BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding
Jacob Devlin, Ming-Wei Chang, Kenton Lee, Kristina Toutanova — NAACL 2019 (Google AI Language)
BERT(Bidirectional Encoder Representations from Transformers)由 Google 于 2018 年提出,通过深度双向 Transformer 编码器和两个创新的预训练任务(MLM + NSP),开创了"预训练 + 微调"范式,在多项 NLP 基准上刷新了当时的最佳成绩。这一工作标志着 NLP 正式进入大规模无监督预训练的时代。
研究动机
预训练模型的两种策略
使用预训练模型做特征表示时,主要有两类策略:
- 基于特征(Feature-based):为下游任务构造特定的网络结构,将预训练得到的表示作为额外特征与原始输入一起输入模型(如 ELMo)。ELMo 分别独立训练了前向和后向两个单向 LSTM,然后在顶层进行浅层拼接,并非真正的深度双向。
- 基于微调(Fine-tuning):先在大规模语料上预训练通用模型,然后在下游任务上继续训练全部参数,使模型适应新任务(如 GPT、BERT)。然而 GPT 使用的标准语言模型是单向的(从左到右),每个 token 只能看到它左侧的上下文。
核心问题
对于句子级别的分类任务,单向模型可能勉强够用。但对于 Token 级别任务(如 SQuAD 阅读理解),理解一个词不仅需要知道它前面说了什么,更需要知道它后面说了什么。单向限制对这类任务是极其有害的。
BERT 的核心突破在于:利用 Transformer Encoder 的自注意力机制,使每个位置能同时关注左右两侧的上下文,通过引入 Masked Language Model(MLM)和 Next Sentence Prediction(NSP)两个预训练任务,实现真正的深度双向表示。
模型架构
基础架构
BERT 基于 Transformer 的 Encoder 部分(不使用 Decoder),提供两种规模:
| 模型 | 层数 () | 隐藏维度 () | 注意力头数 () | 参数量 |
|---|---|---|---|---|
| BERT-Base | 12 | 768 | 12 | 1.1 亿 |
| BERT-Large | 24 | 1024 | 16 | 3.4 亿 |

输入表示
BERT 的输入是一个序列,可以是单个句子或两个句子拼接。与原始 Transformer 不同,BERT 只有编码器,通过将句子对拼接为一个序列来处理。
特殊标记:
[CLS]:始终放在序列开头。经过多层 Transformer 编码后,其输出向量聚合了整个序列的全局信息,用作分类任务的特征。之所以选择[CLS]而非其他位置的输出,是因为其他位置的词向量受 MLM 训练目标引导,偏向于表示对应词本身的语义;[CLS]没有这种偏向,能更纯粹地关联全局信息。[SEP]:用于分隔两个句子。
输入向量由三部分相加得到:
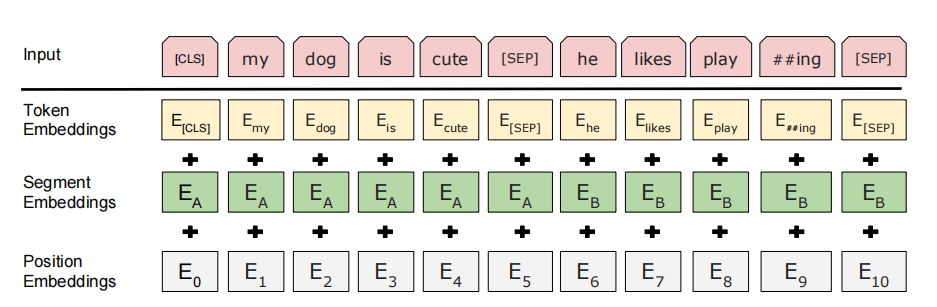
- Token Embeddings:基于 WordPiece 分词的词嵌入。WordPiece 将词拆分为子词单元(如
unhappiness→un,##happi,##ness),有效减少词表规模(约 30,000)并处理未登录词。 - Segment Embeddings:区分句子 A 和句子 B 的学习向量( 和 )。
- Position Embeddings:位置编码向量。与 Transformer 使用固定三角函数不同,BERT 的位置编码是学习得到的,最大长度为 512。
预训练任务
BERT 的预训练采用两个任务联合训练(multi-task joint training),总损失 = MLM 损失 + NSP 损失,模型参数同时优化。
Masked Language Model(MLM)
目标:实现深度双向上下文理解。传统语言模型只能单向预测,无法同时利用双向信息。
方法:随机遮盖输入序列中 15% 的 token(不包括 [CLS] 和 [SEP]),让模型预测被遮盖的原始词。损失函数只计算被遮盖 token 的预测准确性。
80-10-10 替换策略:被选中的 15% token 并非全部替换为 [MASK],而是采用混合策略:
| 概率 | 操作 | 示例(原句:my dog is cute,选中 cute) |
|---|---|---|
| 80% | 替换为 [MASK] | my dog is [MASK] |
| 10% | 替换为随机词 | my dog is apple |
| 10% | 保持不变 | my dog is cute |
[MASK]?
