Momentum Contrast for Unsupervised Visual Representation Learning
Kaiming He, Haoqi Fan, Yuxin Wu, Saining Xie, Ross Girshick — CVPR 2020 (Facebook AI Research)
MoCo(Momentum Contrast)由何恺明等人于 2020 年在 CVPR 上发表,是自监督视觉表示学习的里程碑工作。它将对比学习建模为字典查询问题,通过动态队列和动量编码器两大核心机制,构建了大型且一致的负样本字典,显著缩小了自监督学习与监督学习之间的差距。
对比学习基本概念
对比学习(Contrastive Learning)是一种自监督学习方法,核心思想是学习区分相似和不相似样本的表示。它通过构建正样本对和负样本对,训练模型在特征空间中将正样本拉近、负样本推远,无需人工标注标签。
- 正样本拉近:对同一张图片做两种数据增强(裁剪、旋转等),得到两个视图。对比学习的目标是让这两个视图的特征表示非常接近,因为它们本质上是同一张图片。
- 负样本推远:当模型同时看到猫和狗的照片时,应产生两个在特征空间中相距较远的向量,表明它们是不同的概念。
研究动机
自监督视觉表示学习旨在无需人工标注的情况下学习有效的视觉特征。对比学习作为判别式方法展现出巨大潜力,可以从字典查询的视角来理解。
由图像 生成的增强视图 作为 anchor, 是正样本,其他样本 是负样本。在特征空间里,目标是让 和 尽可能相近, 与 尽可能远离。
换一个视角,将特征 看作字典的 query(查询), 看作 key,目标变为让 query 尽可能匹配正样本的 key。在 MoCo 的记号体系中:,,,,。其中 使用查询编码器编码, 使用键编码器编码。
这一视角的核心问题是:如何构建一个既大又一致的字典?字典越大,提供的负样本越多,学到的特征越具判别力;但字典中的表示必须由相近的编码标准生成,否则对比信号会失真。
MoCo 架构
动态队列机制
对比学习的效果很大程度上取决于负样本的数量和质量。MoCo 设计了一个动态队列(queue)结构作为字典:新的 mini-batch 编码后的键入队,最早入队的键出队,保持字典大小固定。
这种设计的关键优势是将字典大小与 mini-batch 大小解耦,允许使用大量负样本而不受 GPU 内存限制。队列中被移除的旧键不再参与损失计算,移除原因有二:
- 固定容量:队列大小固定(如 65536),新键入队时必须有旧键出队
- 保持新鲜度:随着模型训练,太旧的键与当前编码标准不一致,移除最旧的键有助于维持队列中表示的相对一致性
动量编码器
在 MoCo 中,队列存储的是不同时间点编码的键。如果编码器参数变化太快,早期入队的键和最近入队的键可能使用了差异很大的编码标准——这种表示不一致会导致对比学习效果变差,因为负样本之间的差异可能来自编码标准的变化,而非真正的语义差异。
为解决这一问题,MoCo 引入了动量编码器(momentum encoder)。查询编码器参数 通过反向传播正常更新,而键编码器参数 通过动量公式更新:
其中 是动量系数(通常设为 0.999)。由于 接近 1,键编码器每步仅更新 0.1% 来自查询编码器的参数,缓慢演变从而提供更一致的表示。
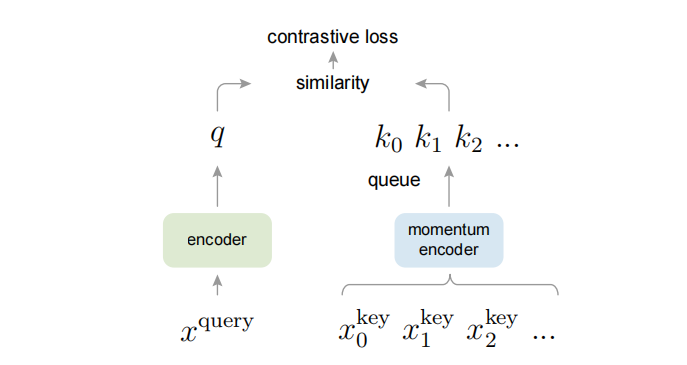
MoCo 的完整架构包含三个核心组件:
- 查询编码器:处理当前 mini-batch 的查询样本,参数通过反向传播更新
- 键编码器:处理正负样本,参数通过动量更新
- 队列:维护最近编码的键,作为负样本库
两个编码器架构相同(如 ResNet-50),但参数更新方式不同。
三种对比学习架构对比
端到端方法
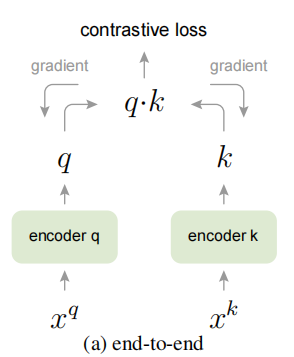
在端到端对比学习(如 SimCLR)中,两个编码器对 和 在同一个 mini-batch 中编码,因此都可以反向传播梯度,字典一致性高。缺点是字典大小等于 mini-batch 大小,受 GPU 内存限制。
Memory Bank 方法
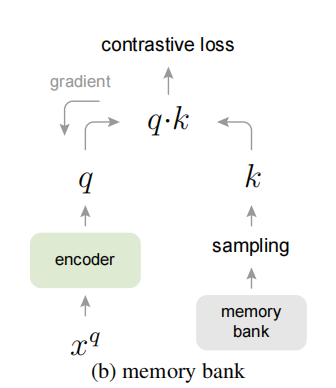
Memory Bank 方法关注字典的"大",使用独立的负样本存储库,字典大小远大于 mini-batch。但由于 key 的表征在不同时间点更新,一致性较差。
MoCo 方法
MoCo 统一了两者的优点:通过动态队列实现大字典,通过动量编码器保持一致性。
