A Gentle Introduction to Graph Neural Networks
Benjamin Sanchez-Lengeling, Emily Reif, Adam Pearce, Alexander B. Wiltschko — Distill 2021 (Google Research)
图神经网络(Graph Neural Network, GNN)是一类专门处理图结构数据的神经网络模型。图由节点和边组成,能够表示实体间的关系。GNN 通过学习这些关系,可用于预测、分类或生成新的图结构。本文从图的基本概念出发,逐步深入到消息传递机制和多种经典 GNN 模型,最后通过代码实战对比 GCN、GAT、GIN 的源代码实现与 PyG 简洁实现。
图的基本组成
一张图由三类核心元素构成:
- V(Vertex set,节点集合):图中所有节点的集合,数学表示为
- E(Edge set,边集合):图中所有边的集合,每条边连接两个节点表示关系,数学表示为 ,其中每个 通常是一个节点对
- U(全局属性):在不同文献中含义有所差异,常见两种理解:
- 节点特征矩阵(Node feature matrix):所有节点的特征集合。若每个节点有 维特征,则 是一个 的矩阵
- 全局上下文向量(Global context vector):表示整个图的全局属性
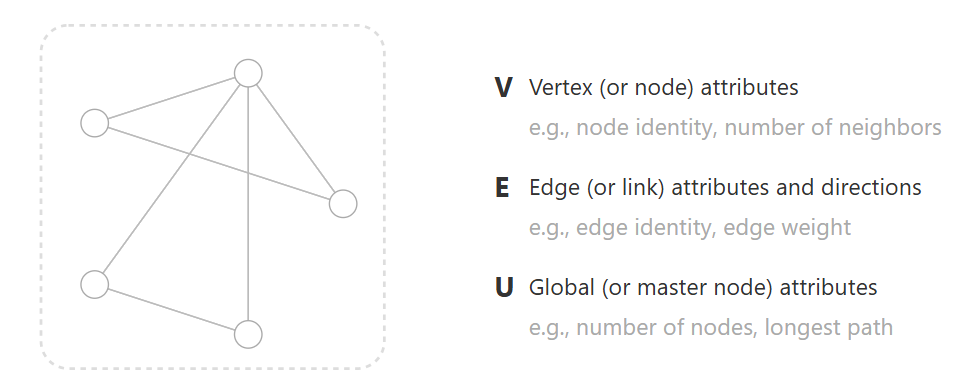
边可以有方向性(有向图)或无方向性(无向图)。

图的应用范围
图结构的表示能力非常广泛,几乎任何关系型数据都可以建模为图。
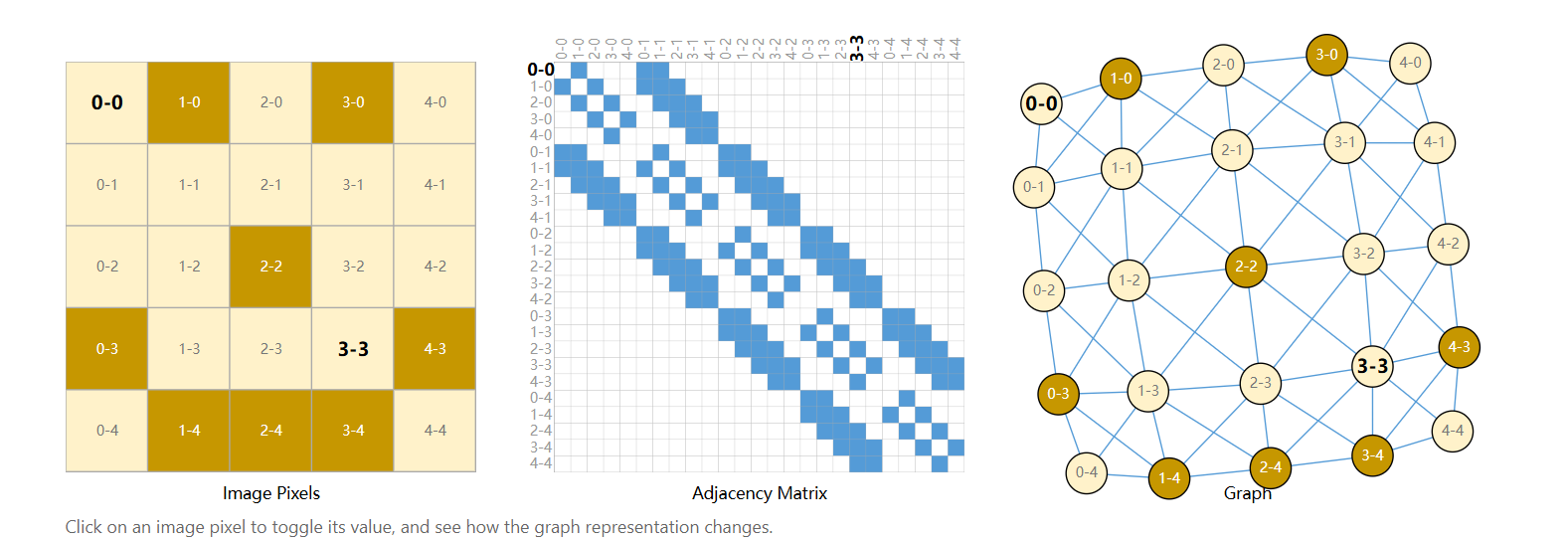
图像作为图:每个像素是一个节点,与相邻像素通过边相连。
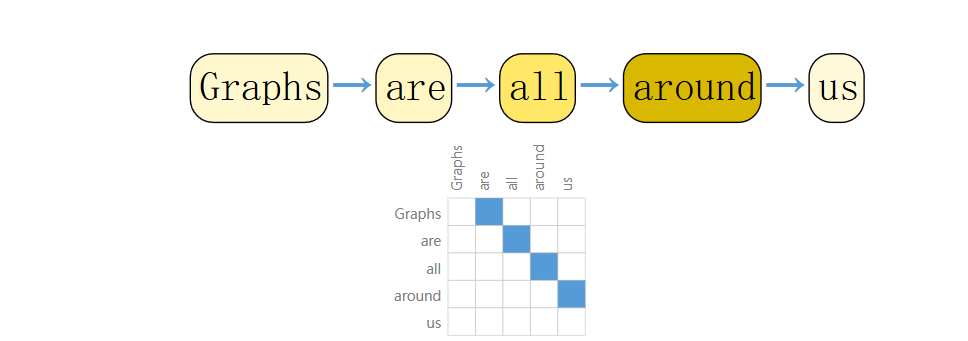
文本作为图:字符或词汇是节点,按顺序通过边相连。
分子结构:原子是节点,化学键是边。

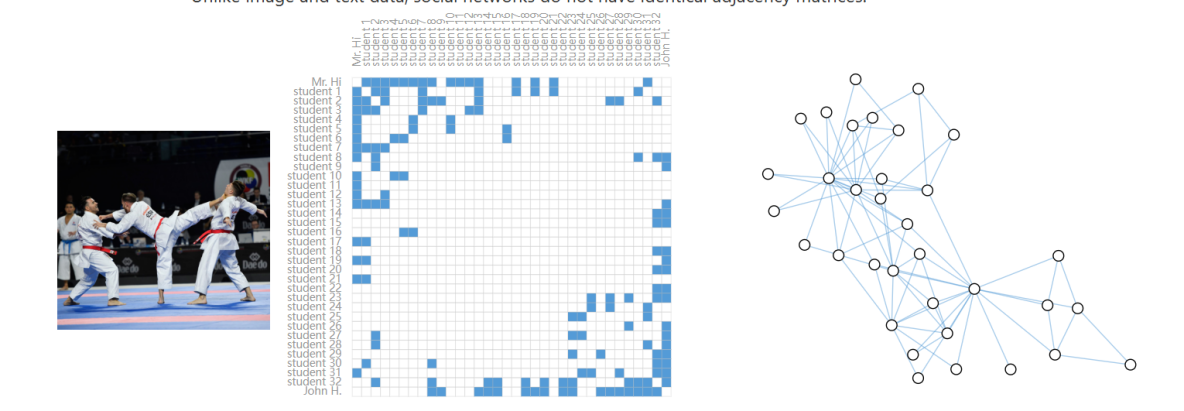
社交网络:用户是节点,关系是边。与图像和文本不同,社交网络的邻接矩阵不具有规则结构。

三种核心任务
节点分类(Node Classification)
已知图结构和部分节点的标签,目标是预测其他未标注节点的类别。
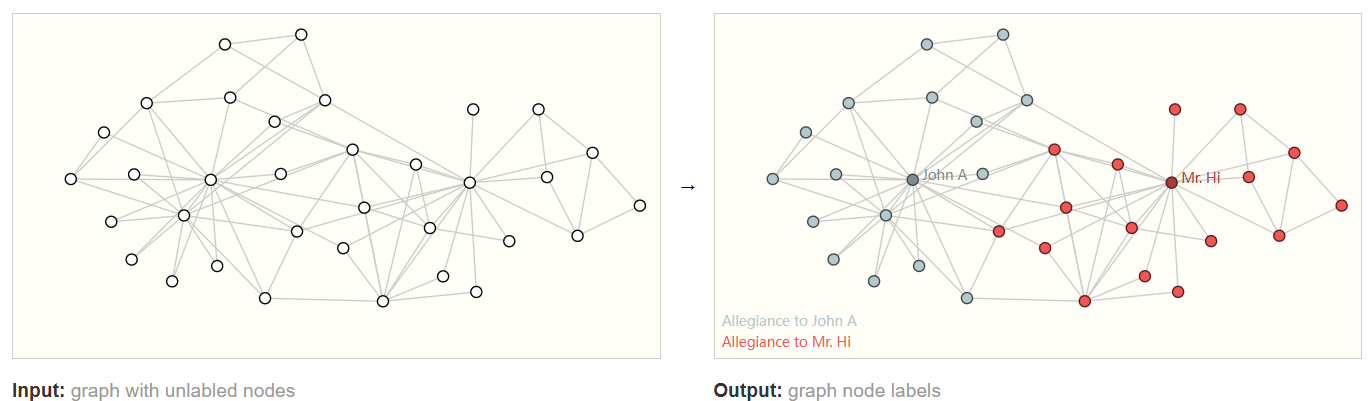
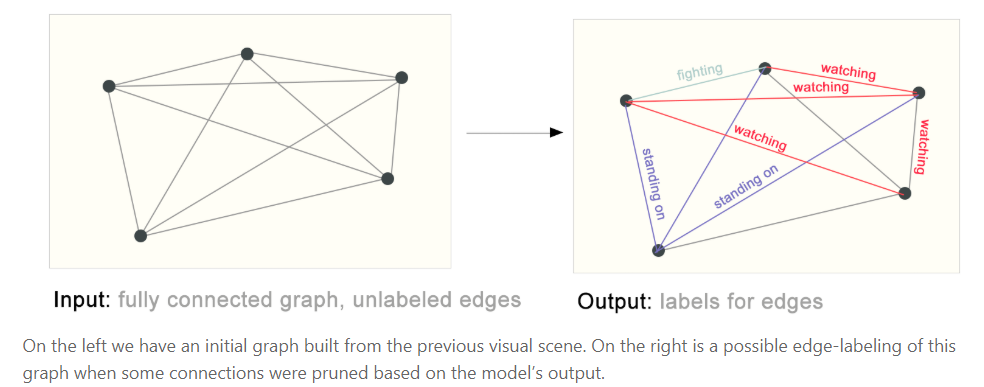
边预测(Edge Prediction / Link Prediction)
已知图结构和节点特征,目标是预测图中哪些节点对之间可能存在边(关系)。
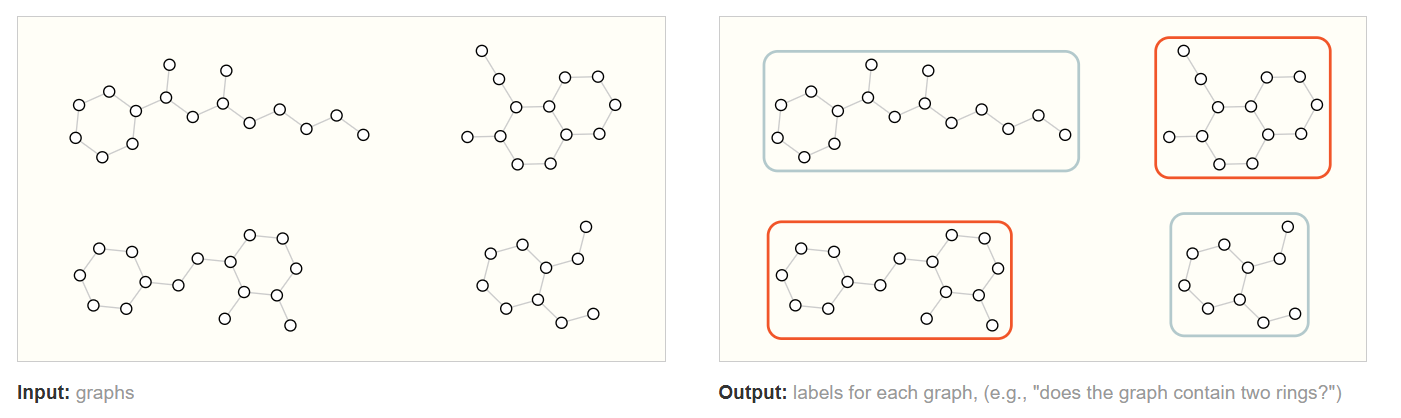
图分类(Graph Classification)
每个样本是一个完整的图,目标是对整个图进行分类。
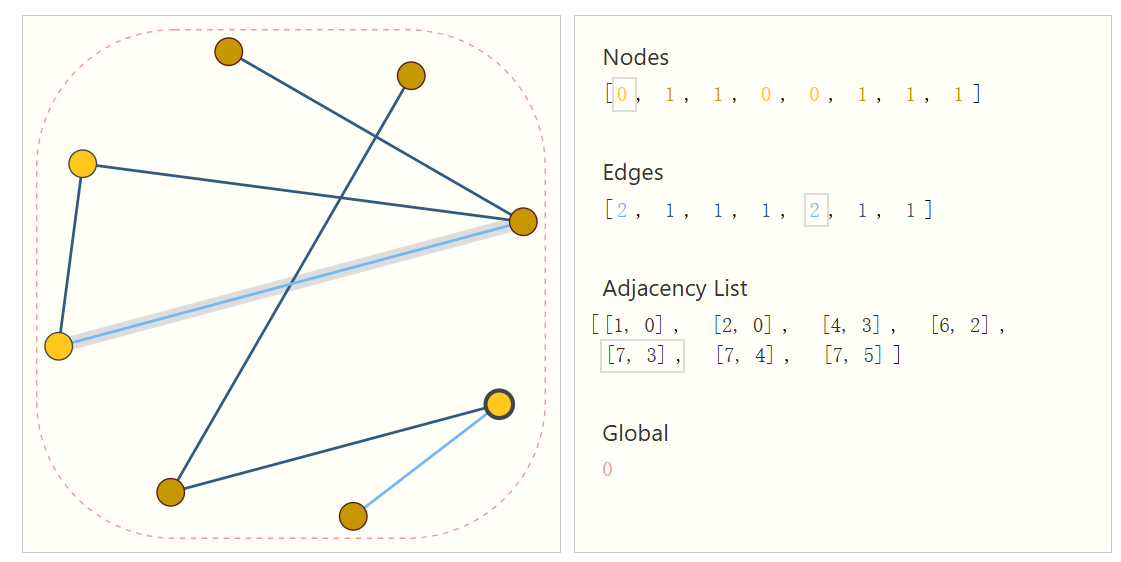
图的数据表示
图通过节点列表、边列表和邻接列表来表示。邻接列表的长度与边的数量一致,第 项表示第 条边连接哪两个节点。节点、边、全局属性既可以用标量表示,也可以用向量表示。
GNN 的定义与工作流程
GNN 是一类专门处理图结构数据的神经网络模型,核心特性包括:
- 对图的所有属性(节点、边、全局上下文)进行可优化的变换
- 保持图的对称性(排列不变性,permutation invariance)
- 采用"图输入-图输出"(graph-in, graph-out)架构
基本工作过程:
- 初始化:为每个节点赋予初始特征表示
- 消息传递:节点从其邻居节点收集信息
- 更新:根据收集的信息更新节点的表示
- 重复:多次重复上述过程,使信息可以从更远的节点传递过来
- 输出:使用最终的节点表示进行预测或其他任务
这个过程与卷积操作类似:目标节点及其邻居节点类似于一个卷积核覆盖的范围,信息通过汇聚操作整合。区别在于卷积中每个位置有不同的权重,而基础 GNN 中邻居信息通常直接相加。
在 GNN 的一层中,、、 分别由一个 MLP 处理(所有节点共享同一个 MLP,所有边共享同一个 MLP)。输入是一个图,输出也是一个图:输出图的属性值被更新,但拓扑结构保持不变。
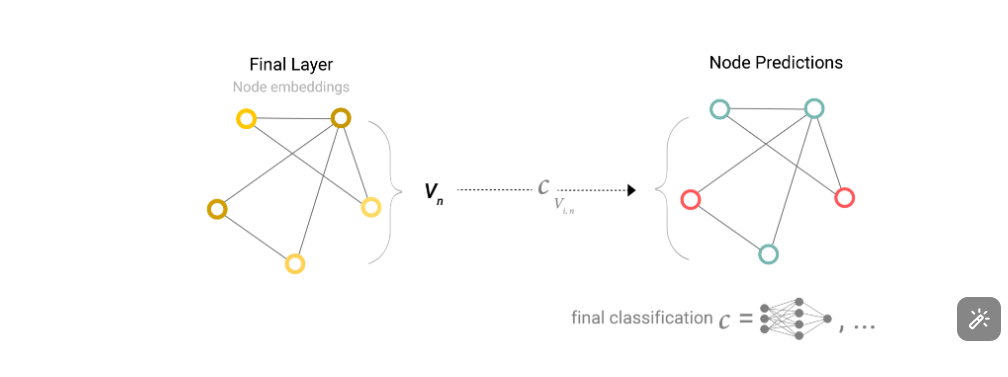
从图输出到预测结果
