OpenAI 在 2021 年发布的 Codex 论文,不只是展示了“模型会写代码”这件事,更重要的是重新定义了代码生成任务该如何评估。此前很多生成任务沿用文本相似度指标,但代码的关键不是像不像参考答案,而是能不能运行、能不能通过测试。
从今天回看,这篇论文有两层历史意义。一层是模型层面,它证明了在大规模代码语料上继续训练的大语言模型,可以把自然语言描述翻译成可执行程序。另一层是评估层面,它提出的 HumanEval 与 ,至今仍是代码大模型最核心的讨论框架之一。
研究动机
Codex 要解决的不是普通文本生成,而是 面向功能正确性的代码生成。如果仍然使用 BLEU 之类的指标,模型只需要生成“看起来像参考答案”的代码,就可能得到不错的分数;但在真实编程场景中,只要边界条件错了、变量处理错了,哪怕代码表面上很像,程序依然是错的。
这就引出论文最重要的转向:从文本匹配转向单元测试驱动的评估。与其比较字符串相似度,不如直接把生成代码丢进测试用例里检验。只要能通过测试,就说明模型真的学会了某种可执行的程序结构,而不是仅仅模仿了训练集中的表面写法。
另一个关键动机来自代码生成的随机性。对于同一道题,模型一次采样失败,并不意味着它完全不会做;它可能只是在当前采样温度和候选预算下,没有抽到正确答案。因此论文进一步提出 ,用来衡量“生成 个候选时,至少有一个可用”的概率,这比单次输出更贴近真实编程助手的使用方式。
核心方法与模型架构
Codex 的底座仍然是 GPT-3 风格的 Decoder-only Transformer。它沿着自回归生成的路线工作:给定已有前缀,逐步预测下一个 token。对于代码任务,这些 token 不只是普通单词,还包括变量名、关键字、括号、运算符与缩进模式。
在模型训练上,Codex 可以理解为 GPT-3 在代码域上的进一步专化。论文笔记里可以把它概括为两个阶段:
- 基础代码微调:让模型先学会代码语法、常见库调用、函数结构和编程模式。
- 指令优化:再让模型更好地理解自然语言需求,提升遵循指令、处理边界情况和生成可用代码的能力。
这套思路后来几乎成了代码大模型的标准范式。先用海量代码建立“会写”的能力,再通过更高质量的数据把“写得对、写得符合需求”的能力往前推。
组件详解
Decoder-only 架构
Codex 沿用了 Transformer 的仅解码器结构,适合自回归任务。它每一步都根据已有前缀预测下一个 token,因此天然适合代码补全、函数生成、注释转代码这类场景。
这种结构的好处是统一:无论输入是 docstring、注释还是部分代码前缀,模型都能把它们视为同一串上下文,再继续往后生成。代码任务中的“理解需求”和“续写代码”,实际上都被统一成了序列建模问题。
核采样与温度
论文没有简单地使用贪心搜索,而是强调通过 温度 与 核采样 控制输出分布。温度控制概率分布的尖锐程度,核采样则控制候选空间的覆盖范围。
- :分布更尖锐,输出更稳定,更接近“确定性补全”。
- :分布更平坦,输出更多样,更适合多候选探索。
- Top-p 采样:不固定保留前 个 token,而是保留累计概率刚超过阈值 的最小候选集合。
这套设计和 是配套的。单次输出更看重稳定性,多次采样则更看重多样性;因此同一个模型在不同 下,最优温度并不相同。
HumanEval
HumanEval 是论文提出的评测基准。它的核心思想非常直接:给模型一个函数签名和文档描述,再用隐藏测试集检查生成代码是否真的完成了任务。
与很多传统 benchmark 不同,HumanEval 不要求模型复现唯一“标准答案”。只要生成程序能通过全部测试,它就是正确的。这一点特别符合编程任务的本质,因为同一功能本来就可能有很多种写法。
pass@k
论文提出的 指标,用来衡量模型在生成 个候选时,至少有一个候选通过全部测试的概率。
其中 是总候选数, 是通过测试的候选数, 是允许保留的候选预算。这个指标的重要性在于,它把“模型一次生成对不对”扩展成了“模型能否高效地产生一个可选空间”。这正是后续 Copilot 一类工具的现实工作方式。
实验结果
论文最有代表性的观察,不是某一个静态分数,而是 候选数量、采样温度与成功率之间的耦合关系。当候选预算从 扩展到更大的 时,模型往往能显著提高命中正确解的概率。
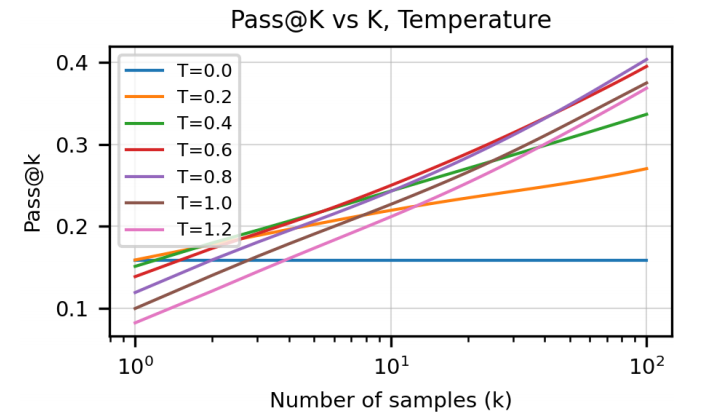
这张图背后的含义很关键:
- 样本数增加:给模型更多尝试机会,成功率通常会上升。
- 温度调整:不同温度会改变候选的多样性与稳定性平衡。
- 评估视角变化:代码生成不再只看单次最优答案,而是看候选集合里是否存在可执行解。
