构建 Agent 最容易犯的一个错误,是一上来就把系统做成 autonomous agent,仿佛只有“让模型自己决定下一步”才算高级。Anthropic 在 Building effective agents 里给出的恰恰是相反的工程直觉:先用最小可行系统验证任务,再优先选择 workflow,只有当流程真的无法静态编码时,才引入 agent loop。
这篇文章关心的不是某一个 benchmark,也不是某一个具体 demo,而是更底层的设计问题:如何在灵活性、可控性、成本和可观测性之间取得平衡。只要你在做带工具调用、检索、记忆或多步推理的系统,这套方法论几乎都能直接迁移。
TL;DR
- 先别做 Agent:能用单次调用或 workflow 解决,就不要上 agent loop。
- Workflows vs Agents 的分界线,不是“用不用工具”,而是“流程控制权在代码还是在模型”。
- 五类 workflow 模式覆盖了大多数工程场景:prompt chaining、routing、parallelization、orchestrator-workers、evaluator-optimizer。
- 可靠性的重点不是更长的提示词,而是工具接口、结构化输出、可观测性与评测闭环。
- 真正的 agent loop 必须同时具备三样东西:动态决策需求、可验证反馈、明确止损机制。
先问自己:真的需要 Agent 吗?
| 任务特征 | 更推荐 | 为什么 |
|---|---|---|
| 只需要一次检索或一次工具调用就能结束 | 单次调用(带工具 / RAG) | 成本最低、延迟最小、最容易测试 |
| 步骤固定、可写成流程(即使有分支) | Workflow | 可控、可回放、容易加 guardrails |
| 步骤不固定,需要根据中间结果动态决定下一步 | Agent loop | 只有在“必须动态”时才值得付出额外复杂度 |
很多“看起来需要 agent 的任务”,最后其实暴露的是两件事:一是缺评测,不知道哪里失败;二是工具设计不清晰,模型每一步都在猜。把这两件事补齐,复杂度往往就能压回 workflow。
Anthropic 的定义:Workflows vs Agents
Anthropic 把 agentic systems 分成两类:
- Workflow:由代码定义流程,LLM 在指定位置做子决策或子生成。
- Agent:由 LLM 在运行时决定下一步做什么,包括是否调用工具、调用哪个工具、是否继续迭代。
这个定义的价值很大,因为它把“这算不算 agent”从概念争论变成了一个工程问题:流程控制权到底在代码里,还是在模型里。

区分的关键:谁在控制流程
在 Workflow 中,LLM 是执行者。代码已经决定了顺序:先做什么、再做什么、遇到什么条件怎样分支、什么时候结束。模型只是完成每一步被分配的局部任务。
在 Agent 中,LLM 是决策者。代码只提供循环骨架,而每一步到底查什么、调哪个工具、要不要继续,全都由模型运行时决定。
这个差异解释了为什么“Workflow 里也用了 LLM 和工具”依然不等于 Agent。工具本身不是分界线,控制权才是。
为什么 Workflow 里的 LLM 调用不构成 Agent
以一个最常见的 prompt chaining 为例:
def translate_and_review(text):
translation = llm.invoke('请将以下英文翻译为中文:' + text)
review = llm.invoke('请校对这段翻译,指出错误:' + translation)
if '错误' in review:
final = llm.invoke('根据校对意见修正翻译:' + review)
else:
final = translation
return final这里有多次 LLM 调用,但流程完全由代码控制。模型从头到尾都没有决定“下一步做什么”的权力。
对比真正的 agent loop:
def agent_loop(goal):
messages = [SystemMessage('你是助手,可以使用以下工具...')]
