GPT-3 的历史地位,不只是“把 GPT-2 做得更大”,而是它第一次系统证明:当 decoder-only Transformer 的参数规模、数据规模和训练算力跨过某个阈值后,同一个固定模型可以仅凭上下文中的任务描述和少量示例,表现出可用的少样本学习能力。后来人们熟悉的 Prompt、few-shot、指令接口和大模型通用能力,几乎都能追溯到这篇论文。
如果说 GPT-2 把 NLP 从“预训练 + 微调”推进到了“Prompt 可以作为任务接口”,那么 GPT-3 则进一步回答了一个更关键的问题:模型是否可以在不更新参数的情况下,只通过上下文示例理解任务并执行任务。论文给出的答案是肯定的,而这也是大语言模型时代真正开始的标志。
研究动机
GPT-3 想解决的核心矛盾,是传统微调范式的高成本与低通用性。
在 GPT-3 之前,主流做法通常是先预训练一个语言模型,再针对翻译、问答、分类、摘要等具体任务分别微调。这个范式虽然有效,但存在三个明显问题:
- 每个任务都要重新训练:需要额外标注数据、任务头和训练流程。
- 新任务迁移门槛高:能否解决一个问题,往往取决于是否有对应数据集,而不是模型能否从自然语言描述中理解任务。
- 模型副本难以统一:不同任务往往对应不同参数版本,部署和维护成本持续上升。
GPT-3 的研究动机,就是把这些看似不同的任务统一改写成“给定上下文,继续生成”的同一种接口。只要 Prompt 里已经给出任务描述和示例,模型就不必再通过梯度更新来适配任务,而是直接在推理时从上下文中读取模式。
从这个角度看,GPT-3 真正验证的不是“某一个 benchmark 的分数能否再涨一点”,而是 语言模型能否成为一个统一的通用任务接口。
核心方法/模型架构
从结构上看,GPT-3 并没有提出全新的神经网络骨架,它仍然建立在 decoder-only Transformer 之上。模型训练目标依旧是最经典的自回归语言建模:
这意味着 GPT-3 在训练时做的事情始终只有一件:根据前文预测下一个 token。它之所以能迁移到翻译、问答、摘要、分类等任务,并不是因为训练目标被改成了多任务监督学习,而是因为这些任务都可以被重写成文本输入到文本输出的形式。
GPT-3 的真正创新,体现在三个层面:
- 模型规模:把参数规模扩展到 1750 亿级别,使模型能够容纳更丰富的模式与更强的上下文建模能力。
- 数据工程:不仅用更大的语料训练,还系统加入质量过滤、去重和污染检测,降低“垃圾数据”和 benchmark 泄漏带来的伪提升。
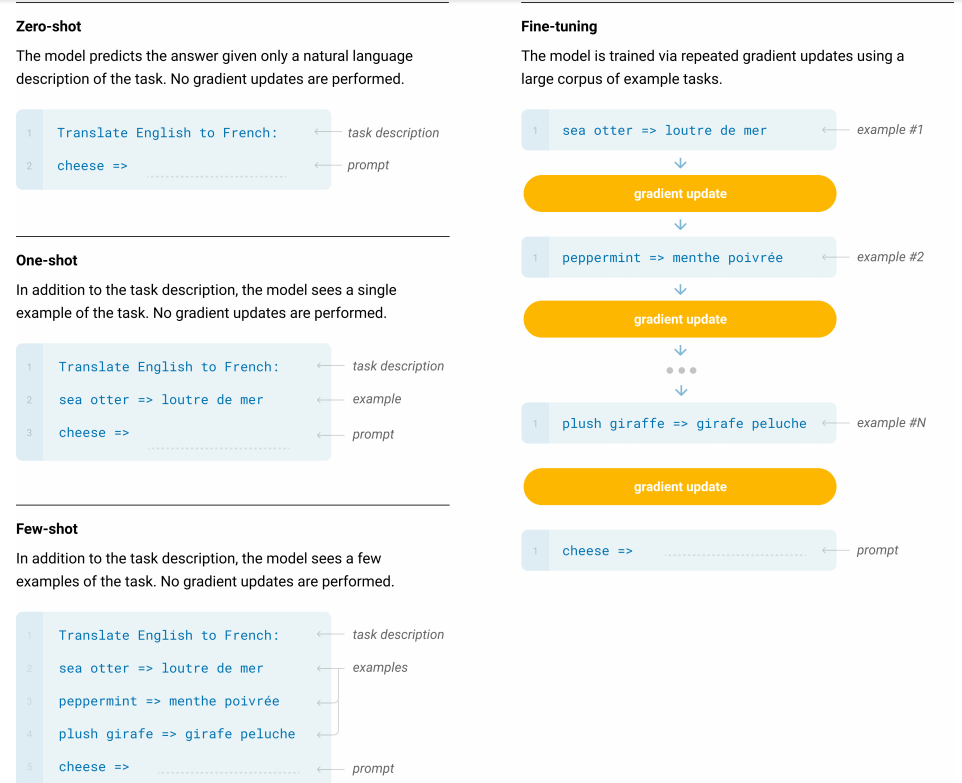
- 评估方式:用 zero-shot、one-shot、few-shot 三种设定去评估模型,而不是默认每个任务都可以微调参数。
这三点合在一起,才构成了 GPT-3 的完整方法论。单看结构,它仍然像一个“大很多的 GPT-2”;但结合训练数据、训练规模和评估范式,它已经是“大语言模型”这个时代的起点。
下表可以把 GPT-3 的三种任务使用方式看得更清楚:
| 设定 | 输入里是否含示例 | 是否更新参数 | 典型使用方式 |
|---|---|---|---|
| zero-shot | 否 | 否 | 只写任务描述 |
| one-shot | 是,1 个 | 否 | 给 1 个演示样本 |
| few-shot | 是,多个 | 否 | 给多个输入输出示例 |
组件详解
情境学习:上下文替代参数更新
GPT-3 最重要的能力,是 情境学习。所谓 few-shot,不是模型在推理时偷偷做了梯度下降,而是模型在注意力机制的作用下,把上下文里的示例当作“任务模板”来读取。
例如,当 Prompt 写成下面这种形式时:
Translate English to French:
sea otter => loutre de mer