GNN 经过若干层处理后,输出一张更新了特征的图。要得到具体的预测结果,需要将节点嵌入传入全连接层(加上 Softmax)来获得分类输出。
缺失信息的处理
如果不知道某个节点的向量表示,仍然可以通过信息聚合来传递信息。不管缺失的是边、节点还是全局向量,都可以通过聚合邻居信息来补充。
GNN 的核心是通过图的结构来聚合和传递信息。每个节点从其邻居收集信息,更新自己的表示,再将更新后的信息传递给下一层。例如,某节点的向量表示 = 所有相邻边的向量之和 + 全局向量。
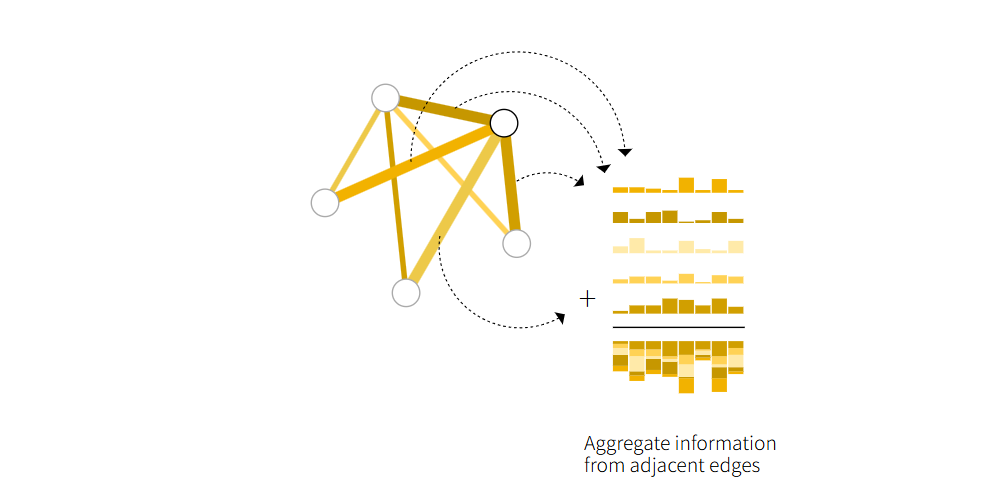
基本架构
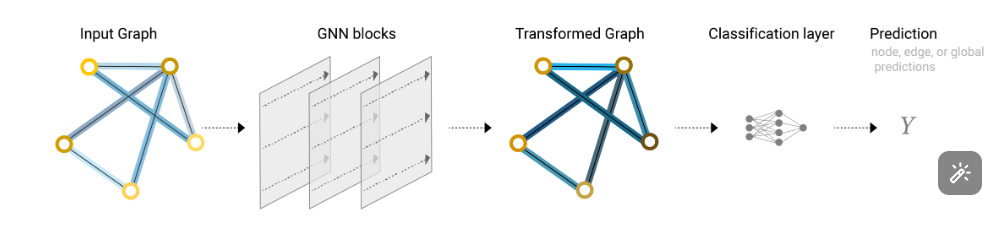
输入一张图,通过 GNN blocks 输出一张图,添加合适的输出层以得到预测结果。如果中间存在缺失信息,可以添加汇聚层来补充。
消息传递机制
基本的 GNN blocks 没有考虑节点与节点、边与边之间的关系。改进方法是尽早将图的结构信息引入 GNN。
节点间消息传递(V -> V)
先聚合,再更新。以某个节点为例,其聚合向量 = 自身向量 + 相邻节点向量之和,之后再进入 MLP 更新。
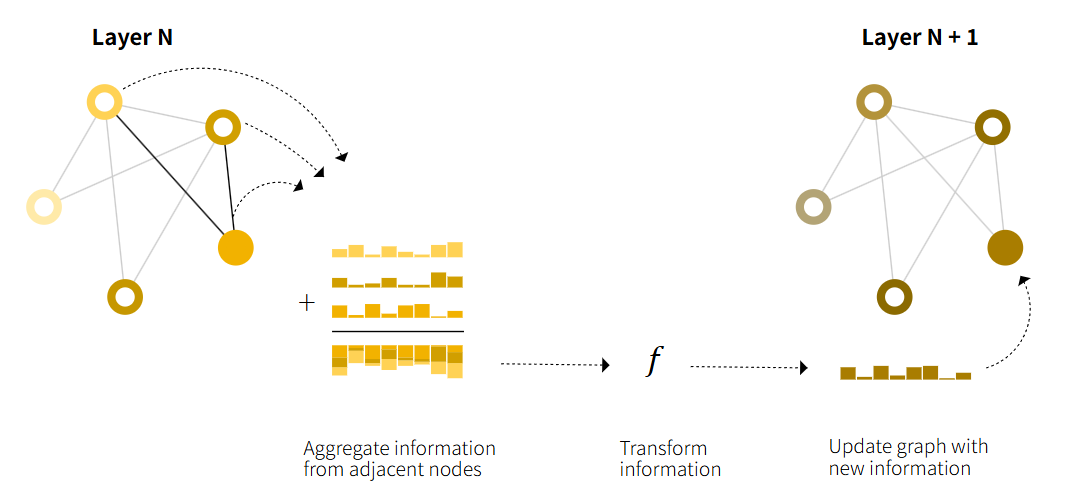
汇聚了 1 跳邻居的信息(1-hop neighbors),通过直接相加实现 V -> V 的信息传递。
图卷积层(Graph Convolutional Layer)
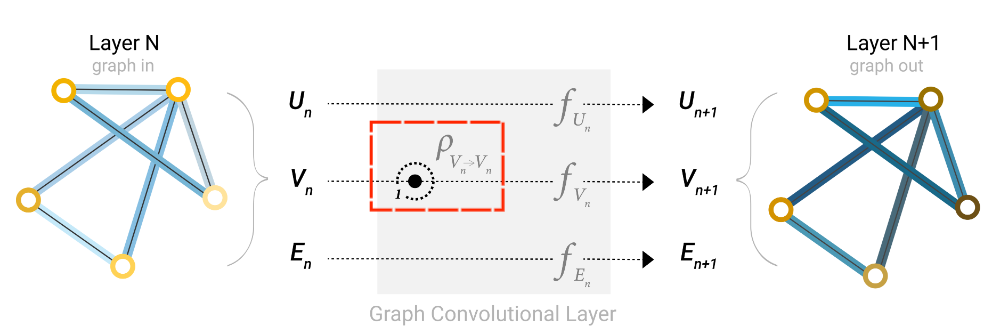
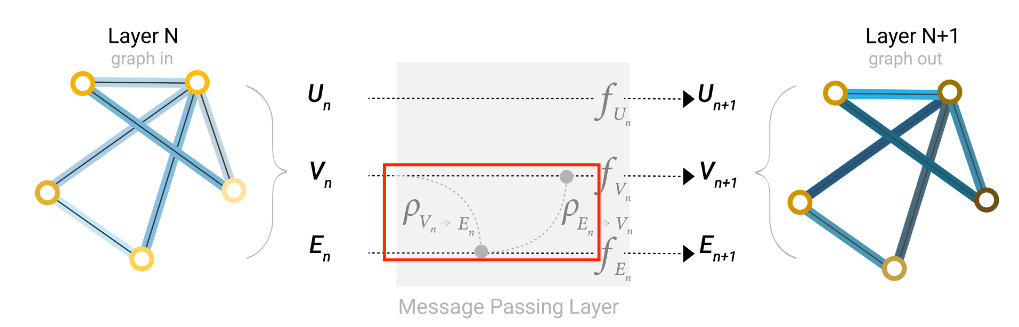
消息传递层(Message Passing Layer)
在消息传递层中,节点先聚合 1 跳邻边的信息,再聚合近邻节点的信息。如果节点向量和边向量维度不同,需要先投影到相同维度再进行信息汇聚。
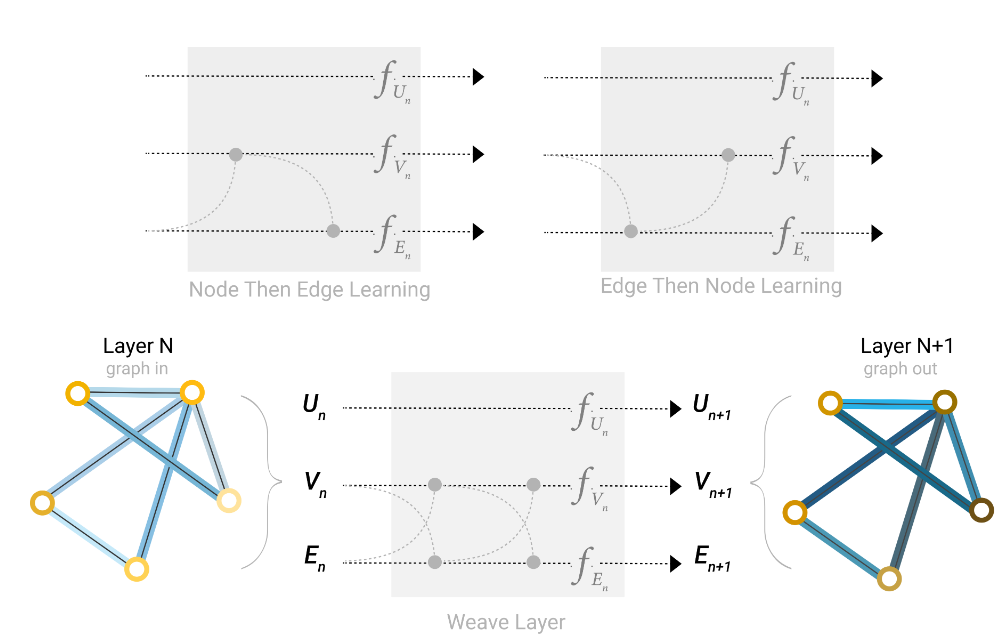
不同的聚合顺序
不同的聚合顺序会产生不同的结果:
- Node Then Edge Learning:先更新节点,再更新边
- Edge Then Node Learning:先更新边,再更新节点
- Weave Layer:节点和边同时交换信息后各自更新
全局表示 U 的作用
如果两个节点距离很远,逐层传递信息效率较低。解决方案是将全局表示 也加入汇聚过程。
与图中所有节点和边都有连接,作为信息传递的桥梁。其作用包括:
- 信息桥梁:节点和边的信息可以汇总到 , 的信息也可以反过来影响所有节点和边
- 全局特征建模: 能捕捉整个图的全局属性(如图的类别、整体结构特征),对图分类等任务非常重要
- 丰富表达能力:仅靠节点和边的局部信息难以捕捉到全局性的结构特征,引入 后模型能学习到更丰富的图表示
在每一轮消息传递中, 会与所有节点和边进行信息交换。 的更新方式通常是将所有节点和边的信息聚合后,再通过神经网络进行变换。最终, 可以作为整个图的嵌入或特征向量,用于下游任务(如图分类)。
超参数与性能
GNN 对超参数比较敏感,主要包括:层数、特征维度(节点、边、全局)、聚合/激活函数、邻居采样数等。
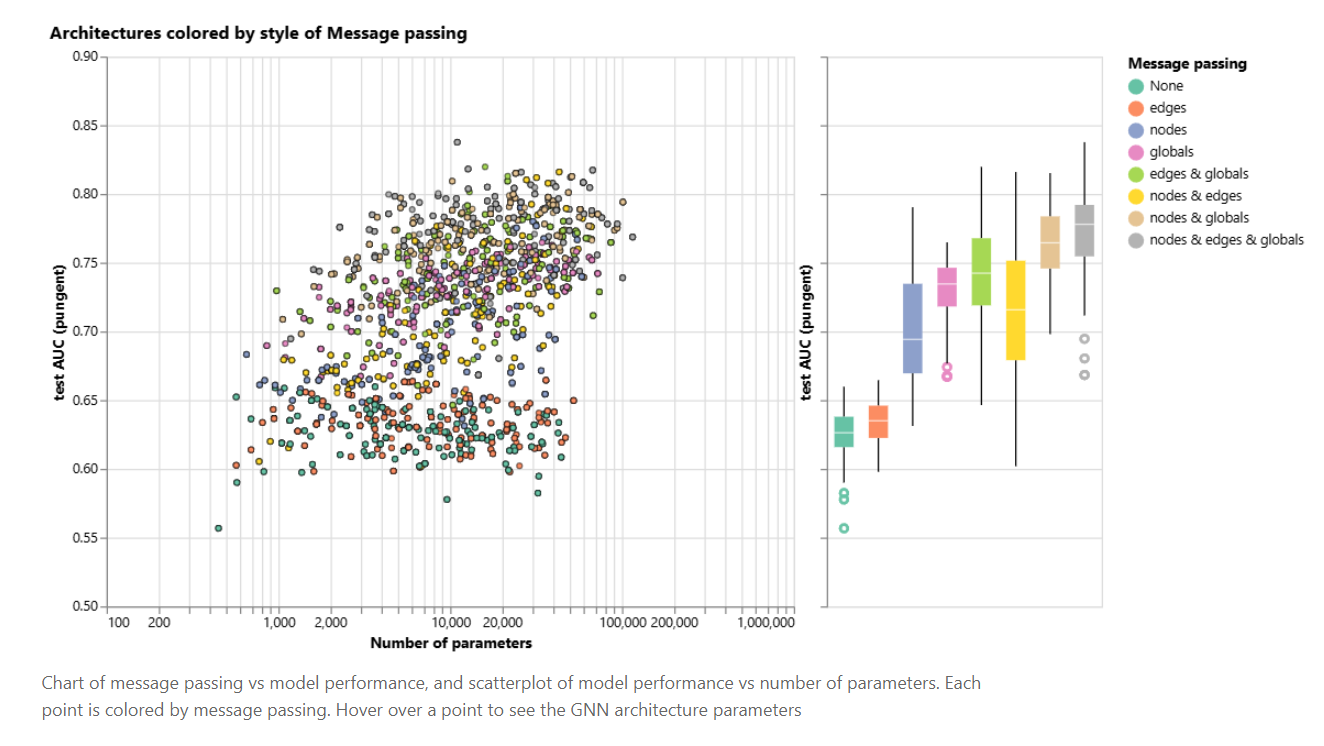
从实验结果可以看出,使用更多类型信息(nodes & edges & globals)的消息传递策略通常能获得更好的性能。
经典模型详解
以下介绍基于空间卷积(Spatial-based Convolution)的多种经典 GNN 模型。这类模型的核心思路统一为两个步骤:Aggregation(用邻居特征更新隐藏状态)和 Readout(将所有节点特征汇总为图级表示)。
Aggregation 是节点级的信息聚合过程:在第 层中,每个节点 会收集其邻居节点的隐藏状态,并与自身特征一起通过求和、平均、加权求和、注意力或 MLP 等函数更新为下一层表示 。由于图中的节点没有固定顺序,Aggregation 通常需要满足排列不变性,即邻居顺序改变时聚合结果不变。
Readout 是图级的信息汇总过程:当多层 Aggregation 得到所有节点的最终表示后,Readout 会通过 Sum、Mean、Max、Attention Pooling 等方式把节点集合压缩成整张图的表示 。这个图级表示可以继续输入 MLP、Softmax 或回归头,用于图分类、图回归等任务。