while True:
response = llm.invoke(messages)
if not response.tool_calls:
return response.content
results = execute_tools(response.tool_calls)
messages.append(results)这里代码不知道会循环几次、不知道模型会选哪个工具,也不知道它什么时候停。流程的关键决策来自模型,所以它才是 agent。
混合体才是常态
真实工程里,纯 Workflow 和纯 Agent 都很少见,大多数系统是混合体。最重要的不是追求“纯粹”,而是分清:
- 哪些部分必须由代码硬编码,保证稳定与合规
- 哪些部分可以交给模型,让它用灵活性换效率
这个切分能力,本身就是 agent 系统工程化的核心能力。
从最小可行系统开始
Anthropic 把 augmented LLM 视为 agentic system 的基本构建单元:在 LLM 核心之上,通过检索、工具调用和记忆等能力做增强。
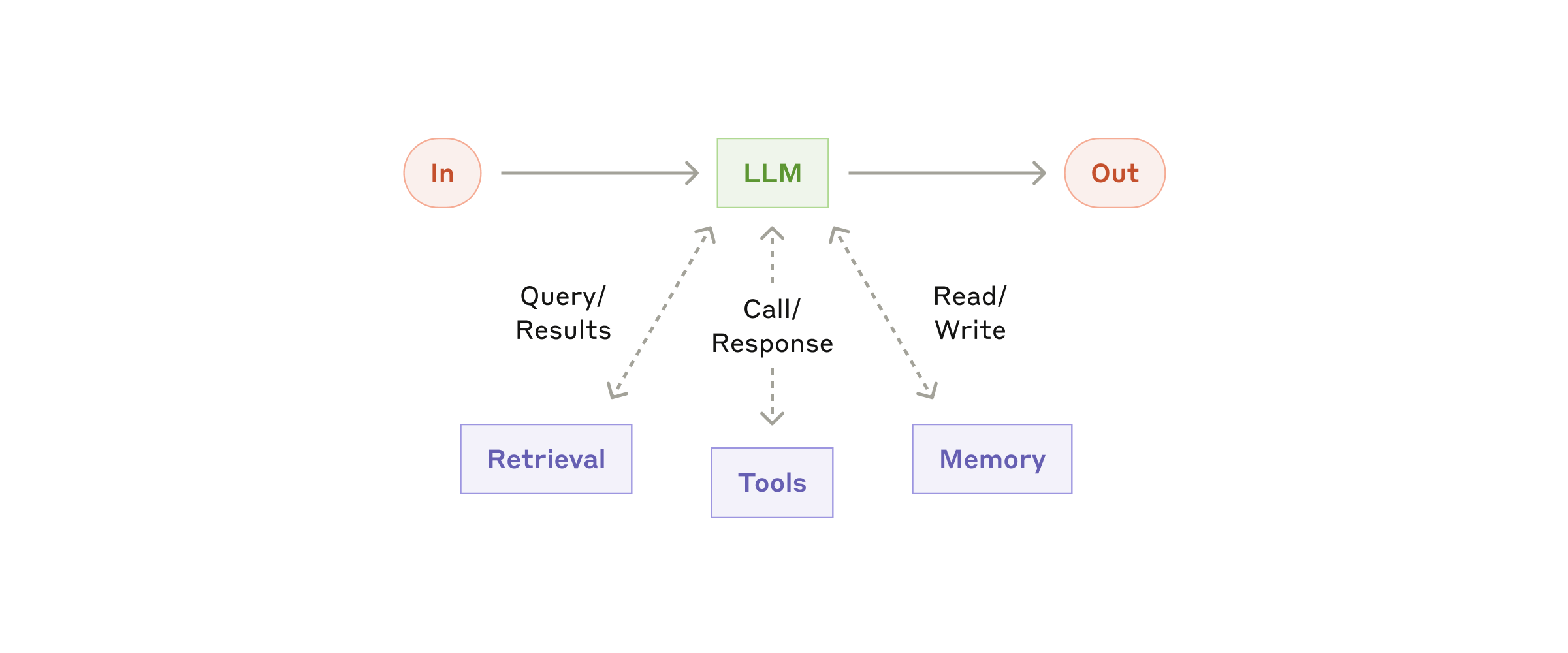
