GroupViT: Semantic Segmentation Emerges from Text Supervision
Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang — CVPR 2022 (UC San Diego / NVIDIA)
GroupViT 是视觉-语言模型进入分割任务的一篇代表性工作。它最有意思的地方不在于“把 CLIP 用到分割上”,而在于它在图像编码器内部显式加入了分组机制,使模型即便只接受图文配对监督,也能逐步学出与语义对象对应的区域结构。
从历史位置看,这篇工作连接了两个方向:一边是 CLIP 一类图文对比学习模型提供的开放词汇语义,另一边是语义分割所需要的区域级结构归纳偏置。GroupViT 的核心贡献,就是证明这两者不一定要依赖像素级掩模监督才能结合起来。
研究动机
在 GroupViT 之前,开放词汇或 zero-shot 分割通常仍然高度依赖带标注的分割数据。比如一些方法会借助文本特征提升类别泛化能力,但训练阶段本质上还是监督式语义分割:模型仍然需要 segmentation mask,文本更多是在“增强类别语义”,而不是取代像素标注。
这带来两个直接问题:
- 监督成本高:像素级标注远比图文配对昂贵,大规模扩展困难。
- 类别迁移受限:即便模型引入文本语义,训练分布仍然容易被有标注数据集绑定。
GroupViT 的思路更激进:既然 CLIP 可以只通过图文对齐学到强语义表示,那么能不能在视觉编码器里加入一种“区域分组”机制,让模型为了更好地和文本对齐,自己长出可分割的语义区域?
论文给出的答案是可以。它不再把图像表示固定为规则 patch 网格,而是通过可学习的 group tokens 和层级 grouping,让 patch 逐步聚合为更大的语义片段,再把这些语义片段与文本特征对齐。
核心方法 / 模型架构
GroupViT 可以看成在 ViT 上加入了层级分组结构的视觉编码器,并与文本编码器一起进行图文对比学习。
整体流程可以概括为三步:
- 图像先被切成 patch,并编码成 patch tokens;
- 模型引入多个可学习的 group tokens,通过 grouping block 把 patch 逐步分配到不同 group;
- 最终得到的图像表示与文本表示做对比学习训练,推理时再把 group 的类别分数回投到 patch 或 pixel,得到分割图。
下面这张图把训练主干和 Grouping Block 的内部计算放在了一起:左侧展示了从 image tokens 到 segment tokens、再到图文对比学习损失的整体训练路径;右侧则单独展开了 Grouping Block,强调它如何通过线性投影、相似度计算和 Gumbel-Softmax 完成 patch 到 group 的分配。
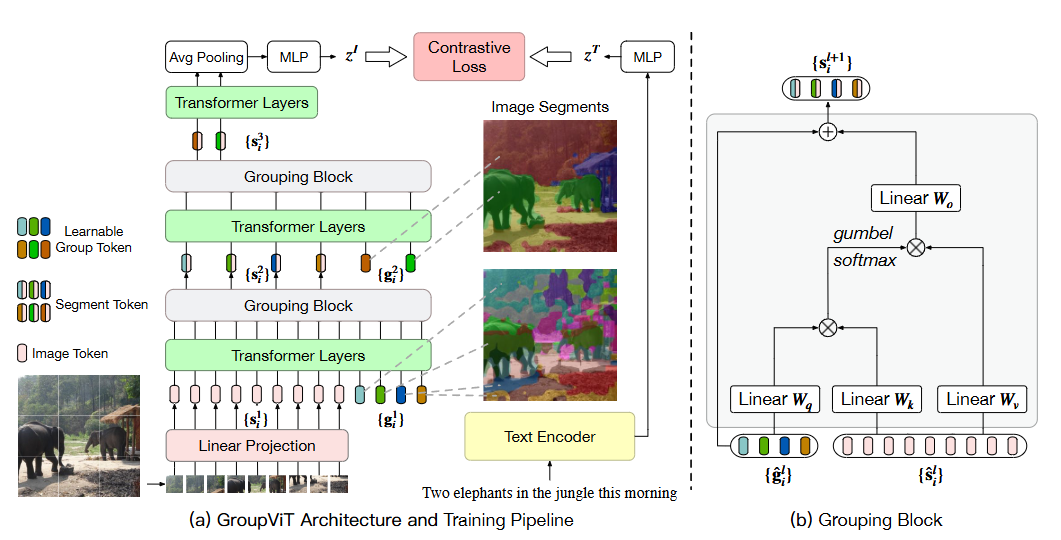
与普通 ViT 相比,最关键的变化有两点:
- 表示空间从规则网格走向不规则区域:模型不再只保留固定 patch 序列,而是允许 token 被聚合成任意形状的区域。
- 监督信号来自文本而非掩模:训练目标仍是图文匹配,但区域结构在这个过程中自然涌现。
如果把输入图像记为 ,经过 patch embedding 后可得到:
其中 是 patch 数量, 是 token 维度。后续的 GroupViT 不再直接在这组 patch token 上结束,而是继续引入 group tokens 做层级聚合。
组件详解
Patch Embedding:先保留 ViT 的基础输入形式
GroupViT 的输入阶段与 ViT 基本一致:先把图像切成 patch,再映射到统一维度。这样做的原因很直接,Transformer 擅长处理序列,而 patch embedding 正是把二维图像转成序列表示的标准接口。
在实战 notebook 中,这一部分被实现为一个最小版 PatchEmbedding:
class PatchEmbedding(nn.Module):
def __init__(self, img_size=224, patch_size=16, in_channels=3, embed_dim=64):
super().__init__()
self.grid_size = img_size // patch_size
self.num_patches = self.grid_size * self.grid_size
self.proj = nn.Conv2d(in_channels, embed_dim, kernel_size=patch_size, stride=patch_size)
self.pos_embed = nn.Parameter(torch.randn(1, self.num_patches, embed_dim) * 0.02)
