Improving Language Understanding by Generative Pre-Training
Alec Radford, Karthik Narasimhan, Tim Salimans, Ilya Sutskever — 2018 (OpenAI)
GPT-1 在大语言模型发展史上的意义,并不只是“OpenAI 做了一个 Transformer 语言模型”,而是它第一次系统证明:无监督预训练得到的语言表示,可以迁移到多种下游任务。这篇论文把“先在大规模无标注文本上学语言,再在具体任务上微调”的路线真正确立下来,成为后续 BERT、GPT-2、GPT-3 乃至整个预训练语言模型时代的起点。
如果把 Transformer 看作一种网络结构,那么 GPT-1 的真正贡献更像是一种训练范式创新。它告诉研究者:语言本身就是最丰富的监督信号,只要先把“根据前文预测后文”这件事做好,模型就能获得可迁移的通用语言能力。这一思想后来演化为今天几乎所有大模型工作的基础逻辑。
研究动机
在 GPT-1 提出之前,NLP 的主流做法往往严重依赖任务特定结构和标注数据。情感分析、蕴含判断、问答、文本分类等任务通常需要分别设计模型,而高质量标注数据又往往有限,这导致模型很难获得真正通用的语言能力。
GPT-1 的出发点是:如果语言模型本身能在海量文本中学到语法、常识和上下文关系,那么这些知识应该可以迁移到下游任务。因此论文提出两阶段学习框架:
- 无监督预训练:先在大规模无标注语料上做语言建模
- 有监督微调:再把预训练好的模型迁移到具体任务上
在无监督预训练阶段,对于一个无标注词序列 ,GPT-1 最大化标准语言建模目标:
这里的核心不是某个具体损失公式,而是这个训练目标迫使模型不断回答一个问题:给定历史上下文,下一个词最可能是什么。为了做好这件事,模型必须逐渐吸收语言结构与世界知识。
核心方法/模型架构
GPT-1 使用的是 Decoder-only Transformer。与原始 Transformer 的 Encoder-Decoder 结构不同,它只保留解码器部分,并通过因果掩码保证每个位置只能看到自己和之前的 token,因此天然适合生成式语言建模。
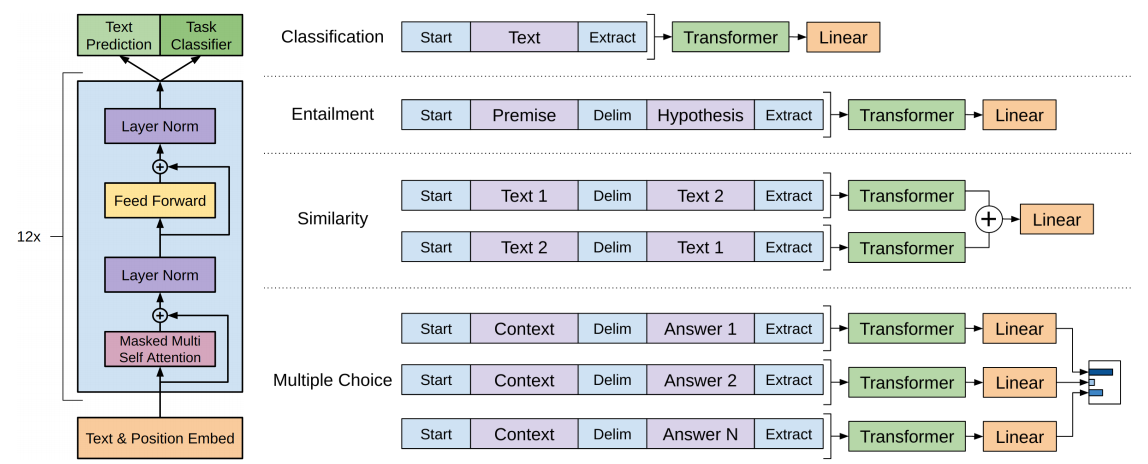
论文中的 GPT-1 由 12 层 Transformer 解码器堆叠而成,总参数量约 1.17 亿。每一层都包含:
- Masked Multi-Head Self-Attention
- Feed-Forward Network
- Residual Connection + LayerNorm
其最关键的约束是因果性。对于位置 ,模型只能使用 来预测 ,不能“偷看未来”。因此 GPT-1 的预测本质是:
其中 是当前位置在多层解码器处理后的隐藏表示, 是输出投影矩阵。这个单向、自回归的约束,使 GPT-1 与后来的 BERT 形成了非常鲜明的范式分野。
组件详解
两阶段学习框架:预训练先学语言,微调再学任务
GPT-1 最值得记住的不是网络层数,而是“两阶段学习”本身。
第一阶段,模型在 BookCorpus 这类大规模无标注语料上学习语言建模;第二阶段,再将同一个模型迁移到下游任务上。这种设计的关键优点是:大量无标注文本负责提供通用语言知识,少量有标注数据负责把这种能力适配到特定目标。
微调阶段的任务目标记为:
同时,论文还保留了语言建模辅助目标作为正则化项,最终得到:
这个设计非常重要。它说明 GPT-1 并不是把预训练阶段和微调阶段彻底切开,而是在微调时继续保留语言建模目标,以减轻灾难性遗忘并帮助泛化。
Decoder-only Transformer:为什么 GPT 天然适合生成
GPT-1 只使用 Transformer 解码器,而不用完整的编解码器结构。这种选择和预训练目标高度一致:模型要做的是“根据前文生成后文”,因此最自然的结构就是单向解码器。
在 Decoder-only 结构中,每个位置都只能访问过去信息,这一点通过 masked self-attention 实现。若忽略多头细节,注意力可写成:
其中 是因果掩码。这个掩码保证未来位置的注意力分数被屏蔽,从而让训练条件与推理条件保持一致。没有它,模型训练时就会直接看到未来 token,得到虚假的低损失,但推理时却无法复现同样的信息条件。
下游任务适配:统一输入格式而不是为每个任务重写模型
GPT-1 的另一个关键贡献,是用统一输入模板把不同 NLP 任务映射到同一个 Transformer 框架中。论文引入了 [Start]、[Delim]、[Extract] 等特殊令牌,用来组织分类、蕴含、相似度、多项选择等任务。