在引入 agent loop 之前,先把三件事做稳定:
- 结构化输出:让模型产出 JSON、表格或其他可解析结果,而不是自由文本。
- 工具调用:工具的输入、输出、错误形式都必须可预测。
- 可观测与回放:每一步输入、输出、调用链路和错误码都要能追踪。
如果这三件事做不稳,上 agent loop 只是把问题放大。
五类 Workflow 模式
Anthropic 把高频 workflow 总结成五类。按复杂度从低到高理解,会很清楚。
Prompt Chaining(串联)
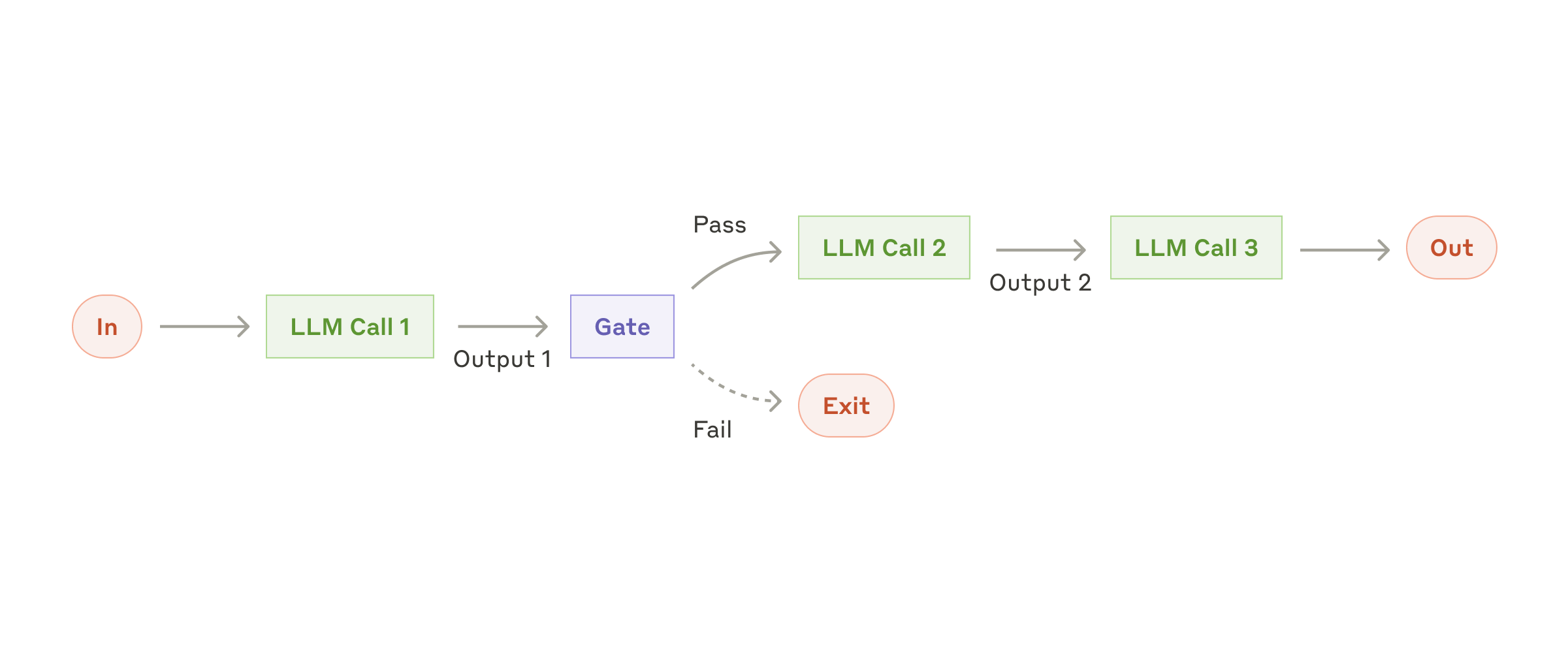
适用场景:任务天然能拆成固定的 2~5 步,例如提取 → 验证 → 生成。
关键做法:
- 每一步都让输出更简单、更可检验
- 在链路中插入“闸门”
- 校验失败就回退或重试
最大风险是误差沿链条累积,所以“中间结构化 + 局部校验”通常比一股脑写更长的提示词更有效。
Routing(路由)
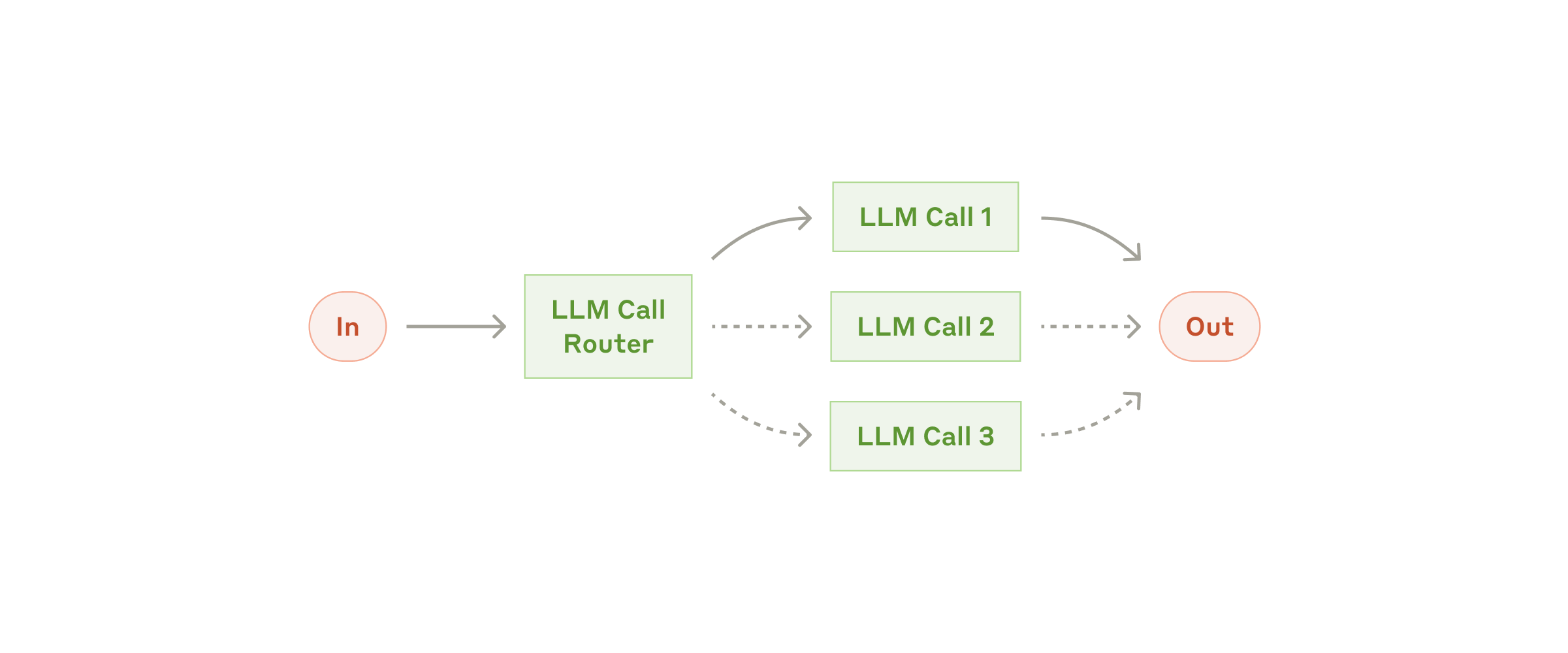