cheese => fromage
apple =>模型在生成最后一行答案时,并不会学到一个新的语言知识点;它更像是在当前上下文中识别出“英文词 -> 法文词”的格式模式,并据此继续补全。也就是说,few-shot 学到的不是新参数,而是 当前这次推理应该遵循什么行为模式。
decoder-only Transformer 与因果注意力
GPT-3 能做到这一点,底层依赖的仍然是 Transformer 的因果自注意力。其核心形式可以写成:
其中 是因果 mask,用来保证当前位置只能看到自己左侧已经出现的 token,而不能偷看未来信息。这个限制决定了 GPT-3 的训练和推理始终遵守同一种自回归逻辑:从已有上下文中提取模式,再生成下一个 token。
因此,GPT-3 的 few-shot 行为并不神秘。只要上下文里已经展示了足够清晰的输入输出格式,注意力层就会把当前 query 和前面的示例建立关联,进而产生看起来像“临时学会了任务”的效果。
数据质量过滤:先筛选再训练
GPT-3 的另一个关键贡献,不在模型内部,而在训练数据的入口处。论文并没有把原始 Common Crawl 直接喂给模型,而是先构造高质量文本的判别标准,用自动化方式筛掉大量噪声网页、广告页面和低信息密度文本。
这一步之所以重要,是因为大模型不是“数据越多越好”,而是“高质量、低重复、低污染的数据越多越好”。如果语料里充满重复、垃圾或模板化内容,模型学到的将更多是噪声模式,而不是可迁移的知识结构。
LSH 去重:让海量网页变得可处理
当训练语料扩展到数十亿级文档时,单纯做精确去重已经不够了,因为真正棘手的问题是“近重复”。两篇网页哪怕只改了标题、广告段或局部措辞,也可能在语义和结构上高度相似。
GPT-3 论文采用的思路,是利用 局部敏感哈希 来近似寻找这些相似文档。其直觉可以概括为三步:
- 把文本切成 shingle 集合,得到局部片段表示。
- 用 MinHash 把大集合压缩成短签名,保留近似相似度信息。
- 用 banding 机制快速筛出候选相似对,只对可疑样本做进一步比较。
这样做的价值,在于把原本近乎不可计算的全量两两比较,压缩成一个工程上可运行的数据清洗流程。对 GPT-3 这种规模的模型来说,这不是优化细节,而是能否训练的前提条件之一。
污染检测:保证评测可信
如果训练集里混入了 benchmark 测试题,模型的高分就可能只是“见过答案”,而不是具备真正的泛化能力。GPT-3 论文因此专门强调了 contamination removal。
其核心做法,是把测试集文本切成大量 n-gram 指纹,再去扫描训练语料。一旦某篇训练文档与 benchmark 文本存在显著重叠,就将其剔除。这个过程不会提升模型能力本身,但会显著提升评测结果的可信度。
在今天回看,这一点非常重要:大模型时代不仅要讨论能力上限,也必须讨论评测是否公平。GPT-3 把这一问题放到台面上,等于提前暴露了后续所有大模型研究都会面对的评估难题。
实验结果
GPT-3 的实验结论,可以概括成三个层次。
第一,随着模型规模增大,few-shot 相比 zero-shot 和 one-shot 的优势会更稳定地显现出来。这说明上下文示例并不是可有可无的提示装饰,而是在大模型中真正成为了一种任务适配机制。
第二,对翻译、问答、完形填空、格式化生成等任务来说,Prompt 已经足以承担过去一部分“微调”的角色。虽然 GPT-3 还远不能在所有任务上完全替代有监督训练,但它已经证明:参数更新不再是调用模型能力的唯一入口。
第三,论文也暴露了明显边界。GPT-3 仍然会出现事实错误、脆弱推理、任务不稳定和高昂计算成本等问题。换句话说,这篇论文真正开启的是“大模型范式”,而不是“一篇论文解决了通用智能”。
总结
