A Closer Look at Spatiotemporal Convolutions for Action Recognition
Du Tran, Heng Wang, Lorenzo Torresani, Jamie Ray, Yann LeCun, Manohar Paluri — CVPR 2018 (Facebook Research / Dartmouth College)
R(2+1)D 是视频理解里一篇很有代表性的“结构复盘型”论文。它没有先追求更深的网络、更多的数据增强或更复杂的训练配方,而是先退回一步,认真追问:3D 卷积为什么有效,又为什么经常难训。
这篇论文最重要的贡献,并不只是提出一个新名字的 block,而是在统一的 residual learning 框架下系统比较多种时空卷积结构,最后得到一个非常有穿透力的结论:把 3D 卷积拆成空间 2D 卷积加时间 1D 卷积,在参数量近似不变的前提下,往往更容易优化,也更容易取得更好的结果。今天再看 SlowFast、X3D 乃至很多视频 backbone 的设计,你依然能看到这种“先空间、后时间”的思想残影。
研究动机
在这篇论文之前,视频动作识别大致沿着两条路线演进。
- 逐帧 2D CNN:先对单帧提取空间特征,再在更高层做时间聚合。它成本低、训练稳,但时间建模通常不够直接。
- 全 3D CNN:直接在时间、高度、宽度三个维度上卷积,时空建模更自然,但计算和显存开销都更大,优化也更困难。
作者注意到一个关键现象:简单的 2D frame-based 模型并没有比 3D 模型差得离谱。这说明问题并不只是“要不要做时间建模”这么简单,更深一层的问题是:时间信息究竟应该如何进入卷积网络,才最利于学习。
因此,这篇论文真正想解决的不是“发明一种新的视频网络”,而是更基础的结构问题:
- 3D CNN 的收益,究竟来自真正更合理的时空建模,还是只是更大的容量?
- 如果 3D 卷积确实有效,能否换一种更容易训练的参数化方式来表达同样的时空感受野?
换句话说,论文要回答的是:视频里的空间模式和时间模式,应该在哪一层、以什么方式耦合。
核心方法/模型架构
论文把视频卷积网络里的设计空间拆成五种代表性结构,并在统一框架下做控制变量比较。
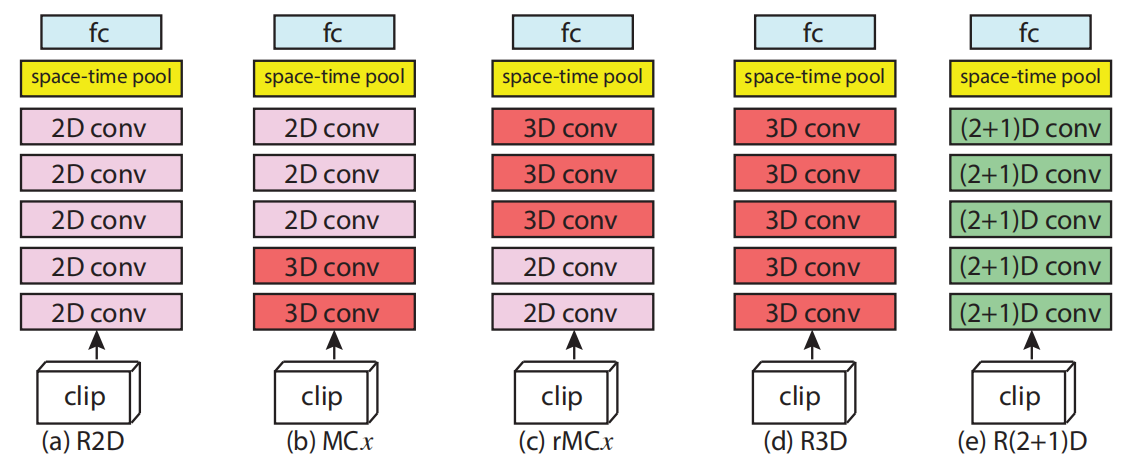
- R2D:把时间维折叠进通道维,本质上退化成纯 2D CNN。
- MCx:底层使用 3D 卷积,上层改用 2D 卷积,强调先抓局部时空模式,再降低计算成本。
- rMCx:底层先用 2D 卷积逐帧提特征,上层再切换到 3D 卷积做时间融合。
- R3D:在 ResNet 风格 backbone 上全程使用 3D 卷积,是最直接的时空卷积基线。
- R(2+1)D:把一个标准 3D 卷积拆成空间卷积与时间卷积两步,是论文最后给出的最优设计。
R(2+1)D 的核心想法可以写成一组非常直观的公式。对一个标准的 3D 卷积,不再一次性同时学习时间与空间关系,而是拆成两步:
这里最重要的不是“把 3D 变成 2D + 1D”这句口号本身,而是它背后的建模顺序:先在每一帧内部整理空间结构,再沿时间维做动态融合。
组件详解
五种结构到底在比较什么
这篇论文真正高明的地方,是它没有把不同论文里的 backbone、训练细节、数据处理流程全都混在一起比较,而是尽量把变量限制在“时空卷积结构本身”。因此,五种结构的对比,本质上是在问同一个问题:时间维应该在网络的哪一层、以什么方式进入表示学习。
- R2D 几乎放弃显式时间卷积,把视频当成特殊形式的图像输入。
- MCx 认为底层局部运动更重要,所以时间维应在浅层就介入。
- rMCx 则认为稳定外观更适合先学,时间维可以在高层再融入。
- R3D 选择最统一的策略:从头到尾都直接做 3D 卷积。
- R(2+1)D 则把焦点放在同样的 3D receptive field 是否能用更好优化的方式表达。
所以 R(2+1)D 不是简单的“降维”或“低秩近似”,而是在不放弃时空联合建模的前提下,重新组织参数和非线性的位置。
参数量匹配:为什么需要
如果只是随意把 3D 卷积拆开,模型参数量会跟着变化。那么最终效果到底来自结构改进,还是来自容量变化,就很难说清楚。为避免这个问题,论文专门为中间通道数 设计了近似参数匹配公式:
其中:
- 是输入通道数
- 是输出通道数
- 是时间卷积核大小
- 是空间卷积核大小
它的作用非常明确:让 R(2+1)D 与原始 3D 卷积在参数预算上尽量公平。只有在这个前提下,实验里观察到的性能差异才更能被归因到参数化方式本身,而不是“模型更大”。
为什么拆开后更容易优化
论文和配套误差曲线反复强调的并不是“R(2+1)D 参数更少”,而是“R(2+1)D 更好训”。这背后至少有两层原因。
第一,优化目标更清晰。标准 3D 卷积要在一次线性映射里同时学习空间纹理、局部形状与时间变化,而 R(2+1)D 把这个任务拆成两步,让网络先学每帧内部的空间模式,再学帧间动态关系。
第二,中间多出一次非线性。单个 3D 卷积本质上只有一次线性变换,而 R(2+1)D 在空间卷积与时间卷积之间显式插入一次 ReLU,等于在近似相同参数量下增加了一层有效变换。
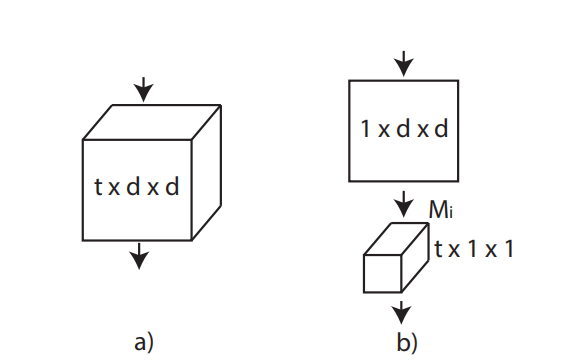
从表示学习的角度看,这种分解相当于告诉网络:先把“看到了什么”整理清楚,再去学习“它怎样变化”。对视频任务而言,这个 inductive bias 本身就更接近问题结构。
它与 R3D、I3D 的关系
R(2+1)D 最容易和另外两条视频模型路线混淆。
- R3D:ResNet 风格的全 3D 卷积网络,和 R(2+1)D 的差别主要在于卷积核是否拆分。
- I3D:把成熟的 2D CNN inflate 成 3D CNN,重点在于如何把图像预训练权重迁移到视频模型。
如果说 I3D 主要解决的是“2D 能力怎么带进 3D”,那么 R(2+1)D 主要解决的就是“3D 卷积本身怎样参数化才更利于训练”。两者都服务于视频理解,但回答的并不是同一个问题。
实验结果