适用场景:不同输入类型需要不同提示词、不同工具甚至不同模型。
关键做法:
- 定义清晰 label
- 给分类标准配示例
- 把分支入口条件说清楚
最大的坑是分类标准过于抽象,导致入口一旦分错,下游全错。
Parallelization(并行)
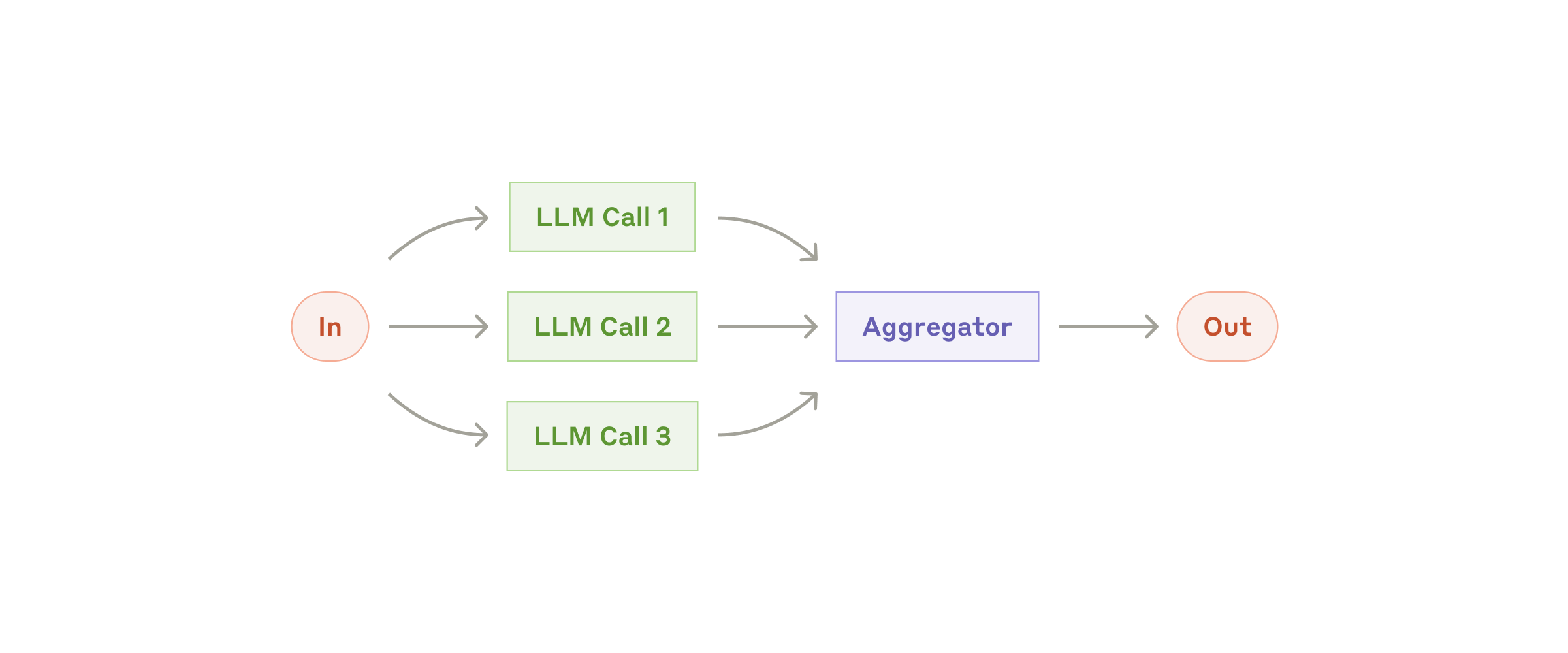
并行常见有两种:
- Sectioning:拆成独立子块并行处理
- Voting:同一问题多次采样,再做结果投票或汇总
并行最常见的问题不是“跑不起来”,而是合并阶段的信息重复、风格冲突和结论不一致,所以要提前定义好聚合规则。
Orchestrator-Workers(编排者-工人)
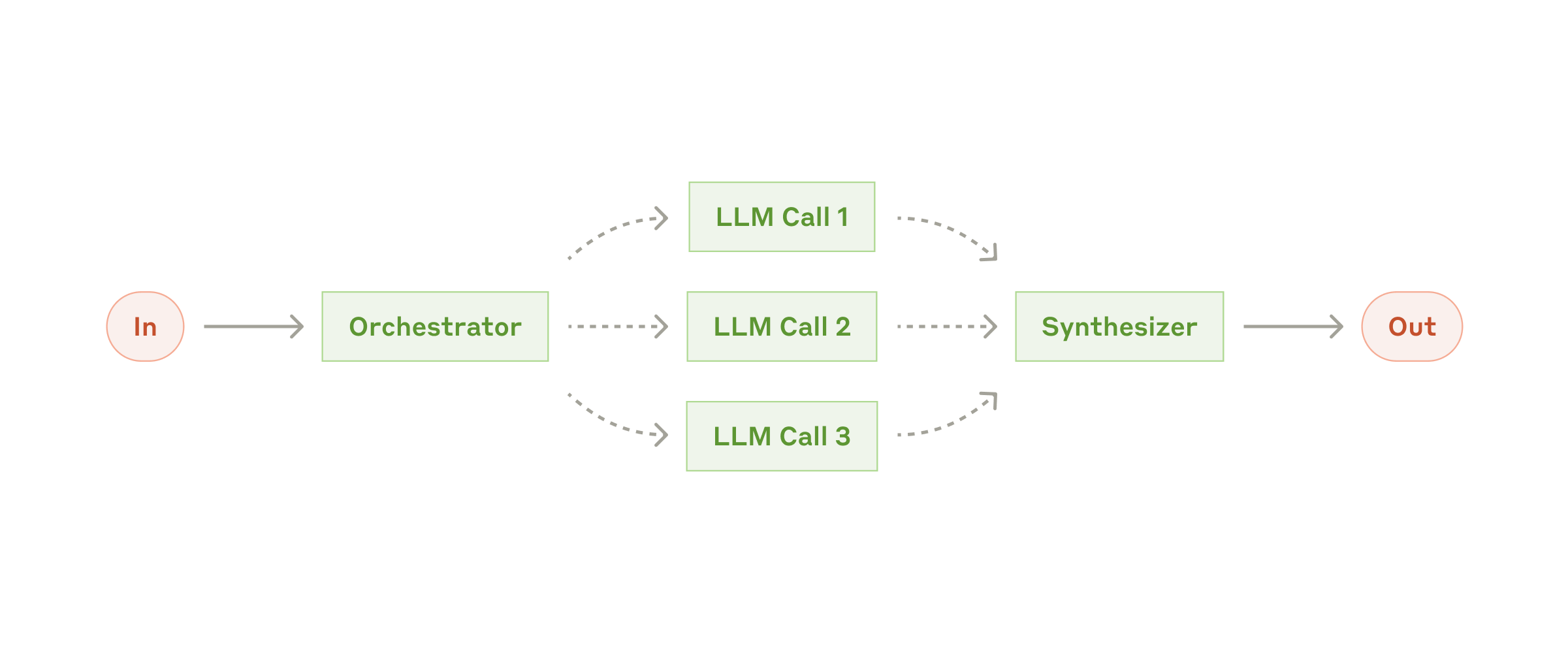
适用场景:子任务数量和类型都不固定。
关键做法:
- 编排者负责拆解、分配与预算控制
- 工人的输入尽量具体,输出尽量结构化
- 系统必须有停止条件,防止无限拆解
它比普通 routing 更灵活,但也更容易让系统不收敛。
Evaluator-Optimizer(评审-优化)
