Non-Local Neural Networks
Xiaolong Wang, Ross Girshick, Abhinav Gupta, Kaiming He — CVPR 2018
Non-Local Neural Networks 是视频理解从“局部卷积堆深”走向“显式全局交互”的标志性工作。它提出的不是一个更重的 backbone,而是一个更直接的建模问题:如果真正关键的信息分布在远距离帧和远距离空间位置之间,为什么一定要依赖很多层局部操作,才能让它们彼此发生作用?论文给出的答案是 non-local operation,让每个时空位置都能直接从全局位置聚合信息。
这篇论文的长期影响,在于它把“全局依赖”从一种直觉,变成了一个可计算、可插拔、可迁移的模块。它既能无缝插入 2D/3D CNN,也与后来 Transformer 的 self-attention 形成了清晰映射。今天很多“局部卷积负责表征、全局交互负责关系建模”的视觉架构,都能在 Non-Local 中找到早期原型。
研究动机
卷积和递归这两类经典操作虽然非常成功,但都有同一个结构性限制:它们更擅长局部传播,而不擅长一步建立远距离关系。卷积一次只看邻域,想让两个相距很远的位置发生交互,通常需要堆叠很多层;递归虽然能沿时间维传播信息,但长距离依赖依然容易在多步传递中衰减。
对视频理解来说,这个问题尤其明显。动作识别、视频分类、检测和姿态估计里,真正关键的线索常常分散在远距离帧和远距离空间位置之间。例如某个动作是否成立,往往不取决于单个局部 patch,而取决于跨帧运动、人体各部位协同变化、以及远距离区域之间的语义对应。
论文想解决的核心问题可以压缩成一句话:能不能让网络中的一个位置一步直接“看到”所有位置,而不是依赖多层局部传播?Non-Local 的回答是可以,而且这个操作还能做成一个即插即用的模块,直接插到现有 backbone 中。
核心方法/模型架构
Non-Local 操作的基本形式并不复杂。对任意位置 ,输出写成:
这里有四个关键对象:
- :位置 与位置 的关系函数,用来决定“该关注谁”
- :位置 提供给全局聚合的值
- :归一化项
- :把聚合后的特征映回原通道空间,并通过残差加回输入
论文最常用的是 Embedded Gaussian 版本,它把关系函数写成:
写成矩阵形式后,就是最常被引用的这一版公式:
这也是为什么很多人会把 Non-Local 看成视觉中的早期 self-attention:theta、phi、g 与后来的 Query、Key、Value 形成了非常自然的对应。
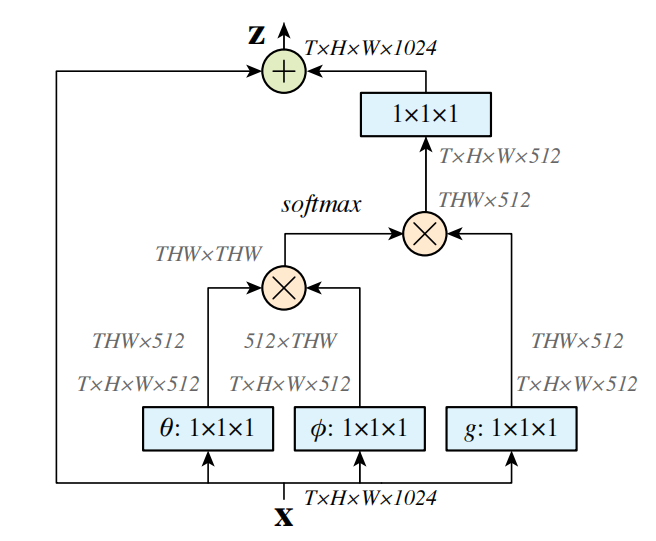
上图展示了视频场景下 Non-Local Block 的典型结构。输入特征张量形状通常可写成 (T, H, W, C) 或等价的张量排布,其中 是时间长度, 和 是空间尺寸。模块先做线性投影得到 theta、phi、g,再计算全局关系矩阵,最后通过输出投影和残差连接回到原特征流。
组件详解
Non-Local 操作到底在算什么
如果只保留一句最直观的理解,Non-Local 做的事情就是:当前位置不再只从邻域收集信息,而是从所有位置按内容相关性取一个全局加权和。这和卷积最大的区别不在于有没有权重,而在于权重的来源发生了变化。
卷积的权重是固定参数,所有样本共享;Non-Local 的权重则由输入内容动态决定。同一个位置在不同视频里,可能关注完全不同的时间帧和空间区域。这让模块具备了内容自适应的全局聚合能力。
Embedded Gaussian:它和 Self-Attention 的关系
在 Embedded Gaussian 版本里,theta(x_i)^\top phi(x_j) 本质上就是一种相似度打分。经过 softmax 后,每个位置都会得到一组对全局所有位置的注意力权重,再用这些权重对 g(x_j) 做加权求和。
因此,如果用今天更熟悉的语言来重新表述:
theta(x)近似对应 Queryphi(x)近似对应 Keyg(x)近似对应 Value
区别在于,Non-Local 的提出背景仍然是 CNN 特征图,而不是 token 序列。它关心的是如何把这种全局交互能力无缝插入到视觉 backbone 里,而不是从零构建一套纯 attention 架构。
theta / phi / g / W_z 四个部件分别做什么
把公式拆开后,四个部件的职责非常清楚:
theta:把当前位置投影到“查询空间”,表示当前位置想从全局找什么信息phi:把所有位置投影到“索引空间”,表示每个位置可以被怎样匹配g:把所有位置投影到“值空间”,表示真正被聚合回来的内容W_z:把聚合结果映回原通道数,并与输入做残差相加