GPT-3 的核心贡献,不是发明了一种全新的网络结构,而是把已有的 decoder-only Transformer 推到足够大的规模,并配套更严格的数据工程与更贴近真实使用方式的评估体系,从而让 Prompt 变成了模型接口,few-shot 变成了可用能力。
它让研究者第一次清楚看到:当模型规模、数据质量和上下文设计共同到位时,同一个语言模型可以不依赖任务专属微调,而是通过自然语言交互完成越来越多的工作。这也是后续 InstructGPT、ChatGPT 与各类 Agent 系统得以成立的出发点。
代码实战
如果只看论文结论,很容易把 GPT-3 理解成“参数变大了,所以效果更好了”。但真正值得动手的部分有两条:一条是 few-shot 推理为什么成立,另一条是训练数据为什么必须做质量过滤、去重和污染检测。下面的 Notebook 就沿着这两条线并行展开。
完整代码实战:
![]()
学习路径:先把 Prompt 和因果约束讲清楚
第一段代码把 few-shot Prompt 组织成统一输入格式,并用一个最小版本的因果 mask 演示“当前位置不能看未来 token”这件事。它对应的是 GPT-3 成立的最小理论骨架:上下文里放示例,模型就会在因果注意力约束下读取这些示例并继续生成。
def format_prompt(task_desc, examples, query, separator='=>'):
parts = [task_desc.strip()] if task_desc else []
for inp, out in examples:
parts.append(f'{inp} {separator} {out}')
parts.append(f'{query} {separator}')
return '\n'.join(parts)
def causal_mask(seq_len):
return torch.triu(torch.ones(seq_len, seq_len), diagonal=1).bool()学习路径:用小型数据工程模块复现论文思路
第二段代码不是训练 GPT-3 本体,而是复现论文里更容易被忽略、但同样关键的数据工程部分。这里用 TF-IDF + LogisticRegression 去模拟“高质量文本过滤器”,用最小可运行版本展示为什么 GPT-3 不是简单把 Common Crawl 全量拿来训练。
quality_clf = LogisticRegression(max_iter=200, random_state=SEED)
quality_clf.fit(X_train, y_train)
y_pred = quality_clf.predict(X_test)
y_prob = quality_clf.predict_proba(X_test)[:, 1]
print('=== Quality Filter Report ===')
print(classification_report(y_test, y_pred, target_names=['low', 'high']))
print('Accuracy:', round(accuracy_score(y_test, y_pred), 4))紧接着,Notebook 还补了一段污染检测函数,用 n-gram 重叠率去模拟 benchmark 泄漏检查。它对应的是 GPT-3 论文里非常重要但经常被忽略的一点:评测分数只有在训练集足够干净时才有意义。
def build_ngram_index(texts, n=3):
index = set()
for text in texts:
words = text.lower().split()
for i in range(len(words) - n + 1):
index.add(tuple(words[i:i+n]))
return index