在 Layer 中,每个节点有隐藏状态 ,经过 Aggregation 得到 Layer 的隐藏状态 ,最终通过 Readout 得到图级表示 。
NN4G(Neural Networks for Graph)
Aggregate:以节点 在第 1 层的特征 为例,其计算公式为:
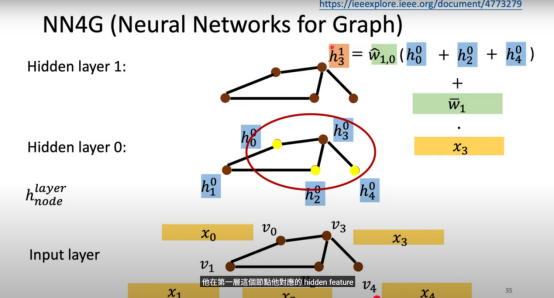
其中:
- 邻居特征聚合: 将中心节点 的所有邻居特征求和
- 邻居权重: 对聚合后的邻居特征进行加权
- 自身特征: 保留节点自身的原始输入特征
- 自身权重: 对自身特征进行加权
- 最终汇聚:将加权后的邻居特征与自身特征相加
Readout:NN4G 采用分层聚合 + 加权融合的策略:
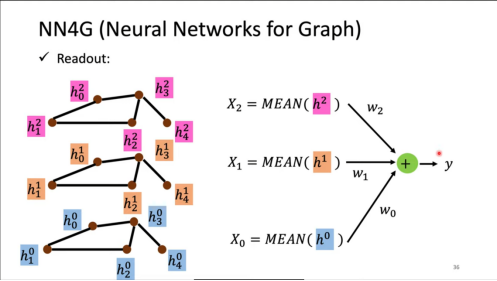
- 对每层节点特征取平均值,得到层级图表示:
- 将不同层的图级表示进行加权求和:
这种方式能够捕捉图在不同抽象层次的信息,生成综合的图级表示。
DCNN(Diffusion-Convolution Neural Network)
Aggregate:核心是基于距离的扩散聚合。以节点 为例:
隐藏层 0 的特征计算:
聚合与 距离为 1 的直接邻居()的特征,通过权重 加权。
隐藏层 1 的特征计算:
聚合与 距离为 2 的节点()的特征,通过权重 加权。
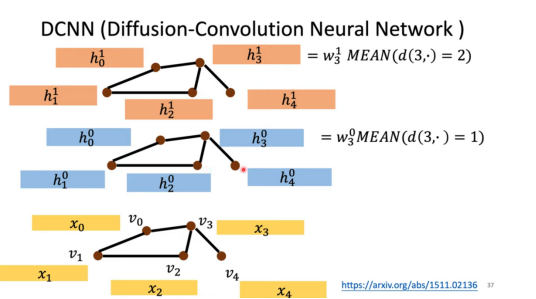
其中 表示对所有与 距离为 的节点特征取平均值。每一层捕获不同范围的局部图结构信息,实现信息扩散。
Readout:采用多跳特征拼接 + 线性变换:
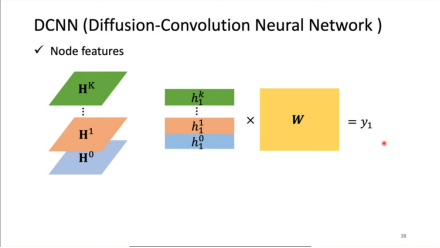
- 将节点在不同扩散步长下的特征向量进行拼接:(0 跳,原始特征)、(1 跳)、...、(K 跳)
- 拼接后形成包含多尺度信息的特征向量
- 通过可学习权重矩阵 进行线性变换得到输出:
DGC(Diffusion Graph Convolution)
DGC 与 DCNN 的区别仅在 Readout 阶段。DGC 不使用拼接 + 线性变换,而是直接对各跳的特征矩阵做(可加权的)求和:
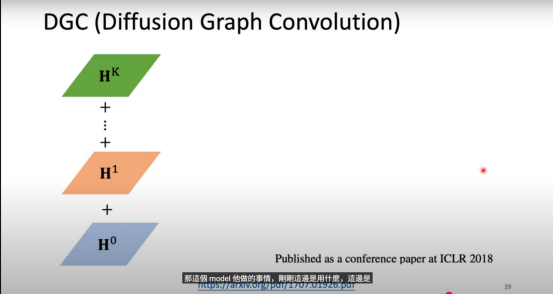
其中 常设为可学习权重或固定权重。这种方式在不增加维度的前提下融合多尺度信息,参数更少、稳定性更好。
MoNet(Mixture Model Networks)
MoNet 的核心思想是通过定义节点间的"距离"度量,使用加权聚合而非简单求和/平均来更新节点特征。
定义节点关系特征:
使用神经网络 根据关系特征动态计算权重。加权聚合公式(以 为例):
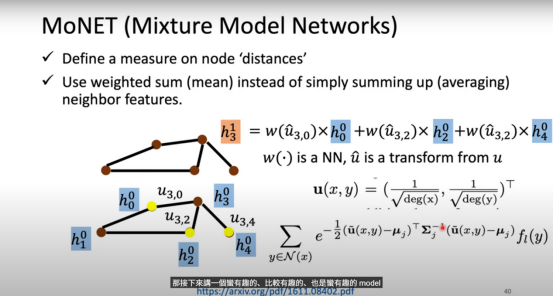
MoNet 能够捕捉图结构中的复杂关系,生成更具表达力的节点特征表示。
GraphSAGE(Graph Sample and Aggregate)
GraphSAGE 的核心思想是学习聚合函数而非为每个节点学习独立嵌入,从而实现归纳式学习(inductive learning),可处理未见节点。
算法流程:

三种聚合方式:
- Mean aggregator:邻居特征取平均
- Max-pooling aggregator:邻居先过 MLP,再做 element-wise max/mean
- LSTM aggregator:将邻居特征按随机顺序送入 LSTM,取输出
三步工作流程:
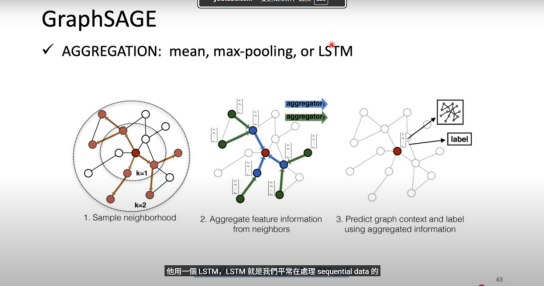
- Sample neighborhood(采样邻居): 采样直接邻居(1 跳), 采样 2 跳邻居,构建局部计算图
- Aggregate feature information(聚合邻居特征):信息从 2 跳邻居到 1 跳邻居再到中心节点,通过可学习的聚合函数汇聚特征
- Predict using aggregated information(预测):预测节点标签(节点分类)或预测图上下文(生成节点嵌入)
GraphSAGE 的优势在于归纳式学习,可处理未见节点,高效扩展到大型图,适用于节点分类、链接预测等任务。
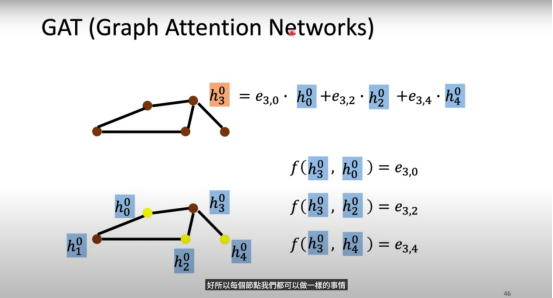
GAT(Graph Attention Networks)
