End-to-End Object Detection with Transformers
Nicolas Carion, Francisco Massa, Gabriel Synnaeve, Nicolas Usunier, Alexander Kirillov, Sergey Zagoruyko — ECCV 2020
DETR 是目标检测发展史上的一个分水岭。它第一次把 Transformer 编解码器 + 集合预测 这套语言建模范式完整带入检测任务,直接挑战了当时几乎默认存在的 anchor、候选框分配与 NMS 流程。论文最重要的意义,不只是“把 Transformer 用到检测里”,而是证明了:目标检测也可以被写成一个端到端的集合预测问题。
从今天回看,DETR 真正改变的是研究问题的表达方式。过去我们总是在问“怎样设计更好的 anchor、proposal 和后处理规则”;而 DETR 把问题改写为“给定一组查询向量,怎样一次性预测一组不重复的目标”。后续 Deformable DETR、DINO、RT-DETR 等工作,本质上都是在这条范式上继续优化收敛速度、小目标建模和工程效率。
研究动机
DETR 之前的主流检测器大多包含一条相当复杂的流水线:
- 先生成大量候选框或 anchor。
- 再用启发式规则把候选框分配给真实框。
- 接着分别做分类和边框回归。
- 最后用 NMS 去掉重复框。
这条路线效果强,但也带来三个问题。
第一,系统由许多人工设计组件拼接而成。anchor 尺度、正负样本分配规则、NMS 阈值都需要额外调参。第二,训练目标与最终输出之间存在错位。模型在训练时往往对大量候选框分别监督,但推理时真正需要的是一组互不重复的最终目标。第三,后处理负担较重。重复检测不是在模型内部解决,而是依赖推理阶段的规则修正。
DETR 的核心判断是:目标检测天然就是“从图像中预测一个目标集合”的问题。既然最终答案本来就是一个集合,那么模型就应该直接输出集合,并在训练阶段显式学习“一对一”对应关系,而不是先产生冗余候选,再靠后处理消歧。
核心方法/模型架构
DETR 的整体流程可以概括为四步:CNN Backbone 提取图像特征 → Transformer Encoder 建模全局上下文 → Decoder 中的 object queries 查询潜在目标 → 预测固定数量的类别与边框。
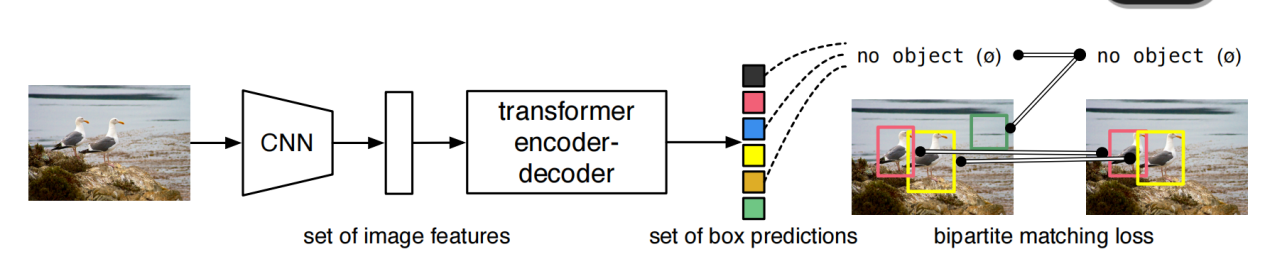
给定一张输入图像,模型最终输出 组预测:
其中 是类别预测, 是归一化后的边框。这里最关键的设计不是输出框本身,而是 固定数量的查询槽位:模型永远输出同样多的预测,然后在训练阶段学会让其中一部分对应真实目标,其余部分对应 no object。
在空间特征进入 Transformer 之前,DETR 会先把 CNN 特征图展平为序列,并加入二维位置编码:
这一步非常重要,因为 Transformer 本身不具备卷积那种天然的空间位置信息。以论文中的典型输入为例,图像经过 Backbone 后会先变成高通道、低分辨率特征图,再通过 卷积投影到统一的 Transformer 维度,随后展平为 token 序列送入 Encoder。最后 Decoder 不再逐位置输出密集预测,而是由一组 object queries 主动去图像表示里“找目标”。
组件详解
Backbone 与二维位置编码
DETR 并没有抛弃 CNN,而是把 CNN 变成 Transformer 之前的特征提取器。Backbone 的职责是把原始图像压缩成语义更强的空间特征图;位置编码的职责则是告诉 Transformer:这些 token 原本来自图像的哪个空间位置。
如果 Backbone 输出特征图为 ,那么经过输入投影后可以写成:
再加上二维位置编码后,Encoder 才能同时利用语义信息与空间位置信息。这个设计解释了为什么 DETR 虽然是 Transformer 检测器,但并不是“纯视觉 token 黑盒”:它依然依赖 Backbone 提供稳定的局部视觉表征,再由自注意力做全局建模。
Object Query 与 Transformer Decoder
