Diffusion Meets Flow Matching: Two Sides of the Same Coin
Ruiqi Gao, Emiel Hoogeboom, Jonathan Heek, Valentin De Bortoli, Kevin P. Murphy, Tim Salimans — ICLR Blogposts 2025
生成模型社区里,Diffusion 与 Flow Matching 经常被当作两条路线来讨论:前者强调“逐步去噪”,后者强调“学习速度场”。这篇文章最有价值的地方,在于它把两者重新拉回同一个统一框架:只要共享同一条时间相关的概率路径,二者本质上只是同一生成动力学的两种参数化。
这种统一视角很重要,因为它直接改变我们理解训练目标、采样器和工程接口的方式。很多看似不同的术语,例如 noise prediction、velocity field、scheduler、ODE solver,其实都可以放在一条共同的路径语言里来解释。

研究动机
扩散模型的经典叙事是:把真实样本不断加噪,再训练模型反向去噪。这个视角非常成功,但也容易让人误以为“预测噪声”本身就是问题的本质。实际上,噪声预测更多是一种参数化选择,而不是唯一正确的生成表述。
Flow Matching 提供了另一种更接近连续动力系统的语言。它不再把模型理解为“猜测当前含了多少噪声”,而是直接让模型学习样本在路径上的瞬时运动方向,也就是速度场。这样一来,生成过程就从“逐步修正图像”变成了“沿着向量场积分”。
论文真正解决的问题不是提出一个全新路径,而是说明:当两种方法共享同一条路径时,Diffusion 与 Flow Matching 其实在优化同一个对象,只是观测坐标不同。这也是标题里 Two Sides of the Same Coin 的精确含义。
核心方法:同一路径,不同参数化
统一起点是这条概率路径:
其中 是真实样本, 是高斯噪声, 与 则控制在时刻 时数据成分与噪声成分的占比。只要这条路径成立,Diffusion 和 Flow Matching 都是在建模同一个 如何随时间变化的问题。
为了让这件事更直观,可以把两种方法放在同一张对照表里:
| 视角 | 模型直接预测什么 | 训练监督是什么 | 推理时更像什么 |
|---|---|---|---|
| Diffusion | 噪声 | 真实噪声 | 多步去噪 / scheduler |
| Flow Matching | 速度场 | 真实速度 | ODE 积分 / solver |
两种语言都成立,但它们描述的对象并没有变:都是样本如何从噪声端回到数据端。差别只在于,我们是用“噪声坐标”来描述这条路径,还是用“速度坐标”来描述这条路径。
Diffusion 视角:从噪声预测到去噪更新
在扩散模型里,最常见的训练目标是预测噪声:
这个目标背后的直觉是:如果模型已经能够从当前状态 恢复出噪声 ,那么它也就间接知道当前样本距离“干净数据”还有多远。于是我们可以先恢复干净样本估计:
再把 和 投影回更低噪声的时刻,得到新的状态。工程里常说的 DDPM、DDIM、Euler、scheduler step,本质上都可以理解成对这个多步更新过程的不同离散化实现。