这种拆分让模块很像一个通用的“全局交互层”:先算关系,再取值,再回写主干网络。也正因为输入输出 shape 保持一致,它才能作为 block 插入到现有网络中。
为什么残差连接让它可以即插即用
Non-Local Block 的输出是 ,这意味着它不是替换原特征流,而是在原特征流上增加一个全局交互分支。这样的设计有两个直接好处:
- 不破坏原 backbone 的局部建模能力
- 更容易插入已有网络而不改变整体拓扑
在工程实现里,很多人还会把输出投影初始化得更保守,使模块在训练初期更接近 identity mapping。我的 notebook 也采用了这种写法,这样更容易观察“新增全局分支”到底带来了什么增益。
为什么它通常插在下采样后的特征图上
Non-Local 的优势来自全局关系矩阵,但代价也同样来自这里。若位置总数记为 ,那么关系矩阵的大小就是 。这意味着时间维一长、空间分辨率一大,计算和显存开销都会迅速上升。
因此工程上一个非常常见的做法是:先用卷积完成局部特征提取和下采样,再在较低分辨率的特征图上插入 Non-Local Block。这样既保留全局建模能力,又能把二次复杂度控制在可接受范围内。
实验结果
论文的实验结论有一个非常重要的特点:Non-Local 的收益并不局限于某一个 benchmark,而是在多类视觉任务上都表现出一致性。
在视频分类上,作者报告 Non-Local 网络在 Kinetics 和 Charades 上达到了与当时领先方法相当甚至更好的结果。这说明模块带来的增益并不是“多加一层参数”这么简单,而是它确实帮助网络建模了原本难以通过局部操作捕获的长距离时空依赖。
在静态视觉任务上,作者进一步把 Non-Local Block 插入到 COCO 的目标检测、实例分割和人体姿态估计系统中,同样观察到稳定提升。这一点尤其关键,因为它说明 Non-Local 并不绑定某一种特定 backbone,也不只服务于视频任务;它更像一种可迁移的通用结构能力。
从研究史的角度看,Non-Local 最重要的实验意义并不是“某张表里高了几个点”,而是它证明了:全局依赖建模本身值得被单独设计成一个模块。后来的视觉 Transformer、时空 attention,以及各种 hybrid 架构,本质上都在继续强化这件事。
总结
Non-Local 的核心贡献可以压缩成三句话:
- 它把视觉中的长距离依赖建模写成了一个清晰、通用、可插拔的算子
- 它让 CNN 特征图第一次以非常直接的方式具备了全局内容自适应交互能力
- 它在视频分类与 COCO 多任务上的有效性,证明全局关系建模不是附属技巧,而是重要的结构能力
当然,它的局限也非常明确:关系矩阵带来的二次复杂度,使它在高分辨率或长视频上成本不低。也正因此,后续研究一方面继续保留它的“全局交互”思想,另一方面则不断寻找更高效的 attention 近似与分层结构。
代码实战
为了把论文里的公式真正落到可运行代码,我配套实现了一份教学型 notebook,专门对比两条路径:学习路径与工程路径。前者手写 theta / phi / g、关系矩阵与残差连接,后者则用 nn.MultiheadAttention 复现同类全局聚合思想。这样写的目的不是做“谁替代谁”的比较,而是把理解论文和工程落地这两个目标明确分开。
完整代码实战:
![]()
第一段最关键的代码,是手写 Embedded Gaussian 版本的 Non-Local Block。它把论文里的公式几乎一比一翻译成了张量操作:
class NonLocalBlock3D(nn.Module):
def __init__(self, in_channels):
super().__init__()
inter_channels = max(1, in_channels // 2)
self.inter_channels = inter_channels
self.theta = nn.Conv3d(in_channels, inter_channels, kernel_size=1)
self.phi = nn.Conv3d(in_channels, inter_channels, kernel_size=1)
self.g = nn.Conv3d(in_channels, inter_channels, kernel_size=1)
self.W_z = nn.Conv3d(inter_channels, in_channels, kernel_size=1)