GAT 的核心思想是在邻居信息汇聚时引入注意力机制,为不同邻居分配不同的权重。
1. 计算注意力分数对每条边 ,先对节点特征做线性变换 ,再拼接后计算:
其中 是可训练参数向量, 表示向量拼接。
2. 归一化注意力权重在节点 的邻居集合 上做 softmax:

反映了邻居 对 的重要程度。
3. 特征更新将邻居(以及自己)的特征按权重加权求和,再通过非线性激活函数:
多头注意力机制:
- 拼接(Concat):多个注意力头的输出在特征维度拼接,增加表达能力
- 均值(Mean):多个注意力头的输出按元素取平均,平滑结果
Readout 阶段:
- 节点级任务:直接使用最终层节点表示 进行分类或回归
- 图级任务:将所有节点的最终表示做置换不变池化(POOL),常见方式:Mean、Sum、Max、Attention Readout。得到图表示 后,再接 MLP / Softmax 得到输出
GIN(Graph Isomorphism Network)
GIN 的核心发现是使用 Sum 聚合优于 Mean 和 Max,因为求和可以区分多重集合(Multiset),其表达力与 Weisfeiler-Lehman(WL)同构测试等价。
节点特征更新(第 k 层):
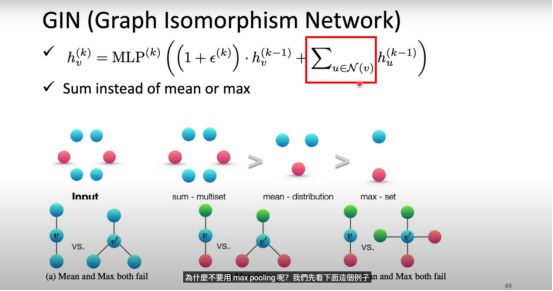
- 邻居信息聚合:使用求和(Sum)而非 mean / max。原因是求和可以区分多重集合,而 mean / max 在邻居重复时会丢失区分信息
- 自环权重: 为可学习标量(或常数),控制自身特征在更新时的权重
- MLP 更新:聚合结果经过多层感知机(MLP)提升非线性表达能力
Readout(图级表示):
采用置换不变池化(Permutation Invariant Pooling),常用求和池化,并进行层间融合:
对每一层的节点表示分别求和,再拼接,得到最终的图表示。图表示 输入 MLP / Softmax 进行分类或回归。
模型对比总结
| 模型 | 聚合方式 | 核心特点 |
|---|---|---|
| NN4G | 邻居求和 + 自身特征加权 | 分层 Readout,加权融合不同层 |
| DCNN | 基于距离的扩散聚合 | 多跳特征拼接 + 线性变换 |
| DGC | 同 DCNN | Readout 改为直接求和 |
| MoNet | 加权聚合(高斯混合权重) | 基于节点距离度量动态计算权重 |
| GraphSAGE | Mean / Max-pooling / LSTM | 归纳式学习,可处理未见节点 |
| GAT | 注意力加权聚合 | 多头注意力,自适应权重 |
| GIN | 求和聚合 + MLP | 表达力等价 WL 测试,理论最优 |
代码实战:GCN / GAT / GIN
使用 Cora 引文网络数据集进行节点分类任务,对比源代码实现与 PyG 简洁实现。
| 属性 | 值 |
|---|---|
| 节点数 | 2708(论文) |
| 边数 | 10556(引用关系,无向) |
| 节点特征维度 | 1433(词袋向量) |
| 类别数 | 7(论文主题) |
| 训练/验证/测试 | 140 / 500 / 1000(标准划分) |
数据准备与共享组件
import torch
from torch import nn
import torch.nn.functional as F
from torch_geometric.datasets import Planetoid
dataset = Planetoid(root='./data/Cora', name='Cora')
data = dataset[0].to(device)
HIDDEN_DIM = 64
NUM_HEADS = 4
DROPOUT = 0.5
LR = 0.01
WEIGHT_DECAY = 5e-4
NUM_EPOCHS = 200
IN_DIM = dataset.num_node_features # 1433
OUT_DIM = dataset.num_classes # 7
def train_node_clf(model, data, num_epochs, lr, weight_decay):
optimizer = torch.optim.Adam(
model.parameters(), lr=lr, weight_decay=weight_decay)