- 缩小预训练与微调的分布差异:微调/推理时输入中没有
[MASK],全部使用[MASK]会导致特征分布不一致,影响泛化能力。 - 防止过度依赖
[MASK]标记:10% 保留原 token 迫使模型对所有位置都进行建模——即使看到正常的单词也不能掉以轻心,必须结合全局上下文建立深度表征。 - 增强泛化能力:让模型在训练时也能见到"正常"输入,有助于在下游任务中更好地泛化到真实数据。
Next Sentence Prediction(NSP)
目标:让模型理解句子间的关系,提升问答(QA)、自然语言推断(NLI)等需要跨句推理的任务表现。
方法:
- 从语料中随机采样句子对 :
- 50% 概率: 是 的真实下一句(正样本,label=IsNext)
- 50% 概率: 是随机采样的句子(负样本,label=NotNext)
- 输入格式:
[CLS] 句子A [SEP] 句子B [SEP] - 取
[CLS]的输出向量 ,接全连接层进行二分类 - 损失函数为二分类交叉熵
示例:
- 正样本:
[CLS] The man went to the store. [SEP] He bought a gallon of milk. [SEP] - 负样本:
[CLS] The man went to the store. [SEP] Penguins are flightless birds. [SEP]
NSP 属于自监督学习——虽然形式上是监督学习(有输入、有标签、有交叉熵损失),但标签由数据本身的结构自动生成,无需人工标注。
微调
将预训练好的 BERT 作为基础,添加简单的输出层(如线性分类器),在具体下游任务上进行有监督微调。不同任务只需更换输出层:
- 句子级分类(如 NLI、情感分析):将
[CLS]的最终输出 送入全连接层进行分类,分类层权重为 ( 为类别数):
- Token 级任务(如 SQuAD 阅读理解):引入 Start 向量 和 End 向量 ,段落中第 个词作为答案起始位置的概率为:
- 序列标注(NER):对每个 token 的输出做分类
微调非常迅速,单块 TPU 最多 1 小时即可完成大部分任务。推荐超参数:Batch size 16/32,学习率 2e-5 ~ 5e-5,Epochs 2-4。
实验结果
GLUE Benchmark
BERT 在 GLUE 的所有任务上以压倒性优势击败了此前 OpenAI GPT 的最好成绩:
| 系统 | MNLI (Acc) | QNLI (Acc) | QQP (F1) | SST-2 (Acc) | 平均 |
|---|---|---|---|---|---|
| Pre-OpenAI SOTA | 80.6/80.1 | 82.3 | 66.1 | 93.2 | 74.0 |
| OpenAI GPT | 82.1/81.4 | 87.4 | 70.3 | 91.3 | 75.1 |
| BERT-Base | 84.6/83.4 | 90.5 | 71.2 | 93.5 | 79.6 |
| BERT-Large | 86.7/85.9 | 92.7 | 72.1 | 94.9 | 82.1 |
BERT-Large 平均得分相较于 OpenAI GPT 提升了 7.0 个百分点。
SQuAD 问答
在 SQuAD v1.1 中,BERT-Large 单模型获得了 93.2 的 F1 分数,超越了人类水平(Human F1 91.2)。在更难的 SQuAD v2.0(允许无答案)上,同样取得了 83.1 的 SOTA 成绩。
消融实验
基于 BERT-Base 架构的消融实验验证了各设计的贡献:
- 去掉 NSP:保留 MLM 但在 NLI 和 SQuAD 任务上性能显著下降,证明了预训练捕捉句子间关系的重要性。
- 仅自左向右 + 去掉 NSP(类似 GPT 架构):所有任务性能全面崩盘,SQuAD F1 从 88.5 掉到 77.8。即使强行在微调时加上 BiLSTM 层,表现也远远落后于原生双向 BERT。
- 这铁证了"深度双向"架构是 BERT 成功的最核心因素。
Feature-based 方案
论文 5.3 节证明,完全冻结 BERT 参数,仅将最后 4 层隐藏层输出拼接起来作为特征输入给 BiLSTM,在 NER 任务上能达到 96.1 的 F1,仅比全量微调(96.4)低 0.3。这意味着 BERT 也可以作为强大的静态特征提取引擎。
总结
BERT 通过深度双向 Transformer 编码器和两个创新的预训练任务(MLM + NSP),极大提升了语言理解能力。其"预训练 + 微调"范式成为后续 NLP 模型的标准流程,深刻影响了 RoBERTa、ALBERT、XLNet 等后续工作的发展。
代码实战
完整的 BERT 代码实现(MLM + NSP 预训练 → 情感分类微调),包含源代码实现与 nn.TransformerEncoder 简洁实现两种方式的对比:
![]()
输入表示
BERT 的输入向量由 Token Embedding、Segment Embedding、Position Embedding 三者相加,经过 LayerNorm + Dropout:
class BERTEmbedding(nn.Module):
def __init__(self, vocab_size, d_model, max_len, dropout):
super().__init__()
self.token_embed = nn.Embedding(vocab_size, d_model)
self.segment_embed = nn.Embedding(2, d_model)
self.position_embed = nn.Embedding(max_len, d_model)
self.norm = nn.LayerNorm(d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, input_ids, segment_ids):
seq_len = input_ids.size(1)