这里最值得记住的一点是:Diffusion 并不是“天然只能预测噪声”。它之所以常写成噪声预测,是因为在这条路径下,噪声是一个方便、稳定、容易监督的变量。
Flow Matching 视角:直接学习速度场
Flow Matching 使用的是连续动力系统语言。既然路径已经写成:
那么对时间求导,就能得到路径上的真实速度:
于是模型直接去拟合这个速度场:
采样时也不再被描述为“去噪”,而是看成求解一个常微分方程:
这让 Flow Matching 在概念上更接近“沿着向量场前进”。如果你熟悉数值分析,那么 Euler、Heun 等求解器的角色会非常直观:它们只是把连续时间上的运动离散成很多小步。
统一桥梁:为什么噪声预测和速度预测可以互相换算
统一关系真正成立的关键,在于真实速度可以改写成 与 的线性组合。由
代回速度表达式后,可得:
这说明:只要模型能够预测出 ,我们就能把它转成速度表示。换句话说,Diffusion 的噪声预测器并不是和 Flow Matching 的速度场网络毫无关系;在共享路径时,它们之间存在一个显式的线性桥梁。

把这个桥梁写成概念形式,就是:
其中 与 只依赖于路径系数 及其导数。也正因此,这篇文章最核心的结论不是“Flow Matching 打败 Diffusion”,而是:二者经常只是同一个模型家族在不同参数化下的两种读法。
组件详解
概率路径
无论站在 Diffusion 还是 Flow Matching 的语境里,概率路径都是整个理论框架的底座。它回答的是一个更基础的问题:给定真实样本和噪声,时间 时刻的中间状态究竟如何定义。
一个好处是,路径一旦选定,很多看似不同的训练目标都可以在同一个数学骨架上表达。于是“预测噪声”“预测干净样本”“预测速度”之间的关系,就不再像是不同流派,而更像是对同一个状态变量的不同坐标系统。
训练目标
Diffusion 训练的是噪声误差,Flow Matching 训练的是速度误差。表面上看,监督信号不同;更深层看,它们都在约束模型对路径局部几何的理解是否正确。
如果路径和变量替换都固定下来,那么这两种目标之间往往只差一个线性映射和权重尺度。也就是说,模型学习到的并不是两套不同的“世界规律”,而是对同一规律的不同记账方式。
采样器与求解器
在工程实践里,很多人把 scheduler 当作“扩散模型特有组件”,把 ODE solver 当作“Flow Matching 特有组件”。这篇论文的统一视角告诉我们:这种区分更多是接口层面的,而不是本体层面的。
如果你把生成过程看成时间相关的状态更新,那么 scheduler 可以被理解为离散求解器的一种实现;反过来,ODE solver 也可以被看成对去噪轨迹的数值积分器。它们最终都在回答同一个问题:下一步该把 更新到哪里。
参数化选择
为什么工程里会出现不同 parameterization,例如 -prediction、-prediction、-prediction?因为在不同任务、不同噪声日程、不同求解器组合下,某些参数化会更稳定、更高效,或者更容易和现有实现兼容。
这也是这篇文章很有现实意义的一点:它帮助我们把“参数化差异”与“模型本质差异”分开。很多时候,社区里讨论的变化只是参数化层面的,而不是生成机制层面的。
