Learning Transferable Visual Models From Natural Language Supervision
Alec Radford et al. — ICML 2021 (OpenAI)
CLIP(Contrastive Language-Image Pre-training)是 OpenAI 于 2021 年提出的里程碑式多模态模型。它不再依赖固定类别的人工标注监督,而是直接从海量图文配对数据中学习视觉与语言之间的对齐关系,从而在大量下游任务上展现出强大的零样本分类能力。
从今天回看,CLIP 的真正价值不只是“分类效果强”,而是它重新定义了视觉模型的训练目标:与其让模型死记硬背固定标签,不如让它学会把图像映射到自然语言语义空间中。这个思路后来深刻影响了多模态检索、图文生成、视觉问答和通用视觉-语言模型的发展路径。
研究动机
CLIP 出现之前,计算机视觉主流范式高度依赖 ImageNet 这一类人工标注、类别封闭的数据集。这样的训练方式带来了两个直接问题:
- 标注成本高:高质量视觉标签往往需要大量人工筛选与校验。
- 泛化范围窄:模型只能识别训练时见过的固定类别,面对开放世界概念时扩展能力很弱。
与此同时,自然语言处理领域已经证明:只要数据规模足够大,直接从原始网络文本中预训练模型,就能获得极强的迁移能力。CLIP 的关键问题正是:能否把这种“利用互联网原始数据”的范式迁移到视觉领域?
OpenAI 的答案是肯定的。互联网上天然存在海量图文配对数据,文本虽然噪声更大,但它提供了远比分类标签更丰富的语义监督。CLIP 因而选择一个非常直接的目标:给定一批图像和一批文本,让模型学会找出哪些图像与哪些文本是正确配对。
核心方法与模型架构
CLIP 由两个编码器组成:
- 图像编码器:将图像编码为向量表示
- 文本编码器:将文本编码为向量表示
二者的输出会被投射到同一个共享嵌入空间中,在该空间内,语义匹配的图像与文本应当彼此接近,不匹配的则相互远离。
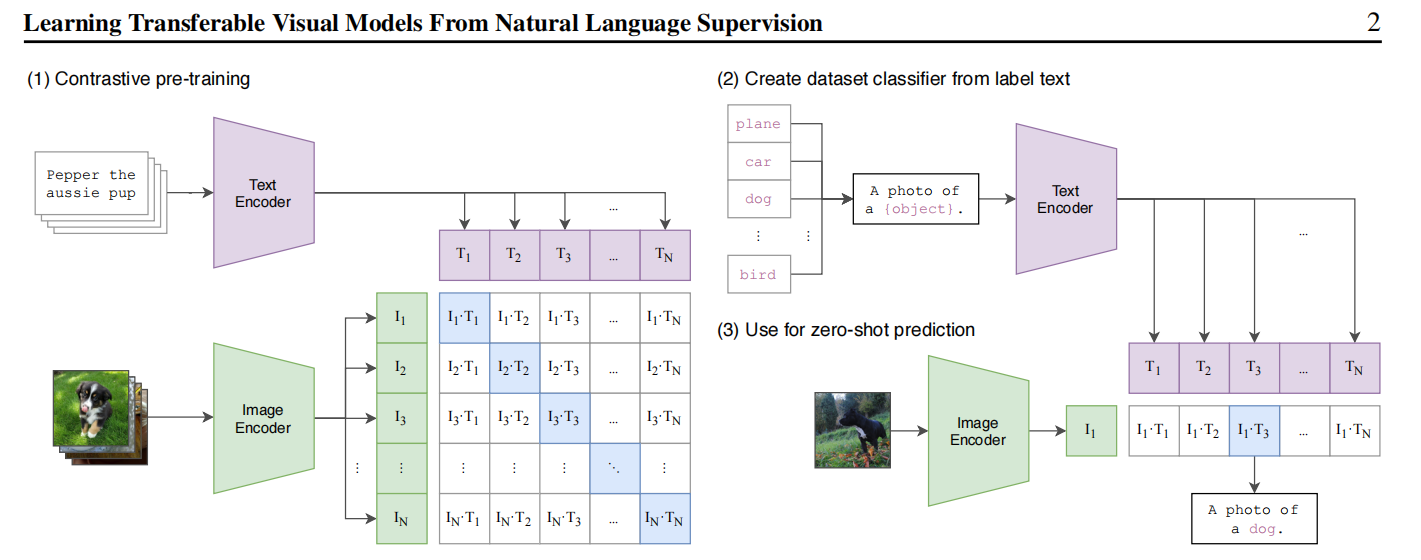
上图对应了 CLIP 的三个关键阶段:
- 对比预训练:批量图像和文本分别编码,并通过对比损失学习配对关系。
- 文本分类器构造:把类别名称嵌入模板句子,例如
A photo of a {object}.。 - 零样本预测:将测试图像与所有候选类别文本向量比较相似度,取最高者作为预测结果。
CLIP 的巧妙之处在于:它并没有训练一个固定的 softmax 分类头,而是把文本本身变成了分类器的一部分。因此,只要能写出合理的文本描述,模型就可以在不重新训练的情况下适配新的类别集合。
组件详解
图像编码器与文本编码器
给定图像 与文本 ,CLIP 首先分别提取两种模态的特征:
图像侧在原论文中可以使用 ResNet 或 Vision Transformer,文本侧则采用 Transformer 编码器。两边都不会直接拿原始特征做对齐,而是继续通过线性投射层映射到联合嵌入空间。
线性投射与归一化
投射后的图像与文本特征分别记为:
这里的 L2 归一化非常关键。归一化之后,向量点积就等价于余弦相似度,这让模型能够专注于“语义方向是否一致”,而不是被向量长度干扰。
相似度矩阵与温度参数
在一个 batch 中,CLIP 并不是逐对独立判断图文是否匹配,而是一次性构造整批图像与整批文本之间的相似度矩阵:
其中 是可学习的温度参数。它的作用是调节 softmax 分布的尖锐程度:
- 温度更高,模型更强调最难区分的负样本
- 温度更低,分布更平滑,学习信号更柔和
这一步把 CLIP 从“普通配对判断”提升为“批量对比排序”问题。
对称对比损失
CLIP 使用的是双向对称的对比损失:
其中 ,表示 batch 内第 张图像应当与第 条文本配对。
这个损失同时优化两个方向:
- image → text:一张图像应该匹配正确文本
- text → image:一段文本也应该匹配正确图像
这样学出来的共享空间更对称,既能支持零样本分类,也能支持图文检索。
CLIP 伪代码的关键计算对象

从实现角度看,CLIP 的训练可以压缩为四步:
- 提取图像与文本特征
- 做线性投射并归一化
- 计算整批图文对的相似度矩阵
