Language-driven Semantic Segmentation
Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, René Ranftl — 2022
LSeg 讨论的是一个比传统语义分割更开放的问题:如果类别集合不再在训练时被完全写死,模型还能不能在推理阶段根据自然语言 prompt 直接分割出目标区域?
这篇论文的贡献,在于把 CLIP 式语言语义空间真正接到了密集预测任务上。它不再只做图像级别的图文对齐,而是让每个像素位置都能够与文本语义发生对应,从而把语义分割从固定标签预测推进到语言驱动的开放词汇分割。
研究动机
传统语义分割通常依赖封闭类别集合。模型训练时就已经决定了要预测哪些类别,推理时只能在这些固定标签里选择。这种范式在标准 benchmark 上很好用,但泛化能力有限:如果用户想分割训练集里没有出现过的新类别,传统分割头通常就无能为力。
LSeg 的出发点,是把 CLIP 在 zero-shot 分类里验证过的“文本语义可迁移性”带到像素级任务中。既然图像整体可以和文本对齐,那么图像中的每个空间位置理论上也可以与语言语义空间对齐。
核心方法/模型架构
LSeg 的整体框架可以理解为三步。
- 用文本编码器把类别 prompt 编码为文本特征。
- 用图像编码器提取逐像素的密集视觉特征。
- 通过像素特征与文本特征的相似度计算,得到每个位置对各个类别的响应图。
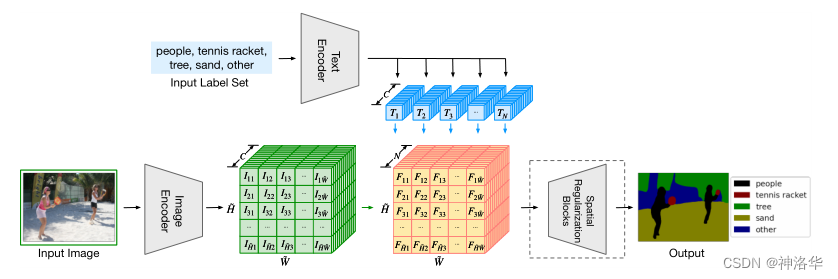
和 CLIP 最大的差别在于,CLIP 的图像分支输出通常是整张图的全局表示,而 LSeg 的图像分支输出是空间密集特征图。也正因为如此,LSeg 才能把“图文对齐”落到像素级别,而不是停留在图像级检索或分类。
组件详解
文本编码器
LSeg 直接使用 CLIP 文本编码器,并在训练和推理过程中保持冻结。这样做有两个直接好处。
- 保留开放词汇语义空间:避免小规模分割数据把语言表示学坏。
- 降低训练复杂度:把学习重点集中在图像侧的密集特征建模上。
若类别 prompt 数量为 ,通道维度为 ,则文本特征可以写成:
图像编码器
图像侧输出的不是单个全局向量,而是逐像素的密集视觉特征图。设空间尺寸为 ,则视觉特征可以表示为:
论文采用的是 DPT 风格的结构,本质目标是让每个空间位置都拥有可以和文本特征比较的语义表示。
像素级图文相似度
LSeg 的核心步骤,是把每个像素位置的视觉特征与所有文本特征逐一比较。也就是说,模型不是在最后接一个固定类别的线性分类头,而是直接把文本特征当作动态类别原型。
若第 个类别的文本向量为 ,则每个空间位置的响应可以看作视觉向量与文本向量之间的相似度:
这样得到的输出不再是“固定类别编号”,而是“当前 prompt 集合下的语义响应图”。这正是 LSeg 能做开放词汇分割的关键。
Spatial Regularization Blocks
直接计算出的相似度图通常还比较粗糙,因此论文在后面加入了 Spatial Regularization Blocks 进一步做空间细化。
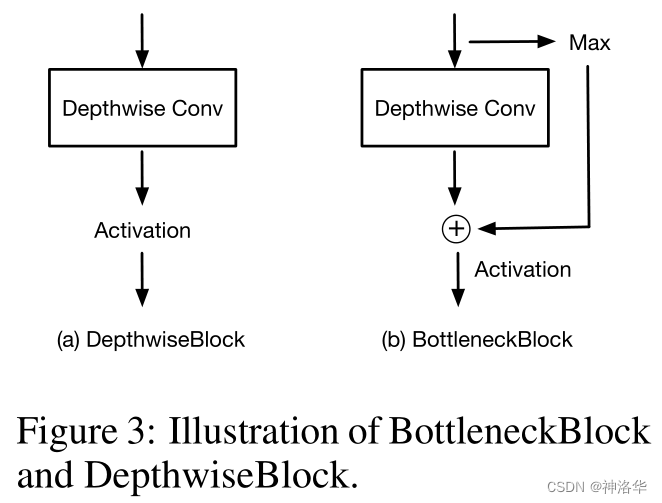
可以把它理解为一个轻量的 refinement 模块:在不破坏文本语义对齐的前提下,继续利用局部卷积传播空间上下文,让边界和区域一致性更稳定。
训练与推理
LSeg 最值得讲清楚的地方,是训练和推理虽然共享同一条“像素特征 × 文本特征”的主线,但目标并不完全相同。
训练阶段,模型有像素级标注,因此可以用交叉熵损失直接监督每个位置应该更接近哪个文本类别。这让图像编码器逐步学会产生 language-aware 的密集特征。
推理阶段,则不再需要重新训练分类头。用户只要给出任意文本 prompt,模型就能直接输出相应的分割响应图。这种能力来自训练阶段学到的视觉-语言对齐,而不是来自推理时临时拟合参数。
也正因为如此,LSeg 的 zero-shot 能力和传统语义分割的“固定类别闭集预测”有本质区别:它不是在旧类别上做插值,而是在语言空间里做查询。