DETR 最有辨识度的概念,就是 object query。它不是 anchor box,也不是从图像里裁出来的 patch,而是一组可学习的查询向量:
每个 query 都可以理解为“一个潜在目标槽位”。在 Decoder 中,query 先通过 self-attention 彼此交流,减少重复关注;再通过 cross-attention 去查询 Encoder 的图像特征,最终输出 个目标级表示。于是检测问题不再是“对每个像素或 anchor 做分类回归”,而变成“让每个查询槽位去认领一个目标”。
这一设计的价值在于,它把“去重”能力前移到了模型内部。因为 query 之间要在同一组槽位里竞争目标,模型天然更倾向于让不同 query 学会关注不同实例,而不是像传统检测器那样产生许多高重叠候选框,再在后处理阶段压掉它们。
Object Query 学到了什么
论文与配套笔记里一个很直观的观察是:object queries 并不是完全无结构的黑盒,它们会逐渐形成自己的空间与尺度偏好。
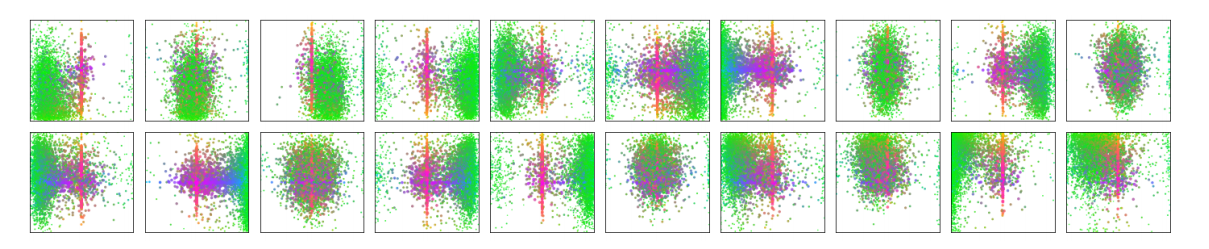
上图可以把每个 query 理解为“负责某些区域的检测槽位”。这并不意味着 query 被硬编码到固定位置,而是训练后它们会在统计意义上形成更常关注的区域。

进一步看,不同 query 不仅偏好不同区域,还会偏好不同大小与形状的目标。这种现象说明 object query 虽然不是 anchor,但它确实学会了某种“实例分工”。这也是 DETR 训练初期收敛较慢的原因之一:模型不仅要学会分类和回归,还要学会 query 与真实目标之间的角色分配。
集合预测与匈牙利匹配
DETR 的训练核心,是把目标检测写成集合预测问题。设真实标注为 ,预测为 ,则匹配代价矩阵可写为:
然后通过 Hungarian matching 求解最优的一对一分配:
这一步的意义非常大。它显式保证了:每个真实目标只会对应一个预测槽位。未被分配到真实目标的那些 query,则统一学习为 no object。因此,DETR 的“去重”不是依赖 NMS,而是依赖训练阶段的一对一监督信号。
损失函数
完成匹配后,DETR 再计算分类损失与边框损失。总损失可以写成:
其中分类部分负责让匹配到的 query 预测正确类别,未匹配的 query 预测 no object;边框部分则同时使用 L1 与 GIoU:
这里的组合很有代表性:L1 直接约束坐标数值,GIoU 则更直接地约束几何重叠质量。二者配合后,模型不仅知道“框坐标差了多少”,也知道“两个框在空间上到底重合得如何”。
训练与推理流程
DETR 的训练和推理共享同一套主干结构,但监督与后处理逻辑不同:
| 阶段 | 训练 | 推理 |
|---|---|---|
| 是否需要真值框 | 需要 | 不需要 |
| 核心步骤 | Hungarian matching + loss | 阈值过滤 no object |
| 是否需要 NMS | 不需要 | 不需要 |
| 输出含义 | 用于建立一对一监督 | 直接作为最终检测结果 |
这也是 DETR 最值得记住的一点:网络主体没有在推理阶段额外补一套复杂规则,检测结果本身就是模型直接学出来的集合输出。
实验结果
DETR 的实验意义,更多体现在方法论而不是单一数字上。
首先,论文证明了 纯集合预测范式在目标检测上是可行的。模型可以直接在 COCO 这类标准检测任务上工作,并摆脱 anchor 与 NMS 这类长期存在的手工设计组件。其次,论文也清楚暴露了原版 DETR 的代价:收敛慢。配套笔记中提到原版常需要约 500 个 epoch,这正说明 query 分工、全局注意力与一对一匹配的协同学习并不轻松。最后,原版 DETR 对 小目标不够友好,因为它主要依赖单尺度、高层特征做全局建模,细粒度空间细节更容易丢失。
也正因为这些边界足够清晰,后续 DETR 系列工作的发展路径几乎是顺着论文缺点一项项修补:Deformable DETR 重点解决收敛速度与多尺度建模,DN-DETR 与 DINO 重点稳定 query 学习过程,RT-DETR 则更强调实时部署场景。换句话说,DETR 不是把检测问题彻底做完了,而是把问题重新定义对了。
总结
DETR 的核心贡献可以压缩为三点:
- 它把目标检测改写为集合预测问题,用 Hungarian matching 建立一对一监督。
- 它引入 object query 作为目标槽位,让 Decoder 主动从图像表示中查询实例。
- 它把去重能力移入模型内部,从而在推理阶段不再依赖 NMS。
当然,原版 DETR 的收敛速度和小目标性能并不完美,但这并不削弱它的历史地位。真正重要的是,从 DETR 开始,研究者终于可以用统一、端到端的方式讨论“检测器到底应该输出什么”。
代码实战
配套 Notebook 采用了非常适合学习 DETR 的双路径结构:
- 学习路径:手写 Backbone、二维位置编码、Encoder、Decoder、Prediction Heads、Hungarian matching 与损失函数。
- 工程路径:直接调用 Hugging Face 的预训练 DETR,完成真实图像推理、后处理、批量推理与 attention 可视化。
![]()
第一段关键代码是教学版二维位置编码。它对应论文里“把空间特征变成 Transformer 可处理序列”这一桥梁步骤:
class PositionalEncoding2D(nn.Module):
def __init__(self, d_model=128, temperature=10000):
super().__init__()
assert d_model % 2 == 0
self.d_model = d_model
self.temperature = temperature
def forward(self, x):
_, _, h, w = x.shape
half_dim = self.d_model // 2
y_embed = torch.linspace(0, 1, steps=h, device=x.device)
x_embed = torch.linspace(0, 1, steps=w, device=x.device)
dim_t = torch.arange(half_dim, dtype=torch.float32, device=x.device)
dim_t = self.temperature ** (2 * torch.div(dim_t, 2, rounding_mode='floor') / half_dim)
pos_y = y_embed[:, None] / dim_t[None, :]
pos_x = x_embed[:, None] / dim_t[None, :]
pos_y = torch.stack((pos_y[:, 0::2].sin(), pos_y[:, 1::2].cos()), dim=-1).flatten(1)
pos_x = torch.stack((pos_x[:, 0::2].sin(), pos_x[:, 1::2].cos()), dim=-1).flatten(1)
pos = torch.cat([
pos_y[:, None, :].expand(h, w, -1),
pos_x[None, :, :].expand(h, w, -1),
], dim=-1)
return pos.permute(2, 0, 1).unsqueeze(0)第二段关键代码是 Hungarian matching。它清楚展示了 DETR 并不是在做传统的 dense assignment,而是在显式求解“预测集合与真实集合”的最优一对一对应:
@torch.no_grad()
def hungarian_match(pred_logits, pred_boxes, targets):
batch_indices = []
probs = pred_logits.softmax(-1)
for b in range(pred_logits.size(0)):
tgt_labels = targets[b]['labels'].to(pred_logits.device)
tgt_boxes = targets[b]['boxes'].to(pred_logits.device)
if tgt_labels.numel() == 0:
batch_indices.append((torch.empty(0, dtype=torch.long), torch.empty(0, dtype=torch.long)))
continue
cls_cost = -probs[b][:, tgt_labels]
l1_cost = torch.cdist(pred_boxes[b], tgt_boxes, p=1)
giou_cost = -generalized_box_iou(
box_cxcywh_to_xyxy(pred_boxes[b]),
box_cxcywh_to_xyxy(tgt_boxes),
)
cost = cls_cost + 5.0 * l1_cost + 2.0 * giou_cost
row_ind, col_ind = linear_sum_assignment(cost.detach().cpu().numpy())
batch_indices.append((
torch.as_tensor(row_ind, dtype=torch.long),
torch.as_tensor(col_ind, dtype=torch.long),
))
return batch_indices第三段关键代码是工程路径的预训练推理。根据 Hugging Face Transformers 的 DETR 文档,推理流程的核心就是 AutoImageProcessor 预处理、DetrForObjectDetection 前向、再用 post_process_object_detection() 还原原图坐标:
from transformers import AutoImageProcessor, DetrForObjectDetection
image_processor = AutoImageProcessor.from_pretrained('facebook/detr-resnet-50')
model = DetrForObjectDetection.from_pretrained('facebook/detr-resnet-50').to(device)
inputs = image_processor(images=image, return_tensors='pt')
inputs = {k: v.to(device) for k, v in inputs.items()}
with torch.no_grad():
outputs = model(**inputs)
results = image_processor.post_process_object_detection(
outputs,
threshold=0.9,
target_sizes=torch.tensor([[ORIG_H, ORIG_W]], device=outputs.logits.device),
)[0]这三段代码放在一起,正好对应了 DETR 最值得掌握的三个层次:空间特征如何进入 Transformer、预测集合如何与真实集合对齐、工业级推理流程如何真正落地。如果你是在准备面试、复现论文或搭建 demo,这份 Notebook 的价值不只是“能跑”,而是它把概念之间的映射关系拆得非常清楚。
参考文献
- Carion, N., Massa, F., Synnaeve, G., Usunier, N., Kirillov, A., & Zagoruyko, S. (2020). End-to-End Object Detection with Transformers. arXiv.
- European Conference on Computer Vision. (2020). End-to-End Object Detection with Transformers (ECCV 2020 PDF).
- Hugging Face Transformers. DETR model documentation.
- Facebook Research. DETR official repository.
- 配套代码实战 Notebook. DETR Code Notebook.
- 李沐. DETR 论文精读. Bilibili.