| 方法 | 字典大小 | 一致性 | 硬件需求 |
|---|---|---|---|
| 端到端(SimCLR) | 受限于 batch size | 高 | 高(需大 batch) |
| Memory Bank | 大 | 低 | 中 |
| MoCo | 大(与 batch size 解耦) | 高(动量保证) | 低 |
损失函数
InfoNCE Loss
在对比学习中,每张图片都被当作独立类别。以 ImageNet 的 100 万张图片为例,直接对 100 万个类做 softmax 计算量过大。MoCo 采用 InfoNCE Loss,其一般形式为:
MoCo 中使用点积作为相似度度量,具体形式为:
其中:
- :当前 batch 中某个样本的 query 表征
- :当前样本的正样本(同一图像的不同增强视图)
- :来自队列的其他样本表征(负样本)
- :温度参数,控制相似度的平滑程度
- :负样本数(等于队列长度)
InfoNCE 本质上是将对比任务转化为 类 softmax 分类:正样本放在 logits 的第 0 位,对应 label=0。
温度参数
温度参数 控制 softmax 分布的形状:
- 较大时:分布较平滑,模型平等对待所有负样本,学习更稳健但可能不够精细
- 较小时:分布更"尖锐",模型更关注最困难的负样本,学习更精细但训练可能不稳定
MoCo 使用 ,而 SimCLR 使用 ——因为 SimCLR 的负样本更少,需要更平滑的梯度信号。
训练流程
MoCo 的训练流程通过论文中的 Algorithm 1 清晰描述:

伪代码中有三个关键设计值得深入理解:
1. labels = zeros(N)正样本 始终被拼接在 logits 的第 0 列,因此 Cross Entropy 的 ground-truth 标签全为 0。这是将对比学习转化为 类 softmax 分类的巧妙实现。
2. k = k.detach()detach() 生成一个与原 tensor 共享数据但脱离计算图的新 tensor,确保 loss.backward() 时梯度不会回传到键编码器 。如果不 detach,梯度会同时更新 和 ,导致键编码器参数剧烈变化、队列中旧 key 失效、训练崩溃。
训练循环顺序是严格的:前向传播 → 计算 loss → loss.backward() 更新 → 动量更新 → 入队新 key、出队旧 key。
关键超参数
| 超参数 | 值 | 说明 |
|---|---|---|
| 动量系数 | 0.999 | 控制键编码器参数的更新速度 |
| 温度参数 | 0.07 | 控制 softmax 分布的尖锐程度 |
| 队列大小 | 65536 | 负样本数量 |
| 特征维度 | 128 | 投影头输出维度 |
总结
MoCo 的核心贡献在于提出了一个简洁高效的对比学习框架:
| 创新点 | 解决的问题 | 机制 |
|---|---|---|
| 动态队列 | 字典大小受限于 batch size | FIFO 队列解耦字典大小与 batch size |
| 动量编码器 | 大字典中表示不一致 | 缓慢更新 |
| 简洁设计 | 其他方法需大 batch / 多 GPU | 不需要大 batch,单 GPU 可训练 |
MoCo 通过对比学习隐式地学习数据分布的特征,使相似实例在特征空间中靠近、不相似实例远离,与信息最大化理论相符。这种设计使 MoCo 在多种下游任务中展现出接近甚至超过监督预训练的性能,为自监督视觉表示学习开辟了新方向。
与同期其他自监督方法的对比:
| 方法 | 核心思想 | 负样本来源 | 硬件需求 |
|---|---|---|---|
| MoCo | 动量编码器 + 动态队列 | 动态队列(K=65536) | 低 |
| SimCLR | 端到端大 batch 对比 | 同一 batch(2N-2) | 高 |
| BYOL | 自蒸馏,无需负样本 | 不需要负样本 | 中 |
| SwAV | 在线聚类 + 对比 | 聚类原型 | 中 |
代码实战
![]()
以下代码基于 PyTorch 实现 MoCo v1 的核心组件,完整 Notebook 包含从零手写和基于 ResNet-18 两种实现方式的对比。
InfoNCE 损失函数的实现,将 query 与 1 个正样本和 个负样本的相似度做对比:
def info_nce_loss(q, k_pos, queue, temperature):
"""计算 InfoNCE 损失.