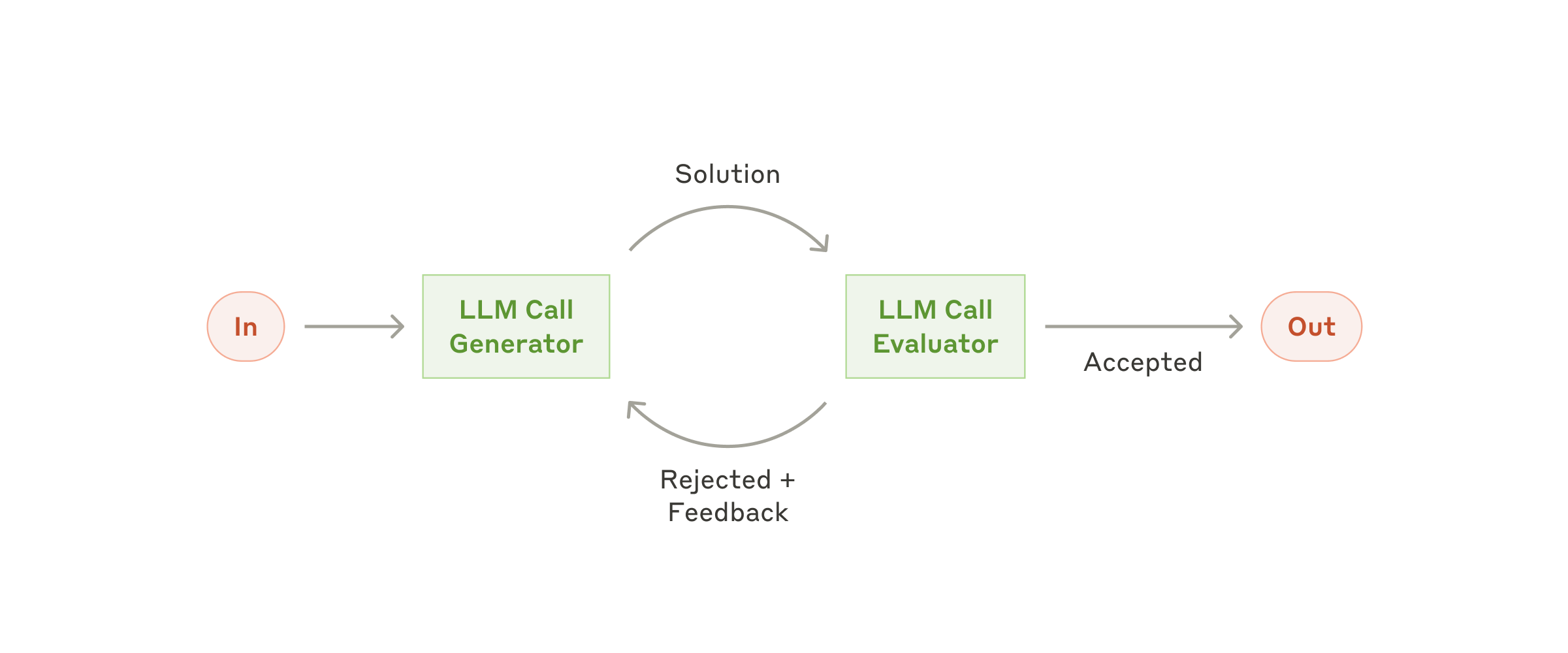
适用场景:有明确质量标准,而且多轮改写确实会提升结果。
关键做法:
- 生成者负责产出候选答案
- 评审者负责按 checklist 或约束打分
- 只有在评审标准足够清晰时,这个模式才真的有价值
如果评审本身不稳定,那只是把不确定性又复制了一遍。
五种 Workflow 模式对比
| 模式 | 适用场景 | 延迟 | 实现复杂度 | 核心风险 |
|---|---|---|---|---|
| Prompt Chaining | 步骤固定、可串行分解 | 随链长线性增长 | 低 | 误差逐步累积 |
| Routing | 输入类型多样,各需专用处理 | 增加一次分类调用 | 低 | 分类错误导致下游全错 |
| Parallelization | 子任务独立、可同时执行 | 取决于最慢分支 | 中 | 合并时信息冲突 |
| Orchestrator-Workers | 子任务数量 / 类型不可预知 | 取决于编排轮数 | 高 | 编排不收敛 |
| Evaluator-Optimizer | 有明确质量标准且可迭代优化 | 至少两倍 | 中 | 评审自身不稳定 |