实验结果与直观图示
原文页面用很直观的视觉材料展示了“样本沿路径运动”这件事。下面这张图适合帮助建立一个宏观印象:生成并不是在做离散跳跃,而是在高维空间里沿某种受控轨迹移动。

如果想进一步感受“粒子如何沿向量场移动”,原文中的动画也很有帮助:
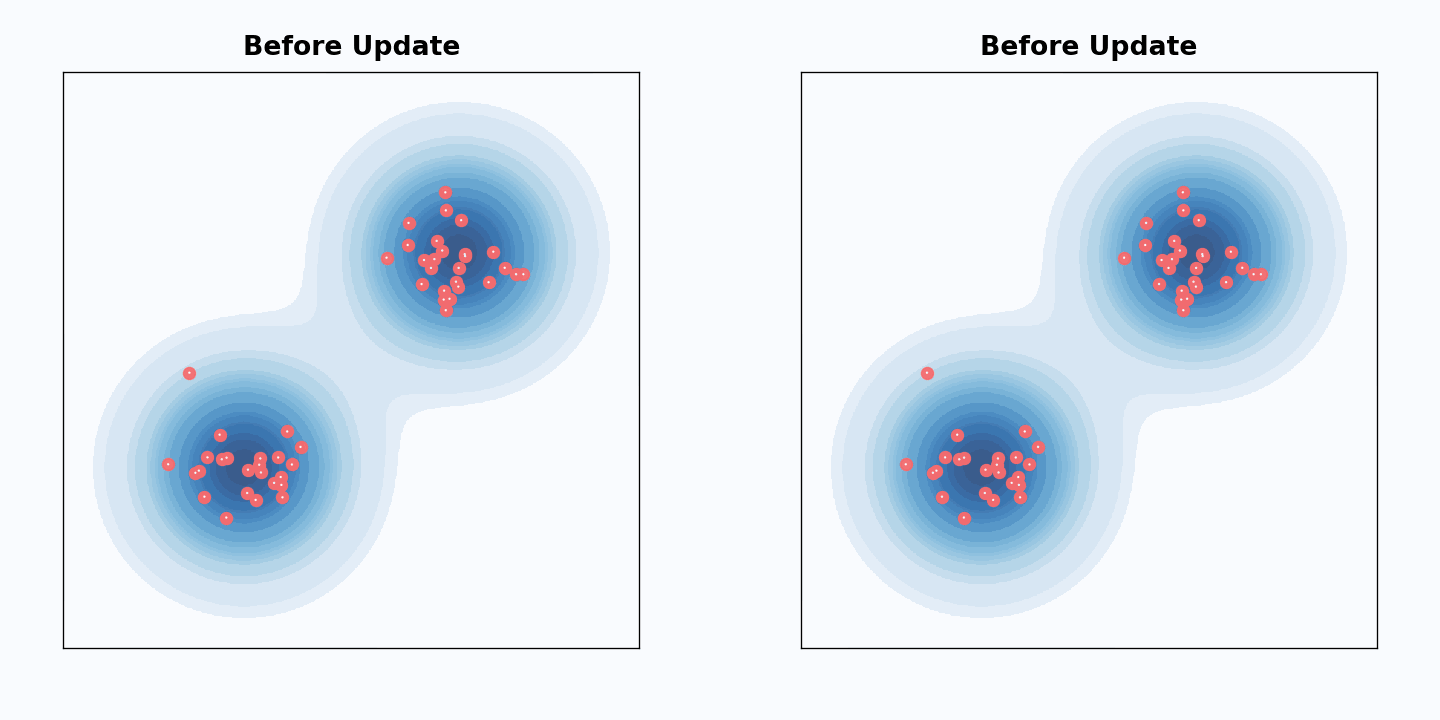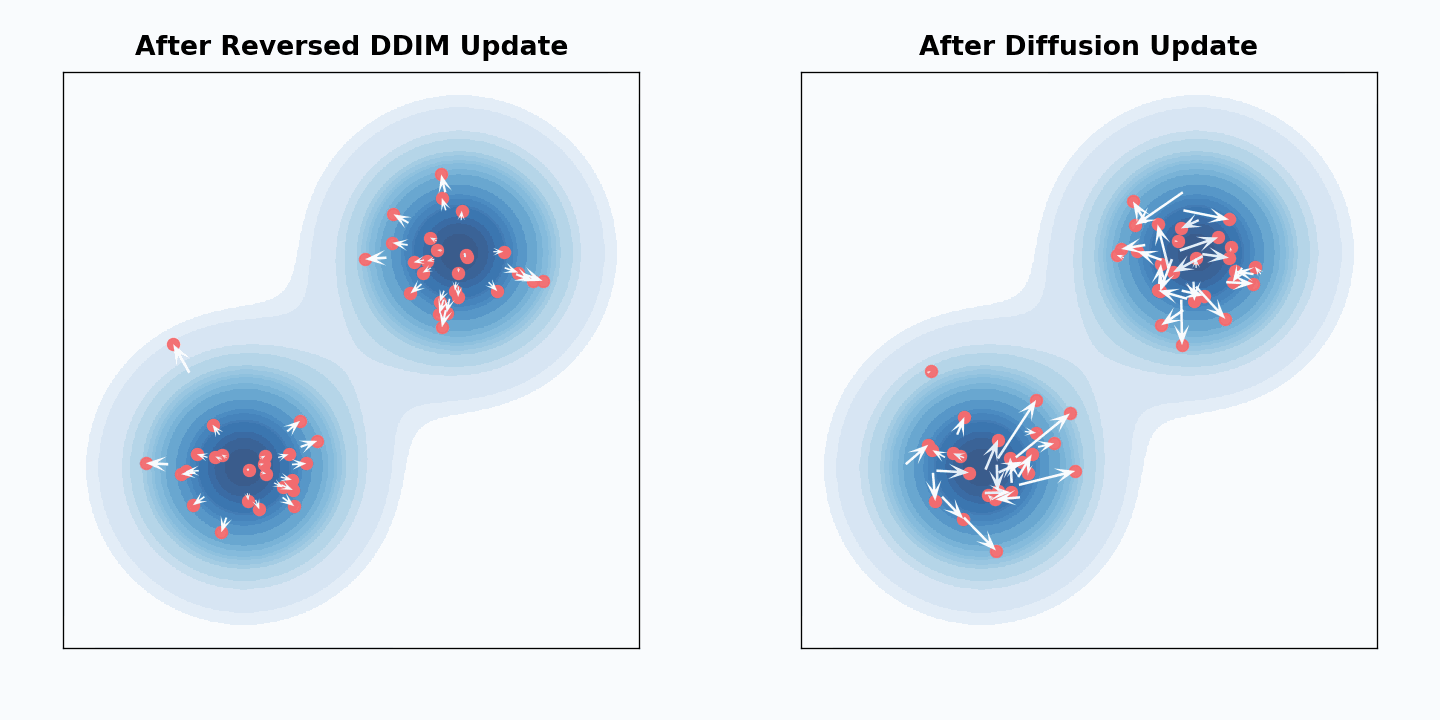
从博客阅读角度看,这两张图最重要的价值不是提供细节证明,而是强化一个统一直觉:无论是去噪还是速度积分,本质上都在描述样本沿路径从一个分布流向另一个分布。
学习路径 vs 工程路径
Notebook 的价值在于,它没有停留在抽象公式,而是把这套统一视角拆成两条互补路径:一条用最小二维例子把理论跑通,另一条用 diffusers 看现代工程接口如何封装这些过程。
| 对比维度 | 学习路径 | 工程路径 |
|---|---|---|
| 目标 | 看清 、、 的数学关系 | 看清 pipeline、scheduler、guidance 的工程抽象 |
| 数据与模型 | 2D toy distribution + 小型 MLP | 预训练 diffusion pipeline |
| 采样方式 | 手写离散更新 / Euler 积分 | 调用高层 API 与 scheduler |
| 最适合做什么 | 原理讲解、面试准备、公式验证 | 快速试验、工程接入、推理参数调节 |
这两条路径不是重复劳动,而是两个层级上的同一知识:前者解释“为什么成立”,后者解释“实际怎么用”。
代码实战
这一部分最值得保留的,不是完整 notebook 的所有细节,而是最能体现统一视角的代码骨架。
1. 定义统一概率路径
下面这段代码明确了路径系数、路径采样以及真实速度的定义。它是整个 notebook 的理论核心。
def alpha_sigma(t):
alpha = torch.cos(0.5 * math.pi * t)
sigma = torch.sin(0.5 * math.pi * t)
return alpha, sigma
def alpha_sigma_dot(t):
alpha_dot = -0.5 * math.pi * torch.sin(0.5 * math.pi * t)
sigma_dot = 0.5 * math.pi * torch.cos(0.5 * math.pi * t)
return alpha_dot, sigma_dot
def sample_path(x0, t, noise=None):
if noise is None:
noise = torch.randn_like(x0)
alpha, sigma = alpha_sigma(t)
x_t = alpha.unsqueeze(1) * x0 + sigma.unsqueeze(1) * noise
return x_t, noise
def true_velocity(x0, noise, t):
alpha_dot, sigma_dot = alpha_sigma_dot(t)