for epoch in range(num_epochs):
model.train()
out = model(data.x, data.edge_index)
loss = F.cross_entropy(out[data.train_mask], data.y[data.train_mask])
optimizer.zero_grad()
loss.backward()
optimizer.step()实现 A:源代码实现(From Scratch)
纯 PyTorch 手写三种 GNN 层,不依赖 torch_geometric.nn。
三种模型的核心区别在于 Aggregate 的方式:
| 模型 | 聚合方式 | 权重来源 | 理论表达力 |
|---|---|---|---|
| GCN | 对称归一化加权求和 | 固定(由节点度决定) | < 1-WL |
| GAT | 注意力加权求和 | 可学习(注意力机制) | < 1-WL |
| GIN | 直接求和 + MLP | 无权重(纯求和) | = 1-WL |
GCN(Graph Convolutional Network)
传播公式(Kipf & Welling, 2017):
其中 (添加自环的邻接矩阵),(对称归一化)消除节点度数差异的影响。
逐节点公式:
class GCNLayerScratch(nn.Module):
"""GCN 单层:对称归一化 + 线性变换。"""
def __init__(self, in_dim, out_dim):
super().__init__()
self.linear = nn.Linear(in_dim, out_dim, bias=False)
self.bias = nn.Parameter(torch.zeros(out_dim))
def forward(self, x, edge_index):
num_nodes = x.size(0)
# 添加自环:A_hat = A + I
self_loops = torch.arange(
num_nodes, device=x.device).unsqueeze(0).repeat(2, 1)
edge_index_hat = torch.cat([edge_index, self_loops], dim=1)
# 计算度 D_hat,PyG 约定:edge_index[0]=source, edge_index[1]=target
row, col = edge_index_hat[1], edge_index_hat[0]
deg = torch.zeros(num_nodes, device=x.device)
deg.scatter_add_(0, row, torch.ones(row.size(0), device=x.device))
# D^{-1/2}
deg_inv_sqrt = deg.pow(-0.5)
deg_inv_sqrt[deg_inv_sqrt == float('inf')] = 0.0
# 归一化系数:1 / sqrt(d_i * d_j)
norm = deg_inv_sqrt[row] * deg_inv_sqrt[col]
# 线性变换 X * W
x = self.linear(x)
# 消息传递:scatter_add 聚合归一化的邻居特征
out = torch.zeros_like(x)
out.scatter_add_(
0, row.unsqueeze(1).expand_as(x[col]), norm.unsqueeze(1) * x[col])
return out + self.bias
class GCNScratch(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim, dropout=0.5):
super().__init__()
self.conv1 = GCNLayerScratch(in_dim, hidden_dim)
self.conv2 = GCNLayerScratch(hidden_dim, out_dim)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=self.dropout, training=self.training)
