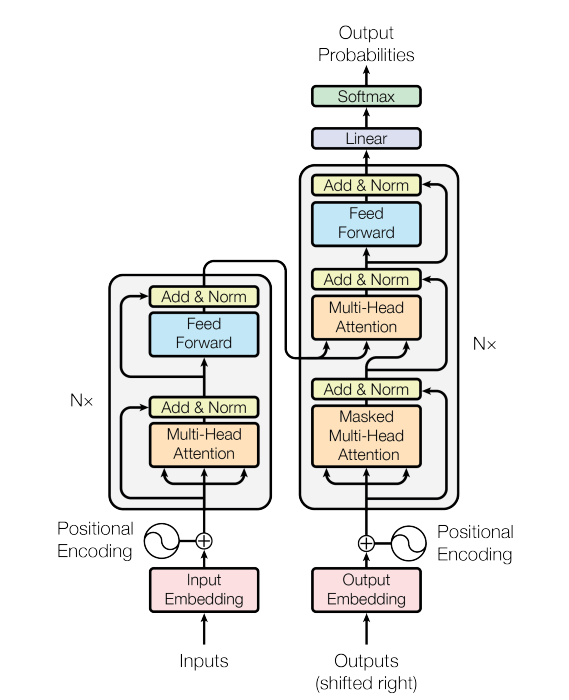
编码器
编码器由 个相同的层堆叠而成,每个层包含两个子层:
- 多头自注意力机制(Multi-Head Self-Attention)
- 前馈神经网络(Feed-Forward Network)
每个子层都使用残差连接和层归一化:。为使残差连接生效,所有子层及 Embedding 层的输出维度统一为 。
解码器
解码器同样由 个相同的层堆叠,每个层包含三个子层:
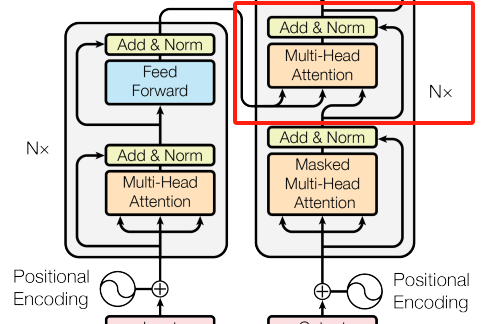
- 掩码多头自注意力(Masked Multi-Head Self-Attention):通过掩码确保位置 的预测只能依赖 之前的已知输出,防止信息泄露。
- 编码器-解码器注意力(Encoder-Decoder Attention):Query 来自解码器上一子层的输出,Key 和 Value 来自编码器的输出,使解码器能关注输入序列的所有位置。
- 前馈神经网络:与编码器相同,对每个位置独立进行非线性变换。
注意力机制
注意力函数的本质是将一个 Query 和一组 Key-Value 对映射到输出。输出是 Value 的加权和,权重由 Query 与对应 Key 的相似度决定。
缩放点积注意力(Scaled Dot-Product Attention)
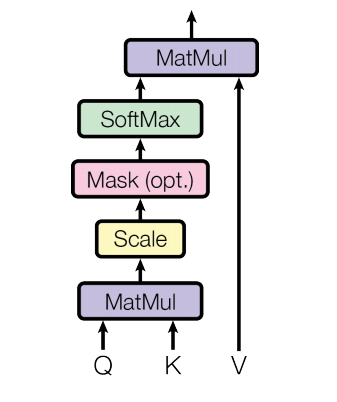
计算步骤:
- 点积:计算 Query 与所有 Key 的点积
- 缩放:除以
- 掩码(可选):在解码器中,将未来位置的值设为
- Softmax:将得分转化为概率分布
- 加权求和:用概率分布对 Value 加权
为什么要除以 ? 当 较大时,点积结果的方差随之增大,导致 softmax 输出趋近于 one-hot 分布(某个值接近 1,其余接近 0)。在这种饱和区域梯度极小,模型难以训练。除以 可以将方差稳定在合理范围。
Mask 的作用:训练阶段解码器的输入是完整的目标序列,但预测第 个词时不应看到第 个之后的内容(否则直接抄答案了)。具体实现是将 与 的注意力分数设为 ,经过 softmax 后权重趋近于 0。
PyTorch 实现:
def masked_softmax(scores, valid_lens):
"""对 scores 做 softmax,将 valid_lens 之外的位置 mask 为 -inf。"""
if valid_lens is None:
return torch.softmax(scores, dim=-1)
shape = scores.shape
if valid_lens.dim() == 1:
valid_lens = valid_lens.unsqueeze(1).expand(-1, shape[1])
mask = torch.arange(shape[-1], device=scores.device).unsqueeze(0).unsqueeze(0)
mask = mask >= valid_lens.unsqueeze(-1)
scores = scores.masked_fill(mask, -1e9)
return torch.softmax(scores, dim=-1)
class DotProductAttention(nn.Module):
def __init__(self, dropout):
super().__init__()
self.dropout = nn.Dropout(dropout)
def forward(self, queries, keys, values, valid_lens=None):
d = queries.shape[-1]
scores = torch.bmm(queries, keys.transpose(1, 2)) / math.sqrt(d)
attention_weights = masked_softmax(scores, valid_lens)
return torch.bmm(self.dropout(attention_weights), values)多头注意力(Multi-Head Attention)
多头注意力将输入分别通过 组不同的线性投影,独立计算注意力后拼接输出:
关键参数:
| 参数 | 含义 | 论文取值 |
|---|---|---|
| 注意力头数 | 8 | |
| 模型总维度 | 512 | |
| 每个头的维度 | 64 |
每个头的投影矩阵:,,输出投影矩阵 。
设计动机:
- 多模式捕捉:类比 CNN 的多输出通道,每个头可以学习不同的关注模式(如语法关系、语义依赖、上下文关联等)。
- 总计算量不变:虽然有 个头,但每个头的维度缩小为 ,总计算量与单头全维度注意力相当。
PyTorch 实现:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout):
super().__init__()
self.num_heads = num_heads
self.d_k = d_model // num_heads
self.W_q = nn.Linear(d_model, d_model, bias=False)
self.W_k = nn.Linear(d_model, d_model, bias=False)
self.W_v = nn.Linear(d_model, d_model, bias=False)
self.W_o = nn.Linear(d_model, d_model, bias=False)
self.attention = DotProductAttention(dropout)
def _split_heads(self, X):
"""(batch, seq, d_model) → (batch*h, seq, d_k)"""
batch, seq, _ = X.shape
X = X.view(batch, seq, self.num_heads, self.d_k)
X = X.transpose(1, 2)
return X.reshape(batch * self.num_heads, seq, self.d_k)
def _merge_heads(self, X, batch_size):
"""(batch*h, seq, d_k) → (batch, seq, d_model)"""
X = X.view(batch_size, self.num_heads, -1, self.d_k)
X = X.transpose(1, 2)
return X.reshape(batch_size, -1, self.num_heads * self.d_k)
def forward(self, queries, keys, values, valid_lens=None):
batch_size = queries.shape[0]
Q = self._split_heads(self.W_q(queries))
K = self._split_heads(self.W_k(keys))
V = self._split_heads(self.W_v(values))
if valid_lens is not None:
valid_lens = valid_lens.repeat_interleave(self.num_heads, dim=0)
output = self.attention(Q, K, V, valid_lens)
return self.W_o(self._merge_heads(output, batch_size))维度验证:
MultiHeadAttention: torch.Size([2, 8, 32]) → torch.Size([2, 8, 32])
三种注意力的使用方式
Transformer 中注意力机制分为三种场景:
- 编码器自注意力:Q、K、V 均来自编码器上一层的输出,每个位置可关注输入序列的所有位置。
- 解码器掩码自注意力:Q、K、V 均来自解码器上一层的输出,通过掩码限制每个位置只能关注自身及之前的位置。
- 编码器-解码器注意力:Q 来自解码器,K 和 V 来自编码器输出,使解码器能够聚焦输入序列的相关部分。
Layer Normalization vs Batch Normalization
Transformer 使用 Layer Normalization(LN)而非 Batch Normalization(BN),原因与 NLP 数据的特性有关。
NLP 中输入数据是三维张量 (batch, seq, feature),其中 batch 是训练样本数,seq 是序列长度,feature 是特征维度。
| 归一化方式 | 计算范围 | 问题 |
|---|---|---|
| BN | 沿 batch 维度,对每个特征位置计算均值和方差 | 序列长度不等时需填充 0,导致统计量不稳定;推理时遇到超长序列,预训练的全局统计量不适用 |
| LN | 沿 feature 维度,对每个样本独立计算均值和方差 | 不受序列长度和 batch 内其他样本影响,统计量稳定 |
