Masked Autoencoders Are Scalable Vision Learners
Kaiming He, Xinlei Chen, Saining Xie, Yanghao Li, Piotr Dollár, Ross Girshick — CVPR 2022 (Facebook AI Research)
Masked Autoencoders(MAE)是 Meta AI 于 2021 年提出的视觉自监督学习框架,由何恺明等人在论文《Masked Autoencoders Are Scalable Vision Learners》中发表。其核心思想是随机掩码 75% 的图像 Patch,仅对可见部分进行编码,再用轻量解码器重建被掩码区域的像素值。这一简洁的「预测缺失部分」范式成功将 NLP 中 BERT 的掩码建模策略迁移到视觉领域,为大规模视觉预训练开辟了新方向。
研究动机
自监督学习的挑战
计算机视觉领域缺乏像 NLP 那样简洁高效的自监督学习方法。现有的视觉对比学习方法(如 SimCLR、MoCo)实现复杂且计算密集,依赖精心设计的数据增强和大批量训练,缺乏 BERT 等掩码语言模型所具备的简洁性。
从 BERT 到视觉的掩码建模
BERT 通过预测被随机掩码的文本部分,在 NLP 领域取得巨大成功。这种「预测缺失部分」的范式概念清晰、训练稳定且易于实现。MAE 旨在将这种掩码建模策略有效迁移到视觉领域。
视觉与语言的关键差异
图像和文本存在本质区别,直接迁移掩码建模面临三个挑战:
| 维度 | 文本 | 图像 |
|---|---|---|
| 数据结构 | 一维离散序列 | 二维连续结构 |
| 信息冗余度 | 低(缺少一个词可能改变句意) | 高(缺少少量像素对整体信息影响不大) |
| 基本单元语义 | 词汇携带丰富语义 | 单个像素语义信息稀疏 |
这些差异意味着视觉掩码模型需要更高的掩码率、不同的架构设计和重建目标。
模型架构
整体流程
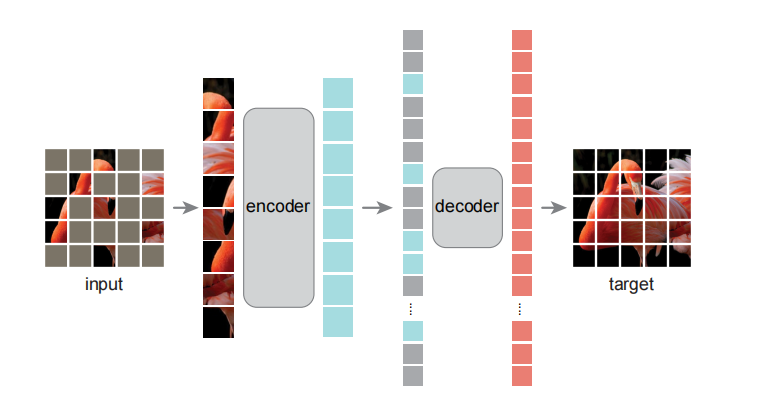
MAE 的整体流程如下:
- 将输入图像划分为规则的非重叠 Patch(如 像素)
- 随机选择 75% 的 Patch 进行掩码,仅保留 25% 的可见 Patch
- 编码器(标准 ViT)仅处理可见 Patch,提取视觉特征
- 解码器接收编码后的可见 Patch 和可学习的掩码 Token,重建被掩码区域的像素值
- 使用均方误差(MSE)作为损失函数,且仅在被掩码区域计算损失
编码器设计
- 采用标准 Vision Transformer(ViT) 作为骨干网络
- 仅处理未被掩码的 Patch(约 25%),计算量与可见 Patch 数量成正比,大幅降低计算复杂度
- 负责从可见 Patch 中提取有意义的视觉表示
掩码 Token 与序列重建
掩码 Token 是一个可学习的嵌入向量(维度与 Patch Embedding 相同,如 768 维),通过 nn.Parameter 实现,使用均值为 0、标准差为 0.02 的正态分布初始化,在训练中持续更新。所有被掩码位置共享同一个掩码 Token。
序列重建过程:
- 创建一个全部由掩码 Token 组成的序列(长度等于总 Patch 数,如 196)
- 将编码器输出的可见 Patch 放回其在原始序列中的位置
- 为所有位置(包括被掩码的位置)添加位置编码
被掩码位置的最终表示 = 掩码 Token + 位置编码,不包含任何编码器输出的信息。位置编码使解码器能够感知每个 Token 在原始图像中的空间位置。
解码器设计
- 采用比编码器更少的 Transformer 层,结构轻量
- 输入:编码后的可见 Patch 表示 + 掩码 Token(已添加位置编码)
- 输出层为线性层,将特征映射回像素空间(每个 Patch 输出 维),完成像素级重建
- 选择 Transformer 解码器而非简单 MLP,是因为像素级重建任务较为复杂
这种非对称设计的优势在于:强大的编码器专注于特征提取,轻量的解码器负责重建,在表示能力和计算效率之间取得平衡。
训练策略
高效实现
MAE 的实现无需任何稀疏矩阵操作,具体流程:
- 为每个 Patch 生成 Token(线性投影 + 位置编码)
- 随机打乱 Token 序列,移除后 75% 的部分(等效于无放回采样)
- 编码器仅处理保留的 25% Token
- 将掩码 Token 附加到编码后的序列,通过逆向打乱恢复原始位置顺序