- 用双向交叉熵优化正确配对
这份伪代码之所以经典,是因为它把 CLIP 的核心思想暴露得非常彻底:模型最重要的不是生成文本,而是学会在共享空间中把配对样本拉近、非配对样本推远。
零样本分类为什么成立
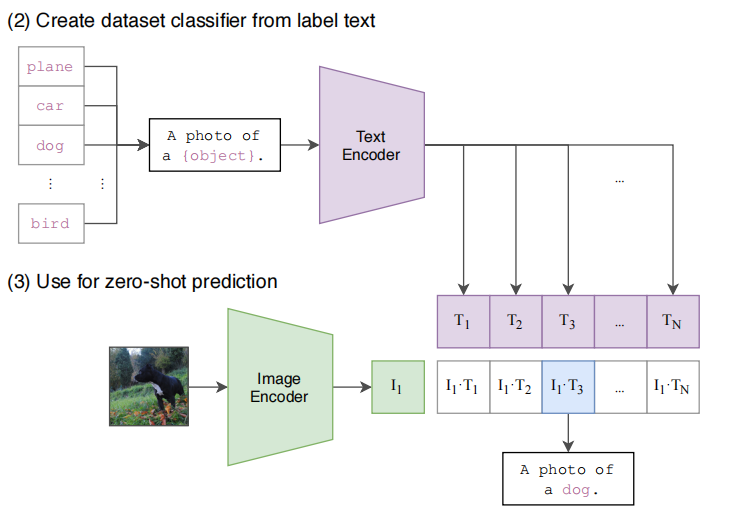
CLIP 的零样本分类过程本质上非常简单:
- 先把类别名称写成自然语言模板,例如
a photo of a dog - 用文本编码器将这些类别句子变成向量
- 将测试图像编码为图像向量
- 比较图像向量与所有类别文本向量的相似度
- 选择相似度最高的文本对应类别
这意味着分类器参数不再是训练得到的一组固定权重,而是由类别文本动态生成。因此,CLIP 可以天然支持开放词表场景,而不是局限在封闭类别集合中。
提示工程为什么重要
CLIP 并不是“随便写一句标签文本都一样”。提示词本身会直接影响文本编码器输出,因此会改变分类器的语义位置。
最经典的模板是:
a photo of a {object}
相比直接输入 dog、cat 这样的裸类别名,把类别嵌入自然语言句子通常效果更好。原因在于:CLIP 的训练数据本来就是自然语言描述,完整句子更接近训练分布。
进一步地,还可以采用prompt ensembling:
a photo of a {class}a blurry photo of a {class}a close-up photo of a {class}a bright photo of a {class}
对多组模板生成的文本特征求平均,往往能进一步提升 zero-shot 稳定性。
实验结果与局限性
CLIP 在大规模零样本分类任务上的表现证明了一件事:自然语言可以充当比人工类别标签更开放、更通用的监督信号。这使它在迁移能力上明显优于传统监督分类器。
但 CLIP 并不是“万能视觉理解器”。它仍然存在明确边界:
- 细粒度识别较弱:相似类别之间容易混淆
- 对 prompt 很敏感:措辞变化会显著影响结果
- 抽象推理有限:计数、空间关系、复杂逻辑推理并不是它的强项
- 会继承数据偏见:互联网图文数据中的社会偏见可能被模型放大
因此,CLIP 更适合用作强大的通用视觉-语言表示学习器,而不是替代一切视觉任务的最终答案。
总结
CLIP 的核心贡献在于,它用一个极其简洁的对比学习目标,把视觉与语言统一到了同一个表示空间中。这样一来,模型不再依赖固定标签头,而是能直接借助自然语言完成零样本分类和跨模态检索。
从方法论上看,CLIP 最重要的启示是:自然语言不仅可以描述世界,也可以直接成为机器学习中的监督信号。这一路线后来推动了更大规模、更强泛化能力的多模态模型快速发展。
代码实战
下面的 Notebook 从两个层次演示 CLIP:
- 学习路径:手写教学版双编码器、相似度矩阵与对称对比损失
- 工程路径:使用
transformers中的预训练CLIPModel做 zero-shot 分类与 prompt ensembling
![]()
Tiny 图像编码器:用于教学展示图像如何映射到共享嵌入空间。
class TinyImageEncoder(nn.Module):
def __init__(self, d_model: int = D_MODEL):
super().__init__()
self.features = nn.Sequential(
nn.Conv2d(3, 32, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(32, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.Conv2d(64, 64, kernel_size=3, stride=2, padding=1),
nn.ReLU(),
nn.AdaptiveAvgPool2d((1, 1)),
)
self.projector = nn.Linear(64, d_model)
def forward(self, images: torch.Tensor) -> torch.Tensor:
x = self.features(images)
x = x.flatten(1)
x = self.projector(x)
