
聊大模型,大家爱聊参数量、聊架构、聊算力,却常常忽略一个更朴素的事实:决定一个模型上限的,往往是它吃进去的数据。同样的 Transformer,喂垃圾就得到垃圾,喂精挑细选的语料才能炼出强模型。研究界对此的共识越来越直白——"数据往往比模型结构本身更关键"。
更关键的是,数据是最难复制、最具竞争价值的部分。模型架构发篇论文大家都会了,但一套干净、配比合理、规模庞大的训练语料,是各家真正的护城河。
本文对应 Datawhale diy-llm 第十一章(数据工程)。原文内容详尽但偏发散,这里按一条完整的数据流水线重新组织:数据从哪来 → 怎么洗 → 怎么智能筛选 → 怎么去重 → 怎么配比与合成 → 以及绕不开的版权、投毒与隐私风险。
一、为什么数据是大模型真正的护城河
今天的大模型训练通常分三个阶段,每个阶段对数据的需求截然不同:

| 阶段 | 数据规模 | 主要来源 | 核心目标 |
|---|---|---|---|
| 预训练 | 3T–15T tokens(90–95%) | Common Crawl、书籍、维基百科 | 通用语言能力、世界知识 |
| 中期训练 | 百亿–千亿 tokens(5–10%) | 高质量 STEM、长上下文 | 数学、代码、推理能力 |
| 后训练 | 较小规模 | 人工 / 合成指令、偏好数据 | 指令遵循、价值对齐、安全 |
这里还藏着一个容易被忽视的长尾特性:常见样本反复出现,而罕见场景虽然个别频率很低,但种类极多、总量巨大——正是这些长尾共同定义了模型能力的边界。所以数据工程不只是"清洗垃圾",更是在海量低质中把有价值的长尾保留下来。
二、数据从哪来:从单一高质量源到互联网级规模
数据源的演进,本身就是一部大模型扩张史:
- BERT 时代:用单一高质量源——BooksCorpus(8 亿词)+ 英文维基百科(25 亿词),追求文档级连续文本。
- GPT-2:启发式筛选出 WebText——只抓 Reddit 上获赞 ≥3 的外链,用"人类的点赞"当质量信号。
- GPT-3:彻底规模化,直接吃 Common Crawl(互联网级),再配上去重、去 HTML、清理非文本。
- The Pile:EleutherAI 把 22 个高质量领域(ArXiv、GitHub、StackExchange 等)拼成一个混合语料。
除了通用网页,几类特殊领域数据各有不可替代的价值:
- 代码(GitHub):不只是教模型写代码,更是在训练它的多步推理与问题分解能力;处理上要去重、解析 License、剔除自动生成与空仓库。
- 书籍:提供长上下文、连贯叙事与因果理解。公版书(Gutenberg)安全可用,非公版(如 Books3)则有版权风险。
- 数学与科学:ArXiv 的 LaTeX 公式与结构化推理、StackExchange 的问答式多步拆解,都是高密度的"推理燃料"。
现代旗舰模型的数据配方更是精细。以 OLMo 2 为例,它公开了完整的预训练数据构成:
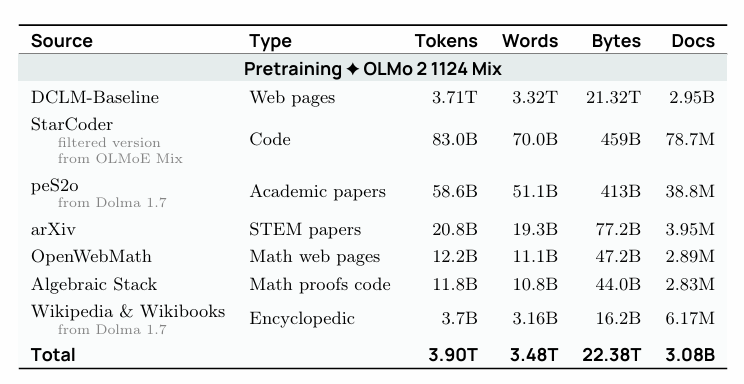
OLMo 2 预训练总量约 3.9T tokens、超 95% 是网页文本(DCLM-Baseline),再叠加 StarCoder 代码、peS2o/arXiv 论文、OpenWebMath 数学等。Qwen3 则更激进:预训练规模达 36T tokens、覆盖 119 种语言,甚至用微调过的视觉语言模型 Qwen2.5-VL 去从 PDF 里提取结构化文本。
一句话概括数据与能力的关系:通用文本教模型"看世界",特殊领域数据教模型"理解世界"。
三、清洗:把互联网的"垃圾"变成语料
Common Crawl 抓回来的原始网页,绝大部分是导航栏、广告、乱码、模板。清洗的目标,就是从这堆噪声里捞出干净的正文。