def forward(self, pixel_values):
x = self.proj(pixel_values)
x = x.flatten(2).transpose(1, 2)
x = x + self.pos_embed
return x这一步的重点不是创新,而是为后续 grouping 提供统一的 patch token 序列。
Group Tokens:把聚类中心变成可学习参数
普通分类 ViT 往往只需要一个全局 token,但分割任务天然包含多个语义区域,因此 GroupViT 为每个阶段都引入多个 group tokens,把它们作为“可学习的聚类中心”。
可以把这一步记为:
这里的 group token 可以类比分类任务中的 cls token:它不是直接对应某个类别,而是作为一组可学习的“语义槽位”参与自注意力计算,逐步学会哪些 patch 应该归属于哪个 group。
以论文里常见的设置为例,如果输入图像大小为 ,图像编码器选用 ViT-Small/16,那么:
| 对象 | 记号 | 形状 | 含义 |
|---|---|---|---|
| patch tokens | 由 个 patch 展平后得到的图像 token 序列 | ||
| 第一阶段 group tokens | 第一层 grouping 使用的可学习聚类中心 |
这一步的直觉非常重要:模型不是在固定网格上直接预测每个 patch 的标签,而是先问“哪些 patch 应该属于同一个语义槽位”。
Grouping Block:真正完成区域分配的核心模块
Grouping Block 是整篇论文最关键的创新。它根据 patch token 与 group token 之间的相似度,决定每个 patch 应该被分配给哪个 group,再把属于同一组的 patch 聚合为新的 group 表示。
相似度矩阵可写为:
训练时,论文使用近似离散但可导的分配方式:
推理时,则改为真正的硬分配:
完成分配后,再将同组 patch 聚合成新的 group 表示:
如果把这一步展开成更接近实现的流程,可以理解为:
- 用 group tokens 与图像 patch tokens 计算相似度;
- 得到分配矩阵后,把 196 个 patch 分配到 64 个 group 上;
- 为了让分配过程可训练,使用 Gumbel-Softmax 代替不可导的 argmax;
- 聚合后得到新的 segment tokens,记为 。
实战 notebook 中的 toy 版本保留了这条主线:
class GroupingBlock(nn.Module):
def __init__(self, embed_dim):
super().__init__()
self.norm_image = nn.LayerNorm(embed_dim)
self.norm_group = nn.LayerNorm(embed_dim)
self.scale = embed_dim ** -0.5
self.refine = nn.Sequential(
nn.Linear(embed_dim, embed_dim * 2),
nn.GELU(),
nn.Linear(embed_dim * 2, embed_dim),
)
self.out_norm = nn.LayerNorm(embed_dim)
def forward(self, image_tokens, group_tokens, training=True):
image_tokens = self.norm_image(image_tokens)
group_tokens = self.norm_group(group_tokens)
scores = torch.matmul(image_tokens, group_tokens.transpose(-1, -2)) * self.scale
if training:
assign_matrix = F.gumbel_softmax(scores, tau=1.0, hard=True, dim=-1)
else:
assign_matrix = F.one_hot(
scores.argmax(dim=-1),
num_classes=group_tokens.shape[1],
).float()
assign_norm = assign_matrix / (assign_matrix.sum(dim=1, keepdim=True) + 1e-6)
new_groups = torch.matmul(assign_norm.transpose(1, 2), image_tokens)
new_groups = new_groups + self.refine(self.out_norm(new_groups))