一个很实用的策略是:从上往下选。先问 Prompt Chaining 能不能解决,不行再考虑 Routing,再往上才是并行、编排和评审优化。只有五类 workflow 都不够时,才轮到真正的 agent loop。
Agent Loop:何时该上,以及如何止损
当 workflow 无法覆盖、步骤完全不可预测时,才需要引入真正的 agent。
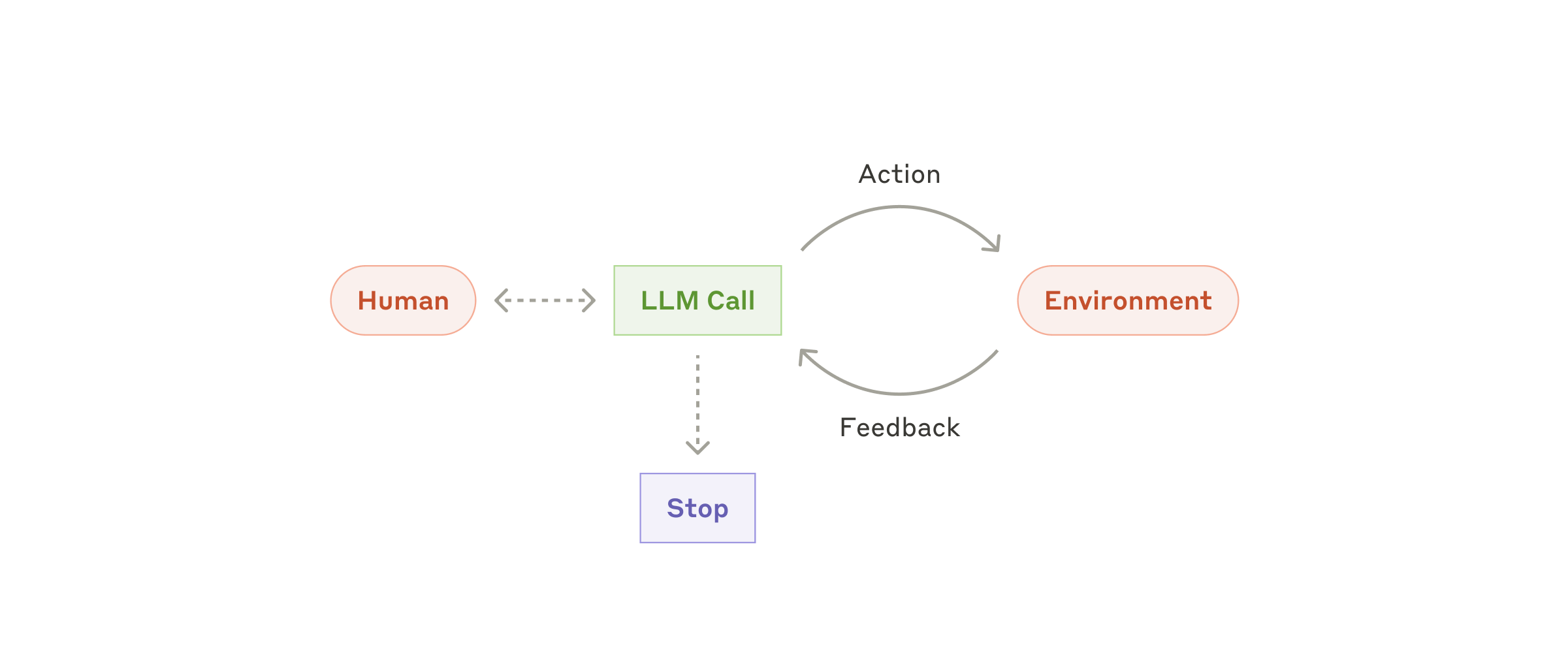
上 agent loop 之前,最好先确认三个前提:
- 必须动态:固定流程真的写不出来,或者分支爆炸无法维护。
- 有反馈:每一步都能拿到 observation,例如工具返回、测试结果、环境响应。
- 能止损:预算、超时、最大步数、重复检测这些限制必须提前设计好。
如果没有止损,agent 的自主性就会直接变成成本失控和调试噩梦。
为什么最后一轮要解绑工具
很多系统在最后一轮只是提示“请不要再调用工具”。这不够可靠,因为提示词不是强约束。更稳的做法是:在靠近迭代上限时,直接切换到不绑定工具的 LLM,让模型从机制上失去继续调用工具的能力。