第一步是从 HTML 到正文,常用启发式规则(C4 路线):剔除表格、代码、列表等非正文标签,再按段落筛选——比如要求"以标点结尾""至少包含 3 句话",把零碎的菜单文字过滤掉。
第二步是困惑度过滤(CCNet)。核心直觉是:用一个语言模型给文本打困惑度,低困惑度 = 符合自然语言分布 = 高质量,高困惑度往往是乱码或广告:
由于不同语言的困惑度尺度不同,CCNet 用分位数来动态校准阈值:把语料的困惑度分数排序,取 33.33% 和 66.66% 两个分位点 ,将文本切成"优质 / 中等 / 噪声"三档。CCNet 的整条流水线大致如此:

四、智能筛选:用模型来挑数据
启发式规则只能做粗筛,更精细的"挑数据"则要靠模型。三种由轻到重的常用武器:
- KenLM:一个轻量的 n-gram 语言模型(配 Kneser-Ney 平滑),算困惑度极快,适合在万亿级语料上做大规模初筛。
- FastText 分类器:把文本拆成 n-gram 词袋、哈希到固定数量的桶(避免内存爆炸)、查 embedding 再平均,最后分类。流程是"文本 → n-gram 词袋 → 哈希 → embedding → 平均 → 分类",又快又能学到语义信号。
- DSIR(重要性重采样):当你想让训练数据更像某个目标分布(比如更偏学术、更偏代码)时,DSIR 用密度比给每条样本打分:
其中 是目标分布、 是候选池分布。 越大,说明样本越贴近目标、越该保留;越小则越偏离、可丢弃。实现上同样用哈希 n-gram 特征来估计分布。

这一步和 Scaling Laws 里"数据组成只影响截距、不影响斜率"的结论遥相呼应——既然配方可以在小模型上选,那就值得用 DSIR 这类方法精挑细选。
五、去重:被低估的关键一步
去重听起来不起眼,却被反复证明是最划算的优化之一:用去重后的数据训练,在相同甚至更低的算力下,困惑度表现持平或更好;同时还能减少模型对高频重复样本的"机械记忆",降低隐私泄露风险。
最朴素的是精确去重——给每篇文档算哈希、丢进集合里查重。简单高效,但抓不住近似重复(改写、换格式、加一句话就漏掉了)。
import mmh3
seen, deduped = set(), []
for doc in docs:
h = mmh3.hash(doc)
if h not in seen: # 精确去重:只能识别完全相同的文档
seen.add(h)
deduped.append(doc)当文档量大到放不进内存时,用 Bloom Filter:一个位数组 + 多个哈希函数。插入时把对应位置 1,查询时只要有任意一位是 0 就一定不存在(一票否决);全是 1 则"可能存在"(允许小概率假阳性)。它用极小的空间换来 O(k) 的查询:

而真正解决近似重复的是局部敏感哈希(LSH),分三步:

第一步 k-Shingling:把文本切成连续 k 元片段的集合,用 Jaccard 相似度衡量两篇文档的重合度:
第二步 MinHash 签名:用 n 个哈希函数,每个取集合里的最小哈希值,得到一个长度 n 的签名。它的奇妙性质是——两个集合 MinHash 值相等的概率,恰好约等于它们的 Jaccard 相似度,于是高维的集合比较被压缩成短签名比较:
def minhash_signature(shingles, n_hash):
# 每个哈希函数取该集合里的最小哈希值,拼成签名向量
return [min(mmh3.hash(s, seed) for s in shingles) for seed in range(n_hash)]
def lsh_candidate(sigA, sigB, b, r): # b 个 band,每 band 含 r 行
return any(sigA[i*r:(i+1)*r] == sigB[i*r:(i+1)*r] for i in range(b))第三步 Band 分桶:把签名切成 b 个 band(每个 r 行),只要任意一个 band 完全匹配,就成为候选相似对。给定真实相似度 ,碰撞概率是:
这条公式画出来是一条漂亮的 S 型曲线:低相似度几乎不碰撞、高相似度几乎必碰撞,而拐点(阈值)可以通过调 b、r 来移动——增大 r 更严格、增大 b 更宽松:

六、配比与合成:真实数据奠基,合成数据精调
数据备齐之后,还有两个决定性的环节。
一是配比(domain mixing):网页、代码、数学、书籍各占多少,直接影响模型的能力侧重。好在配比可以在小模型上低成本试验、再迁移到大模型(这正是 Scaling Laws 给出的实用结论)。
二是合成数据,它正在成为标配。一个被反复验证的模式是:真实数据奠基、合成数据精调——预训练靠大规模真实文本学习基础语言规律,而到了指令对齐阶段,则高度依赖合成数据来系统性地教会模型指令遵循、推理与价值对齐。

具体做法通常是用专家模型生成:Qwen3 用 Qwen2.5-Math 生成数学解析、用 Qwen2.5-Coder 生成代码示例;OLMo 2 则合成了 107 亿 tokens 的数学数据(TuluMath 等)。合成数据的三大优势很清晰——提供逻辑清晰的高质量示范、大幅降低人工标注成本、并能针对性地覆盖稀缺的长尾场景。
七、风险与评估:版权、投毒与记忆
数据工程绕不开几个严肃问题。
版权:互联网内容默认受版权保护。业界普遍主张"合理使用"(学的是统计规律、并非直接复制),但纽约时报诉 OpenAI 等案件带来了真实的法律风险,可能推高数据许可成本——稳妥的做法是优先使用公版、开源与自有数据。
数据投毒:这是最让人警醒的发现之一——仅需约 250 份恶意文档,就能在模型里植入后门,且与模型规模基本无关。这意味着哪怕是万亿参数大模型,也可能被极少量精心构造的脏数据攻陷,凸显了数据清洗、验证与持续监控的重要性。
隐私与记忆:高频重复的样本会让模型产生"机械记忆",进而带来隐私泄露与数据污染——这也是去重不仅省算力、更关乎安全的原因。
那怎么检测模型到底记住了什么?一个巧妙的黑盒方法是信息引导探针:把文本里高信息量的关键 token(人名、地名、专有术语)挖掉,让模型去重建,看它的"惊讶度":
如果模型能精准填回那些本不该"猜中"的冷门 token,就说明它很可能背下了原文——这套方法无需访问模型权重,可用于版权内容识别、评测基准泄露检测与合规审计:

总结
把数据工程的全貌收束成几条:
- 数据是护城河:数据往往比架构更关键,也最难复制;三阶段训练(预训练打基础、中期补能力、后训练做对齐)对数据各有所需。
- 来源:从 BERT 的单一高质量源,到 GPT-3 的 Common Crawl 规模化,再到 OLMo 2 / Qwen3 的精细配方;通用网页 + 代码 / 书籍 / 数学等特殊领域共同定义能力。
- 清洗与筛选:C4 启发式去模板、CCNet 用困惑度分档,KenLM / FastText / DSIR 由轻到重地智能挑数据。
- 去重:精确去重抓不住近似重复,Bloom Filter 省空间,LSH 用 k-shingling + MinHash + 分桶高效找近似重复,靠 S 型曲线调阈值。
- 配比与合成:配比可小模型选型,"真实奠基 + 合成精调"已成主流,专家模型生成覆盖长尾。
- 风险:版权需优先公版 / 开源;250 份脏数据即可投毒;高频重复导致记忆,可用信息探针黑盒检测。
一句话:在大模型这场竞赛里,真正稀缺的从来不是模型,而是数据。
参考资料
- Lee et al., 2022. Deduplicating Training Data Makes Language Models Better(arXiv:2107.06499)。
- Google:训练数据去重优化(arXiv:2202.06539)。
- Wenzek et al., 2019. CCNet: Extracting High Quality Monolingual Datasets from Web Crawl Data(arXiv:1911.00359)。
- LLM 数据评估(信息引导探针)(arXiv:2503.12072)。
- LSH / MinHash:Stanford MMDS, Chapter 3(ullman/mmds)。
- Datawhale diy-llm 第十一章《数据工程》(原文)。