return new_groups, assign_matrix理解这段代码时,最重要的不是每个张量细节,而是它体现了一个结构性变化:视觉表示从“规则 patch 网格”转向了“可学习的区域槽位”。
Hierarchical Grouping:从局部块到完整语义对象
GroupViT 不是只做一次 grouping,而是分阶段逐步合并。浅层更多形成纹理或局部部件,深层再把这些局部结构合并成更完整的语义对象。
按你给的原始笔记描述,训练过程可以概括成下面三步:
| 阶段 | 输入表示 | 操作 | 输出表示 |
|---|---|---|---|
| Stage 1 | patch tokens: + 第一阶段 group tokens: | 经过 6 层 Transformer 后做一次 grouping | segment tokens: |
| Stage 2 | segment tokens: + 第二阶段 group tokens: | 再经过 3 层 Transformer 后做第二次 grouping | 高层语义 tokens: |
| Global pooling | 最后一层输出序列: | Avg Pooling + MLP | 图像全局特征 |
也就是说,GroupViT 的层级 grouping 不是简单聚类一次就结束,而是通过“Transformer 编码 → grouping → Transformer 编码 → grouping”的方式,逐步把局部 patch 合并成更高层语义区域。
如果把这个过程写成更紧凑的形状演化,可以概括为:
这种层级结构可以理解为:
- 低层 先发现局部一致性,如边缘、纹理、局部部件;
- 高层 再把这些局部块组合为更完整的语义对象。
notebook 里的 ToyGroupViTEncoder 也按这个思路实现了两阶段 grouping:先从 196 个 patch 聚到 64 个中间 groups,再进一步聚到 8 个最终 groups。这个例子不追求复现原论文规模,但很适合理解数据流。
对比学习目标:训练时没有像素标签
GroupViT 的训练目标本质上仍然是 CLIP 风格的图文对比学习。设图像嵌入为 ,文本嵌入为 ,则损失可写为:
关键点在于:监督发生在图像-文本匹配层面,而不是像素分类层面。但由于图像编码器内部被迫通过 grouping 建立更有语义的一致区域,最终这些区域就成为 zero-shot segmentation 的基础。
实验结果
论文最有说服力的结论不是“比所有监督式分割都更强”,而是它在完全不使用像素级标注的前提下,已经能把图文监督迁移到语义分割任务上。
根据论文与项目页公开结果,GroupViT 在 zero-shot transfer 设置下达到:
| 数据集 | 指标 | 结果 |
|---|---|---|
| PASCAL VOC 2012 | mIoU | 51.2 |
| PASCAL Context | mIoU | 22.3 |
这说明它确实学到了可以迁移的区域结构,而不是只会做全图分类。不过论文和原始笔记都指出了它的边界:
- 背景类较难:图文监督更容易学习可命名的前景对象,而背景本身往往语义模糊。
- group 槽位有限:最终 group 数量会限制模型能显式表达多少个区域。
- 候选类别设计敏感:zero-shot 推理结果会明显受文本标签词表影响。
因此,GroupViT 更适合理解“文本监督如何催生区域结构”这一机制,而不是把它当作所有场景下的最优分割器。
总结
GroupViT 的核心贡献可以压缩成三句话:
- 它把分割问题从像素监督转成了区域结构学习问题;
- 它把 ViT 的规则 patch 表示升级为可学习的层级 group 表示;
- 它证明了图文对比学习不仅能学全局语义,也能驱动语义区域的自然涌现。
如果从方法演化角度看,GroupViT 的意义并不只是一个 zero-shot segmentation 模型,而是它为后续“视觉-语言 + 区域级表示”这条路线提供了非常清晰的结构范式。
代码实战
这篇论文的 notebook 采用“双路径”思路:一条是手写 toy GroupViT 编码器,用于看清 patch、group token、grouping block 和回投路径;另一条是直接调用 Hugging Face 上的预训练权重,观察真实 zero-shot classification 与 segmentation 的输出。
![]()
如果你只想抓住这份 notebook 的最重要工程结论,可以优先看下面三段代码。
第一段是 toy 模型中的推理回投逻辑。它把最终 group 的类别分数重新传播回 patch,再上采样到像素空间:
def backproject_segmentation(final_groups, stage1_assign, stage2_assign, text_features, img_size, patch_size):