论文的实验是在统一 residual learning 框架下进行的,核心结论可以压缩为三点。
第一,3D CNN 普遍优于逐帧 2D CNN。这说明视频任务里显式时空建模确实有价值,而不仅仅是对外观特征做更复杂的堆叠。
第二,把 3D 卷积分解成空间组件与时间组件后,性能还能进一步提升。这直接导向了 R(2+1)D block,也说明“更合理的参数化”本身就是性能来源。
第三,R(2+1)D 构建的网络在 Sports-1M、Kinetics、UCF101、HMDB51 等数据集上达到或超过当时强基线。从历史位置看,这篇论文的重要性不只是提出一个 block,而是把视频卷积网络的结构搜索从“拍脑袋试”推进到“控制变量地比较”。
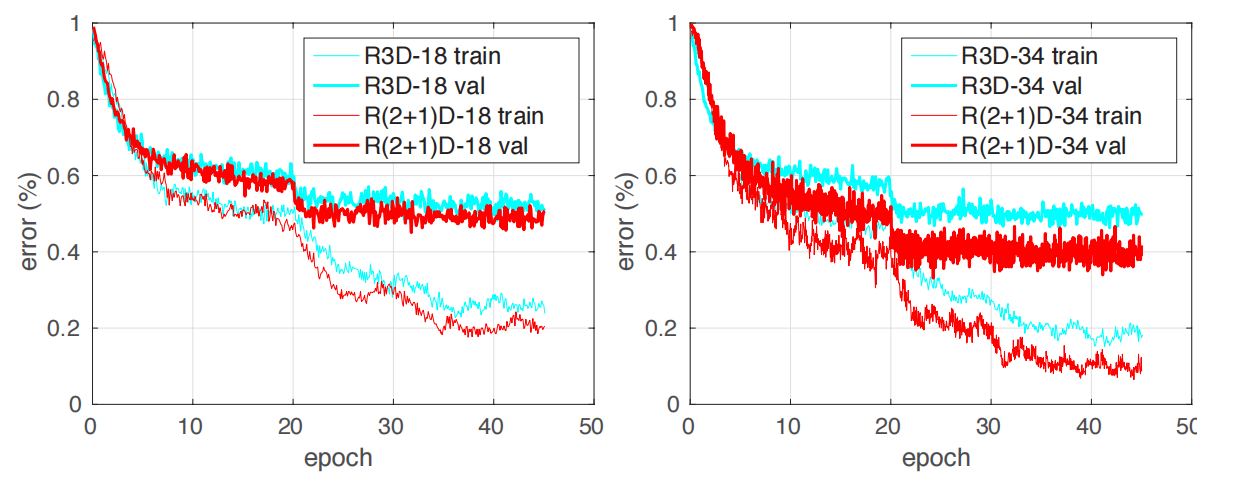
这张训练 / 测试误差曲线尤其关键。它说明 R(2+1)D 的优势不只是泛化层面的偶然收益,而更像是:网络本身确实更容易被优化器学好。如果一种结构同时降低训练误差和测试误差,通常比单纯依赖正则化的解释更有说服力。
总结
R(2+1)D 的核心价值可以概括为三句话。
- 它把 3D 卷积重新表述成“空间建模 + 时间建模”的组合问题。
- 它在近似相同参数预算下,用更好的参数化方式换来了更强表现与更低优化难度。
- 它给后续视频 backbone 留下了很实用的方法论:当时空联合建模太难训时,先拆开,再在结构上重新组合,往往比盲目加深网络更有效。
当然,R(2+1)D 也不是终点。它依然属于卷积式视频模型,长程时序建模能力有限,计算成本也不算低。但它提出的问题意识非常重要:不是所有“更强”的结构都来自更大规模,有时真正关键的是参数化方式是否与任务结构匹配。
代码实战
为了把论文里的结构思想落到可运行代码,我配套做了一份 Notebook,专门把 学习路径 和 工程路径 放在同一份文件里:前者从零手写 R(2+1)D block,并与 R3D 做对照训练;后者直接调用 torchvision.models.video.r2plus1d_18,展示工业库里的高层实现。
完整代码实战:
![]()
我觉得这份 Notebook 最有价值的地方,不是“把论文复刻了一遍”,而是把同一个想法放在两个抽象层级里并排展示。
| 路径 | 重点 | 适合场景 |
|---|---|---|
| 学习路径 | 手写 (2+1)D block、理解 公式、对照 R3D 训练曲线 | 面试准备、原理拆解、研究原型 |
| 工程路径 | 直接使用 torchvision.models.video.r2plus1d_18 builder | baseline 验证、工程接入、快速试错 |
第一段最关键的代码,是论文里 分解在 PyTorch 中的最小实现。这里最重要的不是语法细节,而是你能直接看到:空间卷积、非线性激活、时间卷积 是如何按顺序串起来的。
class R2Plus1DConv(nn.Module):
def __init__(self, in_ch, out_ch, t=3, d=3):
