Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity
William Fedus, Barret Zoph, Noam Shazeer — Google (2022)
DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models
Damai Dai et al. — DeepSeek-AI (2024)
MoE(Mixture of Experts,混合专家模型)是一种条件计算范式:模型拥有大量参数,但每次推理只激活其中一小部分。这一思想使得在计算量基本不变的前提下,模型参数量可以大幅扩展。本文串讲两篇里程碑式的 MoE 论文 —— Switch Transformer 和 DeepSeekMoE,梳理从基础稀疏门控到细粒度专家分割的技术演进。
MoE 的核心思想
对于标准 Transformer 模型,扩大规模意味着计算量(FLOPs)同步暴增。研究者希望在保持每个 Token 计算量恒定的前提下,单纯增加模型参数量。核心区别在于:
| 对比项 | 稠密网络 | 稀疏网络 |
|---|---|---|
| 计算方式 | 全部参数参与 | 部分参数参与 |
| 参数利用 | 每次用全部 | 每次用一部分 |
| 扩展效率 | 增大模型 = 增大计算 | 增大模型 ≠ 增大计算 |
| 代表模型 | GPT、LLaMA | Switch Transformer、Mixtral |
| 训练难度 | 较简单 | 较复杂(负载均衡等问题) |
标准 Transformer 由 FFN 和 MSA 组成,FFN 计算量大约占 8 成。如果让 FFN 稀疏 10 倍(每次只激活 1/10 的 FFN 参数),同等计算量下,模型参数量大约变成原来的 8 倍:
| 组件 | 原参数量 | 新参数量 |
|---|---|---|
| MSA | 0.2P | 0.2P(不变) |
| FFN | 0.8P | 0.8P × 10 = 8P |
| 合计 | P | 0.2P + 8P = 8.2P |
Switch Transformer
Switch Transformer 是一篇工程导向、影响深远的里程碑工作。它用严谨的消融实验证明了 MoE 可以被大规模、稳定地训练,并将这套范式推向了现代大模型主流。
从传统 MoE 到 Switch Routing
在传统 MoE 中,路由概率由 Softmax 计算得出:
此时输出 为所有被选中专家的加权和:
其中 是选中的 Top- 专家的索引集合。以前的研究认为必须路由到至少 (例如 )个专家,才能让路由函数获得有意义的梯度进行比较。然而,Switch Transformer 大胆提出了一种极简策略:令 (Switch Routing)。每个 Token 只被发送到概率最高的那一个专家。虽然违背了之前的直觉,但事实证明它不仅保持了模型质量,还带来三大优势:降低了路由计算量、将专家所需的 Batch Size 减半、简化了通信。
模型架构
Switch Transformer 的核心改动是将 Transformer 中的 FFN 层替换为 MoE 层:每个 Token 经过一个路由器(Router),被分配到若干专家网络中的某一个进行计算。
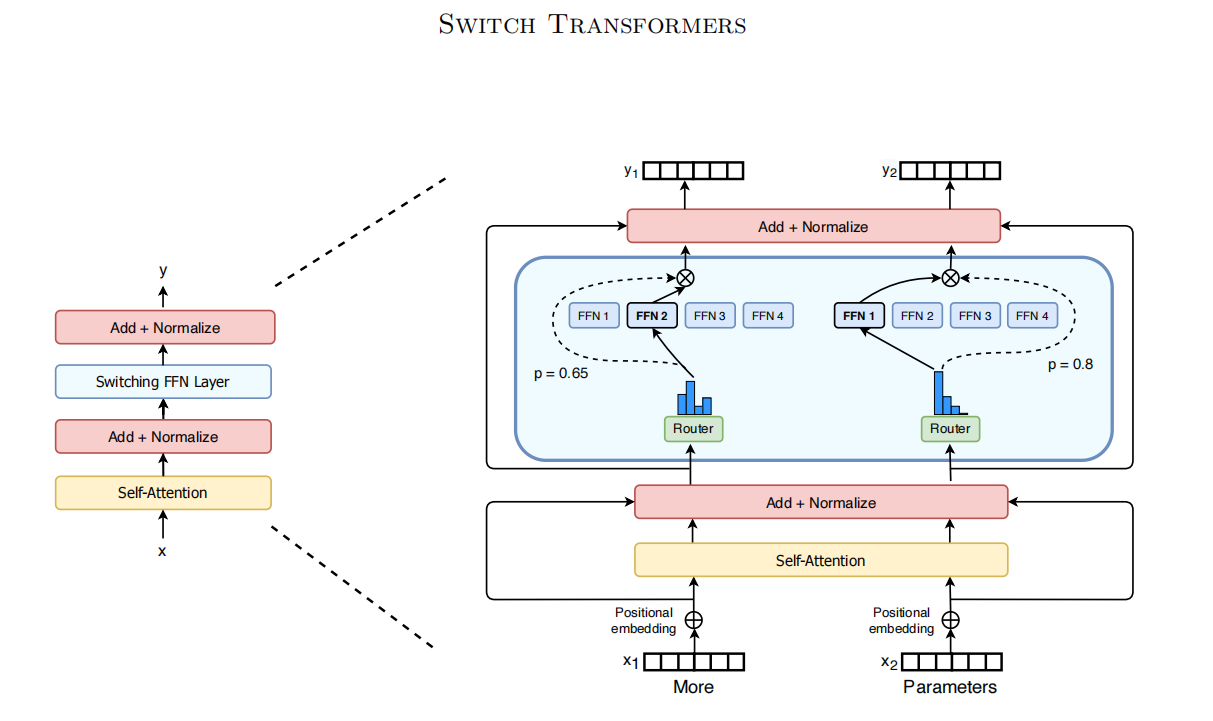
专家容量(Expert Capacity)
专家容量定义了每个专家最多能处理多少个 Token:
容量因子(capacity factor)大于 1.0 时提供缓冲空间,以应对流量分配不均。但过大会浪费内存。由于 Switch Routing 只选 1 个专家,其所需的容量因子相比 Top-2 MoE 至少减半(本文实验主要采用 1.0 或 1.25)。
若分配给某个专家的 Token 数超过了其容量上限(Dropped Tokens),多余的 Token 将不经过该专家计算。此时专家输出 ,经残差连接后输出 ,即直接跳过该层传递到下一层。
负载均衡损失函数(Load Balancing Loss)
MoE 路由存在一个严重问题 —— 路由崩溃(Routing Collapse):
- 训练初期某个专家稍微强一点
- 大量 Token 涌向它,它被训练得更强
- 更多 Token 涌向它,形成马太效应
- 其他专家几乎从不被选中,形同虚设
负载均衡损失就是为了强制让所有专家均匀地被使用。Switch Transformer 中的定义为:
各项含义:
| 符号 | 含义 |
|---|---|
| 专家总数 | |
| 损失系数(超参数,很小,如 ) | |
| 第 个专家实际处理的 Token 比例(离散,不可微) | |
| 路由器分配给第 个专家的概率均值(连续,可微) |
其中 是硬分配结果(离散,不可微), 是对 batch 内所有 Token 的路由器 Softmax 概率取均值(连续,可以反向传播):
在均匀路由的理想情况下,,此时:
损失取得最小值,说明达到了均衡。 系数的设置需要权衡: 太大会过度强调均衡,损害模型预测能力(专家被迫平均,失去专业化); 太小则约束不够,仍然出现路由崩溃。本文统一设为 。
训练与微调稳定性的核心技巧
选择性精度(Selective Precision):稀疏模型在使用 bfloat16 时极易出现 Softmax 溢出导致训练崩溃。本文提出仅在 Router 局部的 Softmax 计算内部投射(Cast)为 float32,生成分配张量后再转回 bfloat16。这一操作不增加跨设备通信,完美兼顾了速度与稳定性。
缩小的初始化方差:深度 Transformer 初始化极其重要。本文将标准 Transformer 初始化方差超参数 缩小 10 倍(即 ),显著降低了训练初期的方差,保证了万亿参数模型的收敛。
专家 Dropout(Expert Dropout):在小数据集微调时,稀疏模型因参数量大极易过拟合。解决方案是在微调时仅在专家前馈层内设置较高的 Dropout 率(如 0.4),而非专家层保持常规低 Dropout(0.1)。
Switch Transformer 的价值不在于提出全新的数学理论,而在于用严谨的消融实验证明了 MoE 可以被大规模、稳定地训练。站在今天看,DeepSeek-V3 用 MoE 以极低成本打败了稠密模型,其思想源头之一正是 Switch Transformer。
DeepSeekMoE
研究动机
在使用传统 MoE 层替换 Transformer 中的 FFN 时,主流做法是设置少量的庞大专家(例如 个),并将每个 Token 路由给 Top-(如 )专家。这种设定导致了两个致命的低效问题:
知识混合(Knowledge Hybridity):专家数量很少,被分配到某一个专家的 Token 必然涵盖非常多样的知识类型,难以实现真正的"术业有专攻"。
知识冗余(Knowledge Redundancy):不同专家处理不同 Token,但这些 Token 往往也需要调用一些通用的基础语言学常识,重复学习了相同的通用知识。
本文的破局之道:如何在保持计算量与参数量不变的前提下,让每个专家变得更加"专一"且不可替代?