final_groups = F.normalize(final_groups, dim=-1)
text_features = F.normalize(text_features, dim=-1)
final_group_scores = torch.matmul(final_groups, text_features.T)
patch_to_final = torch.matmul(stage1_assign, stage2_assign)
patch_logits = torch.matmul(patch_to_final, final_group_scores)
grid_size = img_size // patch_size
dense_logits = patch_logits.transpose(1, 2).reshape(
final_groups.shape[0],
text_features.shape[0],
grid_size,
grid_size,
)
upsampled_logits = F.interpolate(
dense_logits,
size=(img_size, img_size),
mode="bilinear",
align_corners=False,
)
return patch_logits, upsampled_logits这段实现把论文中的核心链路直接落到了代码里:先有 patch -> stage1 group,再有 stage1 group -> final group,最后让文本语义通过 final group 回流到像素。
第二段是调用官方预训练模型做 zero-shot segmentation。这里最关键的是 output_segmentation=True,模型会直接返回 segmentation_logits:
def run_zero_shot_segmentation(pil_image, labels):
inputs = processor(text=labels, images=pil_image, padding=True, return_tensors="pt").to(device)
with torch.inference_mode():
outputs = groupvit_model(**inputs, output_segmentation=True)
seg_logits = outputs.segmentation_logits.detach().cpu().float()
seg_logits = F.interpolate(seg_logits, size=pil_image.size[::-1], mode="bilinear", align_corners=False)
return seg_logits第三段则展示了一个非常实用的经验:prompt 设计会显著影响 zero-shot 结果。notebook 同时比较了细粒度 prompt 和粗粒度 prompt,这一点对实际使用非常关键。
CLASS_PROMPTS_FINE = [
"a photo of a cat",
"a photo of a dog",
"a photo of a remote control",
"a photo of a couch",
"a photo of a blanket",
]
CLASS_PROMPTS_COARSE = [
"an animal",
"a pet",
"electronics",
"furniture",
"fabric",
]
SEGMENT_LABELS = ["cat", "remote control", "couch", "blanket"]从学习路径看,这份 notebook 很适合作为两类用途:
- 原理复盘:先通过 toy 版本看清 GroupViT 的层级 grouping 机制;
- 工程验证:再通过预训练模型快速试验不同 label 词表对 zero-shot 分割的影响。
参考文献
- Jiarui Xu, Shalini De Mello, Sifei Liu, Wonmin Byeon, Thomas Breuel, Jan Kautz, Xiaolong Wang. GroupViT: Semantic Segmentation Emerges from Text Supervision. CVPR 2022. https://arxiv.org/abs/2202.11094
- GroupViT 项目页与官方代码索引。 https://jerryxu.net/GroupViT/
- Hugging Face Transformers GroupViT 文档与模型实现接口。 https://huggingface.co/docs/transformers/model_doc/groupvit