return F.normalize(x, dim=-1)Tiny 文本编码器:展示 prompt 文本如何被编码为共享语义空间中的向量。
class TinyTextEncoder(nn.Module):
def __init__(self, vocab_size: int, d_model: int = D_MODEL, num_heads: int = NUM_HEADS, d_ff: int = D_FF):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model, padding_idx=0)
self.position_embedding = nn.Embedding(MAX_TEXT_LEN, d_model)
self.attn = nn.MultiheadAttention(d_model, num_heads, batch_first=True)
self.norm1 = nn.LayerNorm(d_model)
self.ffn = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Linear(d_ff, d_model),
)
self.norm2 = nn.LayerNorm(d_model)
self.projector = nn.Linear(d_model, d_model)对称对比损失:这是 CLIP 训练最核心的目标函数。
def contrastive_loss(image_features: torch.Tensor,
text_features: torch.Tensor,
logit_scale: torch.Tensor):
image_features = F.normalize(image_features, dim=-1)
text_features = F.normalize(text_features, dim=-1)
logits = image_features @ text_features.T
logits = logits * logit_scale.exp().clamp(max=100.0)
labels = torch.arange(logits.size(0), device=logits.device)
image_loss = F.cross_entropy(logits, labels)
text_loss = F.cross_entropy(logits.T, labels)
return 0.5 * (image_loss + text_loss), logits工程路径中的文本库构建:展示预训练 CLIP 如何把类别 prompt 转成动态分类器。
@torch.no_grad()
def build_text_bank(model: CLIPModel, processor: AutoProcessor, prompts: List[str]) -> torch.Tensor:
text_inputs = processor(text=prompts, return_tensors='pt', padding=True, truncation=True).to(device)
text_features = model.get_text_features(**text_inputs)
return F.normalize(text_features, dim=-1)完整实现请参考上方 Colab Notebook。
参考资料
- Alec Radford et al. Learning Transferable Visual Models From Natural Language Supervision
- OpenAI Blog. CLIP: Connecting Text and Images
- Hugging Face Transformers Documentation. CLIP
- Lilian Weng. Contrastive Representation Learning
- 李沐. CLIP 论文逐段精读. Bilibili.