- 解码器处理完整序列(添加位置编码后)
打乱和恢复顺序的操作计算开销极小,使整体实现简洁高效。
解码器前向传播的核心代码:
def forward_decoder(self, x, ids_restore):
# x: 编码器输出的可见 Patch 表示 [B, N_vis, D]
# ids_restore: 从掩码索引恢复到原始顺序的索引映射
B, N, D = x.shape
# 创建完整序列(包括掩码 Token)
mask_tokens = self.mask_token.repeat(B, ids_restore.shape[1] - N, 1)
x_ = torch.cat([x, mask_tokens], dim=1)
# 恢复原始顺序
x_ = torch.gather(x_, dim=1, index=ids_restore.unsqueeze(-1).repeat(1, 1, D))
# 添加位置编码
x = x_ + self.decoder_pos_embed
# 通过解码器 Transformer 层
for blk in self.decoder_blocks:
x = blk(x)
# 通过预测头
x = self.decoder_pred(x)
return x损失函数
使用均方误差(MSE)计算重建像素与原始像素之间的差异,仅在被掩码区域计算损失,可见 Patch 不参与。直接在 RGB 像素空间重建,使用归一化像素值作为回归目标:
其中 是被掩码 Patch 的集合, 是重建像素, 是原始像素。
预训练与微调
| 阶段 | 架构 | 目标 |
|---|---|---|
| 预训练 | 完整编码器 + 解码器 | 掩码重建任务,自监督学习视觉表示 |
| 微调 | 仅保留编码器 + 任务头 | 丢弃解码器,在下游任务上端到端微调 |
| 线性探测 | 冻结编码器 + 线性分类头 | 仅训练分类头参数,评估表示质量 |
关键创新点
高掩码率
75% 的掩码率是 MAE 的核心设计,远高于 BERT 的 15%。这是因为图像的高冗余性使得低掩码率下模型可以通过插值轻松完成重建,无法学到有意义的语义特征。高掩码率迫使模型理解图像的全局结构。
非对称编码-解码架构
编码器仅处理 25% 的可见 Patch,计算量大幅降低(约为全图编码的 1/4)。计算密集的编码器不处理掩码 Token,轻量解码器负责重建,使大规模预训练成为可能。
像素级重建
直接在 RGB 像素空间进行重建而非预测离散 Token,简化了训练目标。重建任务促使模型学习图像的语义结构,而非简单复制像素模式。
总结
MAE 将 NLP 中成功的掩码建模范式高效迁移到视觉领域,通过高掩码率和非对称架构实现了简洁、高效且强大的自监督学习。其设计充分考虑了视觉数据的冗余特性,在保持实现简洁性的同时,学到了可迁移到多种下游任务的通用视觉表示。
代码实战
完整的 MAE 代码实现(CIFAR-10 自监督预训练 + 微调分类),包含源代码实现与 nn.TransformerEncoder 简洁实现两种方式的对比:
![]()
以下是 MAE 的核心组件实现。
Patch Embedding
将图像切分为 大小的非重叠 Patch,通过线性投影映射到 维向量。实现上使用 Conv2d(kernel_size=P, stride=P) 等效于分块线性投影:
class PatchEmbedding(nn.Module):
def __init__(self, img_size=32, patch_size=4, in_channels=3, embed_dim=64):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(in_channels, embed_dim,
kernel_size=patch_size, stride=patch_size)
def forward(self, x):
# (B, C, H, W) → (B, embed_dim, H/P, W/P) → (B, N, embed_dim)
x = self.proj(x)
x = x.flatten(2).transpose(1, 2)
return xRandom Masking
对 个 Patch 生成随机排列,保留前 个作为可见 Patch。用 argsort(rand) 生成随机排列避免稀疏操作,同时保存 ids_restore(逆排列)用于解码器恢复原始位置:
def random_masking(x, mask_ratio):
B, N, D = x.shape
num_keep = int(N * (1 - mask_ratio))
noise = torch.rand(B, N, device=x.device)
ids_shuffle = torch.argsort(noise, dim=1)
ids_restore = torch.argsort(ids_shuffle, dim=1)
ids_keep = ids_shuffle[:, :num_keep]
x_visible = torch.gather(x, dim=1,
index=ids_keep.unsqueeze(-1).expand(-1, -1, D))
mask = torch.ones(B, N, device=x.device)
mask[:, :num_keep] = 0
mask = torch.gather(mask, dim=1, index=ids_restore)
return x_visible, mask, ids_restore完整 MAE 模型
组装编码器和解码器,损失函数仅在被掩码的 Patch 上计算 MSE:
class MAE(nn.Module):
def __init__(self, img_size, patch_size, in_channels,
enc_dim, enc_heads, enc_layers, enc_ff,
dec_dim, dec_heads, dec_layers, dec_ff, mask_ratio=0.75):
super().__init__()
self.patch_size = patch_size
num_patches = (img_size // patch_size) ** 2
self.encoder = MAEEncoder(img_size, patch_size, in_channels,
enc_dim, enc_heads, enc_layers, enc_ff, mask_ratio)
self.decoder = MAEDecoder(num_patches, enc_dim, dec_dim,
dec_heads, dec_layers, dec_ff, patch_size, in_channels)
def forward(self, imgs):
latent, mask, ids_restore = self.encoder(imgs)
pred = self.decoder(latent, ids_restore)
target = self.patchify(imgs)
# MSE loss — 仅在被掩码 patch 上计算
loss = (pred - target) ** 2
loss = loss.mean(dim=-1)
loss = (loss * mask).sum() / mask.sum().clamp(min=1)
return loss, pred, mask预训练编码器微调分类
MAE 预训练完成后,丢弃解码器,仅保留编码器。在编码器上接一个线性分类头,对下游任务进行有监督微调:
class MAEClassifier(nn.Module):
def __init__(self, pretrained_mae, num_classes=10):
super().__init__()
self.encoder = copy.deepcopy(pretrained_mae.encoder)
self.encoder.mask_ratio = 0.0 # 微调时不掩码
enc_dim = self.encoder.norm.normalized_shape[0]
self.head = nn.Linear(enc_dim, num_classes)
def forward(self, x):
features, _, _ = self.encoder(x)
cls_token = features[:, 0]
return self.head(cls_token)参考文献
- He, K., et al. (2021). Masked Autoencoders Are Scalable Vision Learners. CVPR 2022.
- 李沐. MAE 论文逐段精读. Bilibili.