super().__init__()
self.mid_ch = max(
1,
math.floor((t * d * d * in_ch * out_ch) / (d * d * in_ch + t * out_ch))
)
self.spatial = nn.Sequential(
nn.Conv3d(in_ch, self.mid_ch, kernel_size=(1, d, d), padding=(0, d // 2, d // 2)),
nn.BatchNorm3d(self.mid_ch),
nn.ReLU(inplace=True),
)
self.temporal = nn.Sequential(
nn.Conv3d(self.mid_ch, out_ch, kernel_size=(t, 1, 1), padding=(t // 2, 0, 0)),
nn.BatchNorm3d(out_ch),
)
def forward(self, x):
x = self.spatial(x)
x = self.temporal(x)
return x第二段代码展示工程路径。根据 TorchVision 官方文档,视频分类模型的典型输入布局是视频张量 (B, C, T, H, W)。因此在我的 Notebook 里,toy 数据最初是灰度视频 (B, 1, T, H, W),要先复制到 3 通道,再交给 builder。
from torchvision.models.video import r2plus1d_18
engineering_model = r2plus1d_18(weights=None, num_classes=NUM_CLASSES)
batch_videos = torch.randn(2, 1, 8, 16, 16)
sample_rgb = batch_videos.repeat(1, 3, 1, 1, 1)
logits = engineering_model(sample_rgb)这种双路径写法的价值在于:如果你是为了理解论文,学习路径能帮你看清 公式、shape 变化与优化逻辑;如果你是为了做工程 baseline,builder 路径则更接近真实项目里的使用方式。
参考文献
- Tran, D., Wang, H., Torresani, L., Ray, J., LeCun, Y., & Paluri, M. (2018). A Closer Look at Spatiotemporal Convolutions for Action Recognition. CVPR 2018.
- IEEE / CVF. A Closer Look at Spatiotemporal Convolutions for Action Recognition — CVPR 2018 page.
- PyTorch / TorchVision. Video classification models documentation.