return self.conv2(x, edge_index)GAT(Graph Attention Network)
注意力公式(Velickovic et al., 2018):
与 GCN 的关键区别:GCN 权重由节点度固定决定,GAT 权重由可学习的注意力机制动态计算。
class GATLayerScratch(nn.Module):
"""GAT 单头注意力层。"""
def __init__(self, in_dim, out_dim, negative_slope=0.2):
super().__init__()
self.W = nn.Linear(in_dim, out_dim, bias=False)
self.a_left = nn.Parameter(torch.zeros(out_dim, 1))
self.a_right = nn.Parameter(torch.zeros(out_dim, 1))
nn.init.xavier_uniform_(self.a_left)
nn.init.xavier_uniform_(self.a_right)
self.leaky_relu = nn.LeakyReLU(negative_slope)
def forward(self, x, edge_index):
num_nodes = x.size(0)
self_loops = torch.arange(
num_nodes, device=x.device).unsqueeze(0).repeat(2, 1)
edge_index = torch.cat([edge_index, self_loops], dim=1)
row, col = edge_index[1], edge_index[0]
Wh = self.W(x)
# e_ij = LeakyReLU(a_left^T Wh_target + a_right^T Wh_source)
e_left = (Wh @ self.a_left).squeeze(-1)
e_right = (Wh @ self.a_right).squeeze(-1)
e = self.leaky_relu(e_left[row] + e_right[col])
# Softmax 归一化(数值稳定)
e_max = torch.zeros(num_nodes, device=x.device)
e_max.scatter_reduce_(0, row, e, reduce='amax', include_self=False)
e_exp = torch.exp(e - e_max[row])
e_sum = torch.zeros(num_nodes, device=x.device)
e_sum.scatter_add_(0, row, e_exp)
alpha = e_exp / (e_sum[row] + 1e-16)
# 加权聚合
out = torch.zeros(num_nodes, Wh.size(1), device=x.device)
out.scatter_add_(
0, row.unsqueeze(1).expand_as(Wh[col]),
alpha.unsqueeze(1) * Wh[col])
return out
class GATScratch(nn.Module):
"""多头 GAT:中间层拼接,输出层取平均。"""
def __init__(self, in_dim, hidden_dim, out_dim, heads=4, dropout=0.5):
super().__init__()
self.heads1 = nn.ModuleList([
GATLayerScratch(in_dim, hidden_dim) for _ in range(heads)])
self.out_layer = GATLayerScratch(hidden_dim * heads, out_dim)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.dropout(x, p=self.dropout, training=self.training)
x = torch.cat([head(x, edge_index) for head in self.heads1], dim=-1)