数学定义
基础定义:
- :第 层注意力模块输出后,第 个 token 的隐含状态
- :传统 MoE 架构中专家的总数量
- :第 个前馈神经网络(专家),其结构与标准 Transformer FFN 相同
传统 MoE 路由(Conventional Top-K Routing):Token 被路由给得分最高的 个专家,输出 的计算方式为:
其中 是门控权重(具备稀疏性):
这里的 是路由打分。然而,当 较小(如 16)且 时,组合空间仅有 种,导致灵活性不足。
细粒度专家分割(Fine-Grained Expert Segmentation)
为了打破组合限制,DeepSeekMoE 保持总参数量不变,将每个大专家按中间隐藏层维度切分为 个"微小专家(Finer experts)"。总专家数变为 ,每次激活的微小专家数同步增至 ,以保证计算成本(FLOPs)严格对齐原版:
当 (原来 16 专家切分成 64 个),激活 8 个专家时,组合空间飙升至 种。这种巨大的组合爆炸使得知识能够被极其精准地装配和提取。
共享专家隔离(Shared Expert Isolation)
为了剥离各个专家重复学习到的通用知识,DeepSeekMoE 从 个专家中强制剥离出 个专家作为"共享专家(Shared Experts)"。无论路由结果如何,这 个专家对所有 Token 强制激活。
最终的 DeepSeekMoE 核心前向传播公式为:
对于剩余的 个"路由专家(Routed Experts)",路由网络仅需动态挑选其中的 个进行激活:
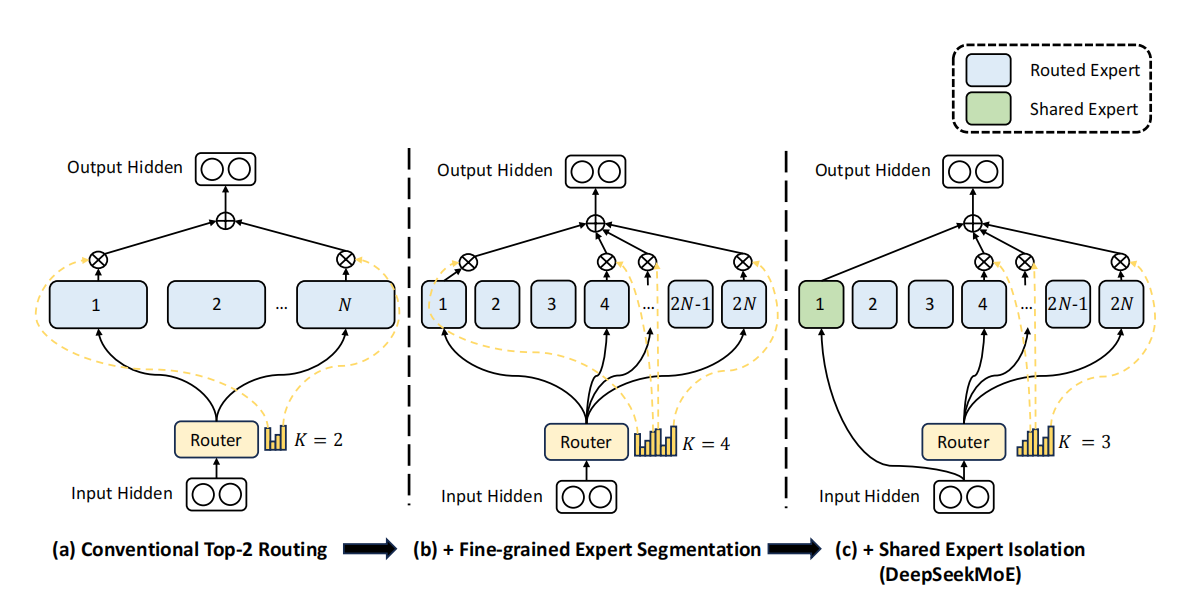
三种架构的演进:
- (a) 传统 Top-2 Routing: 个大专家,,组合有限
- (b) 细粒度切分: 个小专家,,组合暴增,知识更精准
- (c) DeepSeekMoE:共享专家处理通用知识 + 路由专家处理专项知识,
辅助损失函数(Load Balance Loss)
为了防止路由崩塌以及解决硬件计算瓶颈,作者设计了混合辅助损失函数:
专家级负载均衡损失(Expert-Level Balance Loss):
其中 是当前批次内选择专家 的 token 比例, 是路由到专家 的平均 softmax 概率。主要防止过度依赖个别专家。
设备级负载均衡损失(Device-Level Balance Loss):
通过将专家划分为 个组(部署在 个 GPU 上),强制每张 GPU 处理的 token 数量趋于一致,消除分布式训练的计算短板。
实验结果
DeepSeekMoE 16B 的关键超参数设置:
| 配置项 | 值 |
|---|---|
| 总层数 | 28 |
| 隐藏层维度 | 2048 |
| 注意力头数 | 16(每头维度 128) |
| 相对尺寸 | 4(每个专家是标准 FFN 的 0.25 倍大小) |
| 专家配置 | 个共享专家 + 64 个路由专家 |
| 每 Token 路由 | 2 个共享专家 + 6 个路由专家 |
| 激活参数 | 约 2.8B |
| 总参数量 | 16.4B |
| MoE 替换策略 | 除第一层保持 Dense FFN 外,其余所有层替换为 MoE |
DeepSeekMoE 是一篇充满"直觉美感"同时又具有巨大工程实用价值的杰作。16B 的总参数量意味着可以无需量化、完整装进单张 40GB 显存(如 A100/A800)的 GPU 中;同时仅 2.8B 的激活参数使得其推理速度比 7B 的密集模型还要快 2.5 倍。
总结
| 对比维度 | Switch Transformer | DeepSeekMoE |
|---|---|---|
| 核心贡献 | Top-1 路由简化 MoE,大规模稳定训练 | 细粒度分割 + 共享专家隔离 |
| 路由策略 | Top-1 | Top-K(细粒度) |
| 专家设计 | 少量大专家 | 大量小专家 + 共享专家 |
| 解决的问题 | MoE 可扩展性与训练稳定性 | 知识混合与知识冗余 |
| 工程意义 | 证明 MoE 可规模化落地 | 以极低成本实现高性能 |
MoE 的核心价值在于将参数规模与计算量解耦:通过条件路由,模型可以拥有万亿级参数但每次推理只使用其中一小部分。从 Switch Transformer 的工程奠基到 DeepSeekMoE 的精细化设计,这条技术路线已成为现代大语言模型的主流架构选择之一。
代码实战
![]()