return alpha_dot.unsqueeze(1) * x0 + sigma_dot.unsqueeze(1) * noise这段实现对应的正是论文里那条核心路径与它的导数。只要这里成立,后面的 -prediction 和 -prediction 就会自然落在同一个框架里。
2. 从噪声预测恢复速度参数化
这一步是连接 Diffusion 与 Flow Matching 的桥。
def epsilon_to_velocity(x_t, eps_hat, t):
alpha, sigma = alpha_sigma(t)
alpha_dot, sigma_dot = alpha_sigma_dot(t)
a = alpha_dot / alpha.clamp_min(1e-5)
b = sigma_dot - a * sigma
return a.unsqueeze(1) * x_t + b.unsqueeze(1) * eps_hat
def predict_x0_from_epsilon(x_t, eps_hat, t):
alpha, sigma = alpha_sigma(t)
return (x_t - sigma.unsqueeze(1) * eps_hat) / alpha.unsqueeze(1).clamp_min(1e-5)如果你只记一段代码来解释这篇文章,最值得记住的就是这里。因为它把“噪声预测并不只是噪声预测”这件事直接落到了实现层面。
3. 最小训练框架
Notebook 用一个小型向量场网络分别训练两种目标:
class TinyVectorField(nn.Module):
def __init__(self, data_dim=2, time_dim=32, hidden_dim=128):
super().__init__()
self.time_emb = SinusoidalTimeEmbedding(time_dim)
self.net = nn.Sequential(
nn.Linear(data_dim + time_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, hidden_dim),
nn.GELU(),
nn.Linear(hidden_dim, data_dim),
)
def forward(self, x_t, t):
t_emb = self.time_emb(t)
return self.net(torch.cat([x_t, t_emb], dim=1))
def train_model(model, loader, loss_mode='epsilon', num_epochs=NUM_EPOCHS, lr=LR):
model = model.to(device)
optimizer = torch.optim.Adam(model.parameters(), lr=lr)
for epoch in range(num_epochs):
for (x0,) in loader:
x0 = x0.to(device)
t = torch.rand(x0.shape[0], device=device).clamp(1e-4, 1 - 1e-4)