x = F.elu(x)
x = F.dropout(x, p=self.dropout, training=self.training)
return self.out_layer(x, edge_index)GIN(Graph Isomorphism Network)
更新公式(Xu et al., 2019):
为什么 Sum > Mean > Max?[1,1,1]和[1]:Mean 无法区分(均为 1),Sum 可以(3 vs 1)[1,2,3]和[1,1,3]:Max 无法区分(均为 3),Sum 可以(6 vs 5)
class GINLayerScratch(nn.Module):
"""GIN 单层:Sum 聚合 + MLP 更新。"""
def __init__(self, in_dim, out_dim, train_eps=True):
super().__init__()
self.mlp = nn.Sequential(
nn.Linear(in_dim, out_dim), nn.ReLU(),
nn.Linear(out_dim, out_dim))
if train_eps:
self.eps = nn.Parameter(torch.zeros(1))
else:
self.register_buffer('eps', torch.zeros(1))
def forward(self, x, edge_index):
num_nodes = x.size(0)
row, col = edge_index[1], edge_index[0]
# Sum 聚合邻居特征
agg = torch.zeros(num_nodes, x.size(1), device=x.device)
agg.scatter_add_(
0, row.unsqueeze(1).expand_as(x[col]), x[col])
# (1 + eps) * h_self + sum(h_neighbors)
return self.mlp((1 + self.eps) * x + agg)
class GINScratch(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim, dropout=0.5):
super().__init__()
self.conv1 = GINLayerScratch(in_dim, hidden_dim)
self.conv2 = GINLayerScratch(hidden_dim, hidden_dim)
self.classifier = nn.Linear(hidden_dim, out_dim)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=self.dropout, training=self.training)
x = F.relu(self.conv2(x, edge_index))
return self.classifier(x)实现 B:简洁实现(PyTorch Geometric)
使用 torch_geometric.nn 的内置卷积层,代码量大幅减少。
from torch_geometric.nn import GCNConv, GATConv, GINConv
class GCNConcise(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim, dropout=0.5):
super().__init__()
self.conv1 = GCNConv(in_dim, hidden_dim)
self.conv2 = GCNConv(hidden_dim, out_dim)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=self.dropout, training=self.training)
return self.conv2(x, edge_index)
class GATConcise(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim, heads=4, dropout=0.5):