实验结果
LSeg 的实验证明,把语言语义空间引入像素级分割任务之后,模型能够在多个数据集上实现有效的开放词汇分割。它说明 zero-shot 不一定只能停留在图像级分类或检索,密集预测任务同样可以通过视觉-语言对齐获得可迁移能力。
当然,这条路线也有明显代价。相比闭集分割模型,开放词汇分割的边界质量、细粒度结构和 prompt 敏感性都会成为新的挑战。换句话说,LSeg 打开的不是“更简单的分割”,而是“更灵活但更难”的分割问题。
总结
LSeg 的意义不只是把文本拿来当标签名,而是把语言语义真正引入到了像素级预测过程中。它让语义分割第一次比较系统地摆脱了固定类别集合的限制,也为后续 open-vocabulary segmentation、prompt-driven dense prediction 等方向奠定了方法论基础。
如果 CLIP 证明了“整张图可以被语言理解”,那么 LSeg 证明的就是“图像里的每个局部位置,也可以被语言查询”。
代码实战
这份 Notebook 采用了两条互补路径来讲解 LSeg。
第一条是 toy LSeg,用一个轻量化的训练示例解释冻结文本特征、像素级图文相似度和有监督分割损失之间的关系,重点在于帮助理解训练路径和张量形状。
第二条是基于 CLIPSegForImageSegmentation 的推理示例,直接演示如何输入一张图片和多组 prompt,得到对应的语义响应图。这种实现虽然不是论文原模型,但非常适合教学和快速验证语言驱动分割的效果。
![]()
下面这段 toy 代码展示了 LSeg 风格的像素级图文相似度计算:
def pixel_text_similarity(image_features, text_features):
bsz, channels, height, width = image_features.shape
image_tokens = image_features.flatten(2).transpose(1, 2)
image_tokens = F.normalize(image_tokens, dim=-1)
text_features = F.normalize(text_features, dim=-1)
scores = image_tokens @ text_features.T
scores = scores.transpose(1, 2).reshape(bsz, -1, height, width)
return scoresNotebook 中的推理部分则直接调用预训练模型:
from transformers import CLIPSegForImageSegmentation, CLIPSegProcessor
clipseg_processor = CLIPSegProcessor.from_pretrained('CIDAS/clipseg-rd64-refined')
clipseg_model = CLIPSegForImageSegmentation.from_pretrained('CIDAS/clipseg-rd64-refined')
clipseg_model.eval()两部分结合起来,可以同时理解 LSeg 的训练逻辑和 prompt 驱动分割的工程用法。
参考文献
- Boyi Li, Kilian Q. Weinberger, Serge Belongie, Vladlen Koltun, René Ranftl. Language-driven Semantic Segmentation. arXiv
- 原始代码实战 Notebook:
papers/LSeg/code.ipynb - Hugging Face Transformers documentation and model usage around
CLIPSegProcessor/CLIPSegForImageSegmentation