由于 NLP 任务中各样本的序列长度通常不一致,BN 在 batch 维度上计算统计量时会受到大量填充值的干扰,而 LN 在每个样本内部独立计算,天然适合变长序列场景。
前馈神经网络(FFN)
每个编码器/解码器层中都包含一个逐位置的前馈网络,对序列中的每个位置独立且相同地应用:
- 内层维度 (将 512 维扩展至 2048 维)
- 外层维度恢复为
- 激活函数:ReLU
Attention 与 FFN 的分工:Attention 负责在序列维度上汇聚全局信息,使每个位置的表示融合了全局上下文;FFN 随后对每个位置独立地进行语义空间转换。这与 RNN 形成对比——RNN 通过隐藏状态 传递时序信息再经过 MLP 转换,而 Transformer 通过 Attention 一次性获取全局时序信息后再经过 FFN 转换。
Embedding 与位置编码
Embedding
Transformer 在三个位置使用 Embedding:
- 编码器输入 Embedding:将输入词映射为 维向量
- 解码器输入 Embedding:将已生成的输出词映射为 维向量
- 输出层:解码器输出()经线性层( 参数矩阵)映射为词表大小的向量(),再经 Softmax 得到概率分布,取最大值对应的词作为预测结果
位置编码(Positional Encoding)
注意力机制本身是排列不变的——打乱输入顺序不会改变输出。为引入序列的顺序信息,Transformer 对输入 Embedding 加入位置编码:
其中 是位置索引, 是维度索引。位置编码与词嵌入维度相同(),两者直接相加。
PyTorch 实现:
class PositionalEncoding(nn.Module):
def __init__(self, d_model, dropout, max_len=1000):
super().__init__()
self.dropout = nn.Dropout(dropout)
pe = torch.zeros(max_len, d_model)
pos = torch.arange(0, max_len, dtype=torch.float32).unsqueeze(1)
div_term = torch.exp(
torch.arange(0, d_model, 2, dtype=torch.float32)
* (-math.log(10000.0) / d_model))
pe[:, 0::2] = torch.sin(pos * div_term) # 偶数维:sin
pe[:, 1::2] = torch.cos(pos * div_term) # 奇数维:cos
self.register_buffer('pe', pe.unsqueeze(0))
def forward(self, X):
X = X + self.pe[:, :X.shape[1], :]
return self.dropout(X)复杂度比较
| 层类型 | 每层计算复杂度 | 顺序操作数 | 最大路径长度 |
|---|---|---|---|
| Self-Attention | |||
| Recurrent | |||
| Convolutional | |||
| Self-Attention (restricted) |
其中 为序列长度, 为表示维度, 为卷积核大小, 为受限自注意力的窗口大小。
Self-Attention 的计算复杂度推导: 为 , 为 ,总复杂度为 。
关键优势:Self-Attention 的顺序操作数为 (完全可并行),且任意两个位置之间的最大路径长度为 (单层即可直接交互),这两点是 RNN 的 和 CNN 的 无法比拟的。
总结
Transformer 的核心贡献在于证明了仅凭注意力机制即可构建强大的序列模型,无需 RNN 的循环结构或 CNN 的卷积操作。其并行计算能力、全局建模能力和灵活的架构设计使其成为后续 BERT、GPT、T5 等大型语言模型的基础架构,深刻改变了自然语言处理乃至整个深度学习领域的发展轨迹。
代码实战
完整的 Transformer 代码实现(英→法翻译任务),包含源代码实现与 nn.Transformer 简洁实现两种方式的对比:
![]()
参考文献
- Vaswani, A., et al. (2017). Attention Is All You Need. NeurIPS 2017.
- 李沐. Transformer 论文逐段精读. Bilibili.
- 李宏毅. Transformer. YouTube.