def contamination_score(train_text, ngram_index, n=3):
words = train_text.lower().split()
if len(words) < n:
return 0.0
grams = [tuple(words[i:i+n]) for i in range(len(words) - n + 1)]
hits = sum(gram in ngram_index for gram in grams)
return hits / len(grams)工程路径:直接调用成熟库做自回归推理
第三段代码对应工程路径。真实项目里通常不会自己手写完整 GPT-3,而是直接调用成熟库,把 Prompt 送进 generate()。这段实现展示了 HuggingFace 风格的最小推理链路:加载模型、编码输入、逐 token 生成输出。
MODEL_NAME = 'openai-community/gpt2'
tokenizer = AutoTokenizer.from_pretrained(MODEL_NAME)
model = AutoModelForCausalLM.from_pretrained(MODEL_NAME).to(device)
model.eval()
if tokenizer.pad_token is None:
tokenizer.pad_token = tokenizer.eos_token
def hf_generate(prompt, max_new_tokens=GEN_MAX_NEW_TOKENS, temperature=0.7, do_sample=True):
encoded = tokenizer(prompt, return_tensors='pt', padding=False).to(device)
generate_kwargs = dict(
**encoded,
max_new_tokens=max_new_tokens,
do_sample=do_sample,
pad_token_id=tokenizer.pad_token_id,
eos_token_id=tokenizer.eos_token_id,
use_cache=True,
)
if do_sample:
generate_kwargs['temperature'] = temperature
with torch.no_grad():
output = model.generate(**generate_kwargs)
prompt_len = encoded['input_ids'].shape[1]
new_tokens = output[0, prompt_len:]
return tokenizer.decode(new_tokens, skip_special_tokens=True).strip()如果你把这三段代码连起来看,会发现它们分别对应 GPT-3 的三个核心问题:Prompt 怎样组织、数据怎样清洗、工业推理怎样调用。这也是理解 GPT-3 最有效的方式:不要把它只当作一个巨大参数数字,而要把它看成“模型规模 + 数据工程 + 上下文接口”共同成立的系统。
参考文献
- Tom B. Brown et al. Language Models are Few-Shot Learners. NeurIPS 2020. https://arxiv.org/abs/2005.14165
- GPT-3 配套代码实战 Notebook. https://colab.research.google.com/github/yunshenwuchuxun/yunshen-blogv1/blob/main/papers/GPT3/code.ipynb
- 李沐. GPT,GPT-2,GPT-3 论文精读. Bilibili.