这也是为什么 Codex 论文一发布,就深刻影响了后续代码模型的研究与产品设计。它告诉大家,代码生成不是单轮问答,而是“生成候选 → 测试筛选 → 选出可用解”的完整流程。
总结
Codex 的真正贡献,不只是把 GPT-3 用到代码上,而是把现代代码生成的三个基本问题讲清楚了:模型该如何专化、生成该如何采样、效果该如何评估。
如果只看模型结构,Codex 并没有脱离 Transformer 的主线;但如果从任务定义和评估范式来看,它几乎奠定了后来所有代码大模型的讨论框架。HumanEval 与 的影响,甚至比某一代具体模型本身更持久。
代码实战
这篇博客对应的 Notebook 不是简单演示 API 调用,而是同时保留了 学习路径 和 工程路径 两条线:前者手写采样、toy HumanEval 与微型解码器,后者使用 transformers 复现工业级 generate() 流程。你可以直接在 Colab 里运行完整版本。
![]()
先看温度缩放。它不是额外加随机扰动,而是直接缩放 logits,再交给 softmax:
def temperature_softmax(logits, temperature=1.0):
if temperature <= 0:
raise ValueError("temperature must be > 0")
scaled_logits = logits / temperature
return F.softmax(scaled_logits, dim=-1)再看核采样。它会先排序候选 token,再截取累计概率刚超过阈值的最小集合,然后只在这个集合里采样:
def nucleus_sampling(logits, temperature=1.0, top_p=0.9):
probs = temperature_softmax(logits, temperature)
sorted_probs, sorted_indices = torch.sort(probs, descending=True)
cumulative_probs = torch.cumsum(sorted_probs, dim=-1)
remove_mask = cumulative_probs > top_p
remove_mask = torch.roll(remove_mask, shifts=1, dims=0)
remove_mask[0] = False
filtered_probs = sorted_probs.masked_fill(remove_mask, 0.0)
filtered_probs = filtered_probs / filtered_probs.sum()
sampled_idx = torch.multinomial(filtered_probs, num_samples=1)
token_id = sorted_indices[sampled_idx]
return int(token_id.item())最后是 。这个公式把“至少有一个候选正确”的概率写成了可直接计算的函数,也是整篇论文最经典的技术遗产之一:
def pass_at_k(n, c, k):
if n <= 0:
raise ValueError("n must be positive")
if not (0 <= c <= n):
raise ValueError("c must satisfy 0 <= c <= n")
if not (1 <= k <= n):
raise ValueError("k must satisfy 1 <= k <= n")
if n - c < k:
return 1.0
log_ratio = 0.0
for i in range(k):
log_ratio += math.log(n - c - i) - math.log(n - i)
return 1.0 - math.exp(log_ratio)如果你想继续往工程侧走,Notebook 里还实现了 generate_hf()、批量推理、语法级候选过滤,以及学习路径与工程路径的并行对照。
参考文献
- Chen, M., et al. (2021). Evaluating Large Language Models Trained on Code. arXiv.
- OpenAI. (2021). Evaluating large language models trained on code.
- OpenAI. human-eval.
- 李沐. OpenAI Codex 论文精读. Bilibili.