例如:
- 分类任务:
[Start] [Text] [Extract] - 蕴含任务:
[Start] [Premise] [Delim] [Hypothesis] [Extract] - 多项选择任务:把上下文与每个候选答案分别拼接成独立序列
其中 [Extract] 的角色尤其重要。它在输入时只是一个特殊 token,但经过多层 Transformer 后,会逐渐吸收整个序列的上下文信息,最终成为一个可用于分类的摘要向量。这个思想和后来的 [CLS] 类似,本质上都是为“序列级预测”预留一个聚合位置。
GPT-1 与 BERT:单向生成式 vs 双向编码式
GPT-1 与 BERT 经常被并列讨论,因为两者都属于预训练语言模型时代的奠基工作,但它们的核心路线不同。
| 特性 | BERT | GPT-1 |
|---|---|---|
| 模型结构 | Transformer 编码器(双向) | Transformer 解码器(单向) |
| 预训练任务 1 | 遮盖语言模型(MLM) | 标准语言模型(预测下一个词) |
| 预训练任务 2 | 下一句预测(NSP) | 无 |
| 核心优势 | 真正的双向语境理解能力 | 强大的文本生成能力 |
| 微调分类 | 使用 [CLS] 标记的输出 | 使用 [Extract] 标记的输出 |
这张表最值得关注的不是“谁更强”,而是两者对语言建模问题的不同切法。BERT 更强调双向理解,GPT-1 更强调单向生成;二者后来分别影响了理解型模型与生成型模型的发展路径。
实验结果
GPT-1 在自然语言推断、问答、文本分类等多个任务上都取得了当时有竞争力的结果。更重要的是,它几乎不依赖任务专门设计的复杂结构,而是用统一的预训练模型加少量适配,就能在多个 benchmark 上取得提升。
这意味着论文验证了三个关键结论:
- 生成式预训练确实能学到可迁移的语言知识
- 同一个预训练模型可以适配多种不同 NLP 任务
- 无监督语料的规模价值极高,并不一定非要依赖大规模标注数据
从今天回看,这篇论文最重要的实验结论并不是某个数据集上的具体分数,而是它建立了一个后来被反复验证的基本事实:语言模型预训练本身就是一种强监督。
总结
GPT-1 的历史意义在于,它把 Decoder-only Transformer 和“无监督预训练 + 有监督微调”这两条思路结合起来,首次系统展示了生成式预训练的迁移能力。它不仅推动了 GPT 系列的发展,也深刻影响了整个预训练语言模型时代的研究范式。
如果说 Transformer 提供了结构上的可能性,那么 GPT-1 证明了这种结构在大规模文本预训练下具有通用迁移价值。后来的 GPT-2、GPT-3、InstructGPT 乃至 ChatGPT,虽然规模、训练目标和使用方式都发生了巨大变化,但它们的根仍然可以追溯到 GPT-1 在 2018 年确立的这条路线。
代码实战
为了把 GPT-1 的核心思想讲清楚,我配套实现了一份教学型 Notebook。它没有尝试复现论文中 12 层、1.17 亿参数的大规模设定,而是使用一个小型字符级语言建模任务,专注演示三件最核心的事情:Decoder-only 架构、因果掩码约束,以及训练与推理方式的差异。
完整代码实战:
![]()
Notebook 里最重要的第一部分,是手写的 masked self-attention。它把 GPT-1 的“不能看未来”这件事直接落实到代码里:
class CausalSelfAttention(nn.Module):
def __init__(self, d_model: int, num_heads: int, seq_len: int, dropout: float = 0.1):
super().__init__()
assert d_model % num_heads == 0
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.qkv_proj = nn.Linear(d_model, 3 * d_model)
self.out_proj = nn.Linear(d_model, d_model)
causal_mask = torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()
self.register_buffer('causal_mask', causal_mask)
def forward(self, x: torch.Tensor, return_attention: bool = False):