以下代码基于二维合成分类任务演示 MoE 的核心组件。完整代码请参考上方 Colab 链接。
门控网络与稀疏路由
Noisy Top-1 Gate 的实现:训练时注入噪声促进探索,推理时关闭噪声使用确定性路由。
class NoisyTop1Gate(nn.Module):
def __init__(self, hidden_dim, num_experts):
super().__init__()
self.num_experts = num_experts
self.gate = nn.Linear(hidden_dim, num_experts)
self.noise_proj = nn.Linear(hidden_dim, num_experts)
def forward(self, x):
logits = self.gate(x)
if self.training:
noise_std = F.softplus(self.noise_proj(x)) + 1e-2
logits = logits + torch.randn_like(logits) * noise_std
probs = F.softmax(logits, dim=-1)
top_idx = torch.argmax(logits, dim=-1)
top_mask = F.one_hot(top_idx, num_classes=self.num_experts).float()
route_weights = probs * top_mask
# 负载均衡辅助损失
load = top_mask.mean(dim=0)
importance = probs.mean(dim=0)
aux_loss = self.num_experts * torch.sum(load * importance)
return route_weights, probs, top_idx, aux_loss稀疏 MoE 层
每个专家产生候选输出,再按路由权重加权聚合:
class SparseMoELayer(nn.Module):
def __init__(self, hidden_dim, num_experts, dropout=0.1):
super().__init__()
self.gate = NoisyTop1Gate(hidden_dim, num_experts)
self.experts = nn.ModuleList([
ExpertMLP(hidden_dim, dropout=dropout) for _ in range(num_experts)
])
def forward(self, x):
route_weights, probs, top_idx, aux_loss = self.gate(x)
expert_outputs = torch.stack([
expert(x) for expert in self.experts
], dim=1)
mixed = torch.sum(
expert_outputs * route_weights.unsqueeze(-1), dim=1
)
return mixed, {'probs': probs, 'top_idx': top_idx, 'aux_loss': aux_loss}训练 vs 推理的区别
| 阶段 | 门控行为 | 目的 |
|---|---|---|
| 训练 | 对 gate logits 注入噪声 | 鼓励探索更多专家,缓解路由崩溃 |
| 推理 | 关闭噪声,确定性 top-1 路由 | 输出更稳定,可重复 |
参考文献
- William Fedus, Barret Zoph, Noam Shazeer. Switch Transformers: Scaling to Trillion Parameter Models with Simple and Efficient Sparsity. 2022.
- Damai Dai et al. DeepSeekMoE: Towards Ultimate Expert Specialization in Mixture-of-Experts Language Models. 2024.
- Noam Shazeer et al. Outrageously Large Neural Networks: The Sparsely-Gated Mixture-of-Experts Layer. ICLR 2017.