super().__init__()
self.conv1 = GATConv(in_dim, hidden_dim, heads=heads, dropout=dropout)
self.conv2 = GATConv(
hidden_dim * heads, out_dim, heads=1,
concat=False, dropout=dropout)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.dropout(x, p=self.dropout, training=self.training)
x = F.elu(self.conv1(x, edge_index))
x = F.dropout(x, p=self.dropout, training=self.training)
return self.conv2(x, edge_index)
class GINConcise(nn.Module):
def __init__(self, in_dim, hidden_dim, out_dim, dropout=0.5):
super().__init__()
mlp1 = nn.Sequential(
nn.Linear(in_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim))
mlp2 = nn.Sequential(
nn.Linear(hidden_dim, hidden_dim), nn.ReLU(),
nn.Linear(hidden_dim, hidden_dim))
self.conv1 = GINConv(nn=mlp1, train_eps=True)
self.conv2 = GINConv(nn=mlp2, train_eps=True)
self.classifier = nn.Linear(hidden_dim, out_dim)
self.dropout = dropout
def forward(self, x, edge_index):
x = F.relu(self.conv1(x, edge_index))
x = F.dropout(x, p=self.dropout, training=self.training)
x = F.relu(self.conv2(x, edge_index))
return self.classifier(x)结果对比
| 模型 | 源代码 Test Acc | PyG Test Acc |
|---|---|---|
| GCN | ~81% | ~81% |
| GAT | ~83% | ~83% |
| GIN | ~78% | ~78% |
| 对比维度 | GCN (2017) | GAT (2018) | GIN (2019) | GraphSAGE (2017) |
|---|---|---|---|---|
| 聚合方式 | 对称归一化 | 注意力加权 | Sum + MLP | Mean/Max/LSTM |
| 权重类型 | 固定(度数) | 可学习 | 无(纯求和) | 可学习 |
| 理论表达力 | < 1-WL | < 1-WL | = 1-WL | < 1-WL |
| Inductive | 否 | 是 | 是 | 是 |
| 最佳场景 | 同质图节点分类 | 异质图 | 图分类 | 大规模图 |
GNN 的创新点
- 数据表示的普适性:只要数据可以表示为图结构,GNN 就能处理
- 处理不规则结构数据:与处理规则结构数据(如网格状图像或序列化文本)的传统神经网络不同,GNN 特别适合处理不规则连接结构的数据
- 关系学习:GNN 能够显式地学习和利用实体之间的关系
- 与其他架构的联系:GNN 与 RNN、CNN 和 Transformer 等架构存在内在联系,展示了神经网络设计的统一性
参考资料
- 李宏毅机器学习 2020 TA 补充课:Graph Neural Network (1/2)、Graph Neural Network (2/2)
- 李沐论文精读:A Gentle Introduction to Graph Neural Networks
- Distill:A Gentle Introduction to Graph Neural Networks