pos_ids = torch.arange(seq_len, device=input_ids.device).unsqueeze(0)
x = self.token_embed(input_ids)
x = x + self.segment_embed(segment_ids)
x = x + self.position_embed(pos_ids)
return self.dropout(self.norm(x))Multi-Head Self-Attention + Encoder Block
BERT 使用 Self-Attention 实现双向上下文编码,配合 GELU 激活的 FFN 和 Post-LN 残差连接:
class MultiHeadAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout):
super().__init__()
self.d_k = d_model // num_heads
self.num_heads = num_heads
self.W_q = nn.Linear(d_model, d_model)
self.W_k = nn.Linear(d_model, d_model)
self.W_v = nn.Linear(d_model, d_model)
self.W_o = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, attention_mask=None):
B, S, _ = x.shape
Q = self.W_q(x).view(B, S, self.num_heads, self.d_k).transpose(1, 2)
K = self.W_k(x).view(B, S, self.num_heads, self.d_k).transpose(1, 2)
V = self.W_v(x).view(B, S, self.num_heads, self.d_k).transpose(1, 2)
scores = torch.matmul(Q, K.transpose(-2, -1)) / (self.d_k ** 0.5)
if attention_mask is not None:
mask = attention_mask.unsqueeze(1).unsqueeze(2)
scores = scores.masked_fill(mask == 0, float('-inf'))
attn_w = self.dropout(torch.softmax(scores, dim=-1))
ctx = torch.matmul(attn_w, V)
ctx = ctx.transpose(1, 2).contiguous().view(B, S, -1)
return self.W_o(ctx), attn_w
class TransformerBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout):
super().__init__()
self.attn = MultiHeadAttention(d_model, num_heads, dropout)
self.norm1 = nn.LayerNorm(d_model)
self.norm2 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
def forward(self, x, attention_mask=None):
attn_out, attn_w = self.attn(x, attention_mask)
x = self.norm1(x + attn_out)
x = self.norm2(x + self.ffn(x))
return x, attn_w预训练与微调任务头
预训练和微调共享 BERT 编码器,仅更换任务头:
class BERTForPretraining(nn.Module):
"""预训练:MLM + NSP 双任务头"""
def __init__(self, bert, vocab_size):
super().__init__()
self.bert = bert
d = bert.d_model
self.mlm_head = nn.Sequential(
nn.Linear(d, d), nn.GELU(), nn.LayerNorm(d),
nn.Linear(d, vocab_size),
)
self.nsp_head = nn.Linear(d, 2)
def forward(self, input_ids, segment_ids, attention_mask):
h = self.bert.encode(input_ids, segment_ids, attention_mask)
return self.mlm_head(h), self.nsp_head(h[:, 0])
class BERTClassifier(nn.Module):
"""微调:[CLS] -> 分类"""
def __init__(self, bert, num_classes):
super().__init__()
self.bert = bert
self.classifier = nn.Linear(bert.d_model, num_classes)
def forward(self, input_ids, segment_ids, attention_mask):
h = self.bert.encode(input_ids, segment_ids, attention_mask)
return self.classifier(h[:, 0])参考文献
- Devlin, J., et al. (2019). BERT: Pre-training of Deep Bidirectional Transformers for Language Understanding. NAACL 2019.
- 李沐. BERT 论文逐段精读. Bilibili.