x_t, noise = sample_path(x0, t)
pred = model(x_t, t)
target = noise if loss_mode == 'epsilon' else true_velocity(x0, noise, t)
loss = nn.functional.mse_loss(pred, target)
optimizer.zero_grad()
loss.backward()
optimizer.step()这里最有启发性的地方是:模型结构几乎不需要改变,真正变化的是监督目标。换句话说,同一个网络骨架,在共享路径下就能分别扮演 Diffusion 预测器和 Flow Matching 预测器。
4. 工程接口如何封装这些过程
Notebook 还给出了一个很有工程感的对照:使用 diffusers 高层 pipeline 来观察实际推理接口。
from diffusers import DiffusionPipeline, DDIMScheduler, EulerDiscreteScheduler
pipe = DiffusionPipeline.from_pretrained(
'hf-internal-testing/tiny-stable-diffusion-pipe',
torch_dtype=dtype,
)
pipe = pipe.to(device)
pipe.set_progress_bar_config(disable=True)
out_default = pipe(prompt=prompt, num_inference_steps=10, guidance_scale=5.0)
pipe.scheduler = DDIMScheduler.from_config(pipe.scheduler.config)
out_ddim = pipe(prompt=prompt, num_inference_steps=10, guidance_scale=5.0)
pipe.scheduler = EulerDiscreteScheduler.from_config(pipe.scheduler.config)
out_euler = pipe(prompt=prompt, num_inference_steps=10, guidance_scale=5.0)这段代码的意义在于:它把论文中的统一视角带到了现代工程接口上。pipeline、scheduler、num_inference_steps、guidance_scale 这些参数,并不是和论文理论脱节的黑箱;它们只是把多步状态更新包装成了更好用的工业 API。
![]()
总结
这篇文章最值得吸收的不是某个单独公式,而是一种看问题的方法:先固定概率路径,再讨论参数化。只要路径共享,Diffusion 的噪声预测与 Flow Matching 的速度预测就常常不是两件事,而是同一个生成过程的两种坐标表达。
对学习者来说,这个视角能把很多零散术语串起来。对工程实践来说,它也能帮助我们理解:很多所谓“新方法”的变化,未必是在更换生成机制,可能只是换了更合适的参数化、更合适的求解器,或者更合适的接口封装。