Args:
q: (B, d) — query 特征(已 L2 归一化)
k_pos: (B, d) — 正样本特征(已 L2 归一化)
queue: (d, K) — 队列中的负样本特征
temperature: float — 温度参数 τ
Returns:
loss: 标量
"""
# 正样本相似度: q · k+ → (B, 1)
l_pos = torch.einsum('bd,bd->b', q, k_pos).unsqueeze(1)
# 负样本相似度: q · queue → (B, K)
l_neg = torch.mm(q, queue)
# 拼接 logits: 正样本在第 0 位 → (B, 1+K)
logits = torch.cat([l_pos, l_neg], dim=1) / temperature
# 标签:正样本始终在 index=0
labels = torch.zeros(logits.size(0), dtype=torch.long, device=q.device)
return F.cross_entropy(logits, labels)完整的 MoCo v1 模型,包含查询编码器、动量键编码器和动态队列三大核心组件:
class MoCoV1(nn.Module):
"""MoCo v1:query 编码器 + 动量 key 编码器 + 动态队列."""
def __init__(self, feature_dim=128, queue_size=4096,
momentum=0.999, temperature=0.07):
super().__init__()
self.m = momentum
self.T = temperature
self.K = queue_size
# query 编码器:正常梯度更新
self.encoder_q = Encoder(feature_dim)
# key 编码器:动量更新(初始化为 query 编码器的拷贝)
self.encoder_k = copy.deepcopy(self.encoder_q)
for p in self.encoder_k.parameters():
p.requires_grad = False
# 动态队列(register_buffer 不被优化器更新)
self.register_buffer(
'queue',
F.normalize(torch.randn(feature_dim, queue_size), dim=0))
self.register_buffer(
'queue_ptr', torch.zeros(1, dtype=torch.long))
@torch.no_grad()
def _enqueue(self, keys):
"""将当前 batch 的 key 入队,出队最旧的(环形队列)."""
batch_size = keys.size(0)
ptr = int(self.queue_ptr)
self.queue[:, ptr:ptr + batch_size] = keys.T
self.queue_ptr[0] = (ptr + batch_size) % self.K
@torch.no_grad()
def momentum_update(self):
"""动量更新: θ_k ← m·θ_k + (1-m)·θ_q."""
for p_q, p_k in zip(self.encoder_q.parameters(),
self.encoder_k.parameters()):
p_k.data = self.m * p_k.data + (1 - self.m) * p_q.data
def forward(self, x_q, x_k):
"""前向传播,返回 InfoNCE 损失."""
q = self.encoder_q(x_q) # query 编码(需要梯度)
with torch.no_grad():
k = self.encoder_k(x_k) # key 编码(无梯度)
loss = info_nce_loss(q, k, self.queue.clone().detach(), self.T)
self._enqueue(k)
return lossMoCo 预训练完成后,仅保留 query 编码器作为特征提取器,丢弃 key 编码器和队列。通过线性评估协议(冻结编码器 + 训练线性分类头)衡量特征质量。在 CIFAR-10 子集上的实验中,手写轻量 CNN 编码器达到约 42% 的线性评估准确率,验证了 MoCo 框架的有效性。