batch_size, seq_len, d_model = x.shape
qkv = self.qkv_proj(x)
q, k, v = qkv.chunk(3, dim=-1)
q = q.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
k = k.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
v = v.view(batch_size, seq_len, self.num_heads, self.head_dim).transpose(1, 2)
scores = (q @ k.transpose(-2, -1)) / math.sqrt(self.head_dim)
scores = scores.masked_fill(self.causal_mask[:seq_len, :seq_len], float('-inf'))
attn = F.softmax(scores, dim=-1)
out = attn @ v
return out第二部分是从零手写 GPT-1 主体结构。Notebook 显式实现了 token embedding、learned positional embedding、Transformer block 和语言模型头,把 Decoder-only GPT 的最小计算图摊开来讲清楚。
class GPT1FromScratch(nn.Module):
def __init__(self, vocab_size: int, d_model: int, num_heads: int,
num_layers: int, d_ff: int, seq_len: int, dropout: float = 0.1):
super().__init__()
self.token_embedding = nn.Embedding(vocab_size, d_model)
self.position_embedding = nn.Embedding(seq_len, d_model)
self.blocks = nn.ModuleList([
GPT1Block(d_model, num_heads, d_ff, seq_len, dropout)
for _ in range(num_layers)
])
self.lm_head = nn.Linear(d_model, vocab_size, bias=False)
def forward(self, idx: torch.Tensor) -> torch.Tensor:
batch_size, seq_len = idx.shape
positions = torch.arange(seq_len, device=idx.device).unsqueeze(0)
x = self.token_embedding(idx) + self.position_embedding(positions)
for block in self.blocks:
x = block(x)
logits = self.lm_head(x)
return logits第三部分是训练与推理的差异。训练阶段使用 Teacher Forcing,一次输入完整前文并并行预测每个位置的下一个 token;推理阶段则从 prompt 开始,每次只生成 1 个 token,再把结果接回输入,形成自回归循环。这也是 GPT 类模型最容易在面试里被问到、但又最容易讲不清的一点。
此外,Notebook 还额外给出了一条工程路径:使用 nn.TransformerEncoderLayer 和因果掩码来实现同样的 GPT-1 思想。这样可以把“手写原理实现”和“工程 API 封装实现”建立一一对应关系,更适合从学习过渡到项目实践。
参考文献
- Radford, A., Narasimhan, K., Salimans, T., & Sutskever, I. (2018). Improving Language Understanding by Generative Pre-Training. OpenAI.
- Jay Alammar. The Illustrated GPT-2.
- Sebastian Raschka. Understanding Decoder-Only Transformers.
- 李沐. GPT,GPT-2,GPT-3 论文精读. Bilibili.