这个设计体现的是一个很重要的原则:能靠系统约束解决的问题,就不要只靠 prompt 约束。
工具接口与 ACI 设计
Anthropic 文章里最容易被低估的一点是:很多 agent 不可靠,不是模型能力不够,而是工具接口设计得不适合模型使用。
一份对模型友好的工具接口通常有这些特征:
- 名字即意图:动词开头,尽量避免含混命名。
- 参数少而清晰:宁可拆成两个工具,也别塞十个可选参数。
- 有示例:至少给 2~3 个正确调用样例。
- 错误可处理:返回结构化错误,而不是含糊字符串。
- 可回放:每一次调用都能追踪。
工具输出保护
除了接口定义本身,工具还要对输出做保护:
- 截断过长结果,防止上下文爆炸
- 给出类型提示,引导模型下一步该做什么
- 在错误时告诉模型可恢复的路径,而不是只报失败
这类设计看起来是“小工程细节”,但对 agent 稳定性通常比再调一版 prompt 更有用。
Python 沙箱为什么重要
run_python 这类工具很强,也最危险。能执行任意代码,就意味着必须考虑:
- import 白名单
- 受限 builtins
- I/O 能力是否关闭
- 返回内容是否被过滤
对 agent 系统来说,沙箱并不是“额外安全加分项”,而是把工具暴露给模型之后的基本前提。
ReAct 能带来什么?
ReAct 的价值不在于让模型写出漂亮的 Thought,而在于把“推理 → 行动 → 观察”这条轨迹显式化。
它带来的两个直接收益是:
- 减少幻觉:缺信息就先行动拿 observation,而不是硬猜。
- 更可调试:失败时你可以沿 action / observation 回放整条轨迹,知道问题出在工具选择、信息不足,还是终止条件。
所以从工程角度看,ReAct 更像一种可观测轨迹格式,而不只是一个提示词技巧。
总结
Anthropic 这篇文章真正留下的是一条很清晰的工程路线:先用最小可行系统验证任务,再优先选择 workflow,最后才把 agent loop 作为处理动态问题的手段;同时把可靠性建立在工具接口、结构化输出、评测闭环和强约束机制上。
这套方法最值得借鉴的地方,不是某个单独技巧,而是它始终在强调一件事:把自由度留给真正需要模型发挥的地方,把确定性留给代码和系统设计。