nn.init.zeros_(self.W_z.weight)
nn.init.zeros_(self.W_z.bias)
def forward(self, x):
b, c, t, h, w = x.shape
n = t * h * w
theta = self.theta(x).view(b, self.inter_channels, n)
phi = self.phi(x).view(b, self.inter_channels, n)
g = self.g(x).view(b, self.inter_channels, n)
affinity = torch.bmm(theta.transpose(1, 2), phi)
attention = F.softmax(affinity, dim=-1)
y = torch.bmm(g, attention.transpose(1, 2))
y = y.view(b, self.inter_channels, t, h, w)
return self.W_z(y) + x这段实现最值得看的不是代码量,而是 shape 语义:先把 (B, C, T, H, W) 展平为全局位置数 ,再构造 (B, N, N) 的关系矩阵。只要把这一步彻底看懂,Non-Local 的核心思想就已经掌握了。
第二段代码展示的是更贴近工程使用方式的版本。这里直接利用 PyTorch 的 nn.MultiheadAttention,把时空特征图展平成 token 序列,再复用成熟的 attention API:
class NonLocalBlockMHA(nn.Module):
def __init__(self, in_channels):
super().__init__()
inter_channels = max(1, in_channels // 2)
self.inter_channels = inter_channels
self.pre = nn.Conv3d(in_channels, inter_channels, kernel_size=1)
self.attn = nn.MultiheadAttention(
embed_dim=inter_channels,
num_heads=1,
dropout=0.0,
batch_first=True,
)
self.post = nn.Conv3d(inter_channels, in_channels, kernel_size=1)
nn.init.zeros_(self.post.weight)
nn.init.zeros_(self.post.bias)
def forward(self, x):
b, c, t, h, w = x.shape
n = t * h * w
reduced = self.pre(x)
tokens = reduced.reshape(b, self.inter_channels, n).transpose(1, 2)
out, _ = self.attn(tokens, tokens, tokens)
out = out.transpose(1, 2).contiguous().reshape(
b, self.inter_channels, t, h, w
)
return self.post(out) + x这里的 batch_first=True 很关键,因为它让 nn.MultiheadAttention 接受 (batch, seq, feature) 排布。于是只要把时空特征图整理成 (B, N, C_mid),就能用高层 API 快速得到一个工程化的全局交互模块。
如果你是在准备面试或论文复现,这份 notebook 最有价值的地方不是“能跑起来”,而是它把问题拆得足够清楚:学习路径负责把公式、shape 与数据流真正讲透,工程路径负责把同一思想迁移到现代工具链。更推荐的学习顺序通常是:先手写理解,再用高层 API 落地。
参考文献
- Wang, X., Girshick, R., Gupta, A., & He, K. (2018). Non-Local Neural Networks. CVPR 2018.
- CVPR 2018 Official Page. Non-Local Neural Networks.
- Facebook Research. video-nonlocal-net.
- PyTorch Documentation.
torch.nn.MultiheadAttention.