Deep Residual Learning for Image Recognition
Kaiming He, Xiangyu Zhang, Shaoqing Ren, Jian Sun — CVPR 2016 (Microsoft Research)
ResNet(Deep Residual Learning)由何恺明等人于 2015 年提出,通过引入残差连接解决了深度网络的退化问题,在 ImageNet 分类竞赛中以 152 层网络夺冠,是深度学习发展史上的里程碑工作。残差连接这一思想后来深刻影响了 DenseNet、Transformer 等后续架构,已成为现代深度学习的标准组件。
研究动机
深度神经网络在层数增加时面临两个关键障碍:
- 梯度消失/爆炸:反向传播中梯度经过多层连乘后趋近于零或发散,导致网络难以训练。
- 退化问题(Degradation):更深的网络反而比浅层网络表现更差——训练误差和测试误差同时增大。这并非过拟合(过拟合的特征是训练误差低、测试误差高),而是优化本身出了问题。
理论上,一个更深的网络至少可以通过让新增层学习恒等映射来达到与浅层网络相同的效果,但实际中优化器很难做到这一点。ResNet 的目标正是:让网络深度的增加不会导致性能下降。
残差学习框架
残差块的设计思想
设网络某几层需要学习的目标映射为 ,ResNet 不直接学习 ,而是让这些层学习残差映射:
最终输出通过跳跃连接(shortcut connection)将输入直接加回:
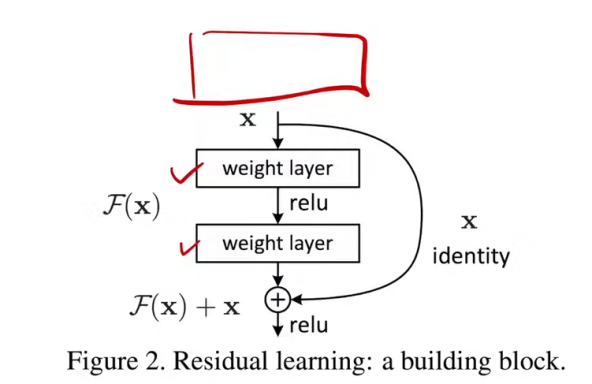
其中 通过跳跃连接直接传递到输出端,与经过两层权重层的 相加后再通过 ReLU 激活。
为什么这样更容易优化? 如果恒等映射是最优解,网络只需将残差 推向零即可——这比从头学习一个恒等函数要容易得多。
网络架构
基本残差块(BasicBlock)
基本残差块由两层 卷积组成,每层卷积后接 Batch Normalization 和 ReLU 激活。适用于较浅的网络(ResNet-18、ResNet-34)。
瓶颈残差块(Bottleneck)
对于更深的网络(ResNet-50/101/152),直接使用 卷积会导致计算量过大。瓶颈设计采用三层结构:
- 卷积:降低通道数(如 256 → 64),减少计算量
- 卷积:在低维空间进行空间卷积
- 卷积:恢复通道数(如 64 → 256),保证输入输出维度一致以便相加
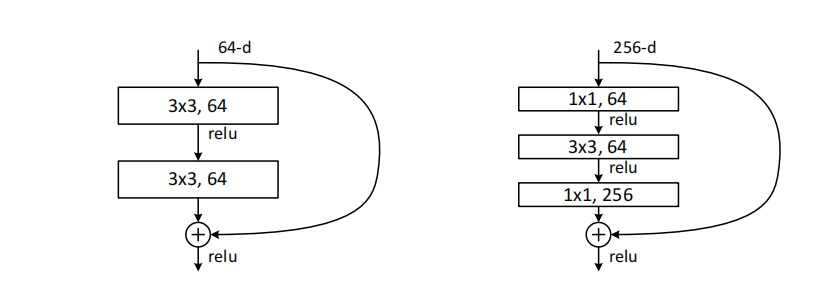
这种设计使得块的输入和输出通道数保持一致(如均为 256),同时大幅减少了中间层的计算开销。
架构配置
下表展示了 ResNet 各版本的具体配置。当特征图尺寸减半时,通道数加倍,以保持每层的计算复杂度大致相当。
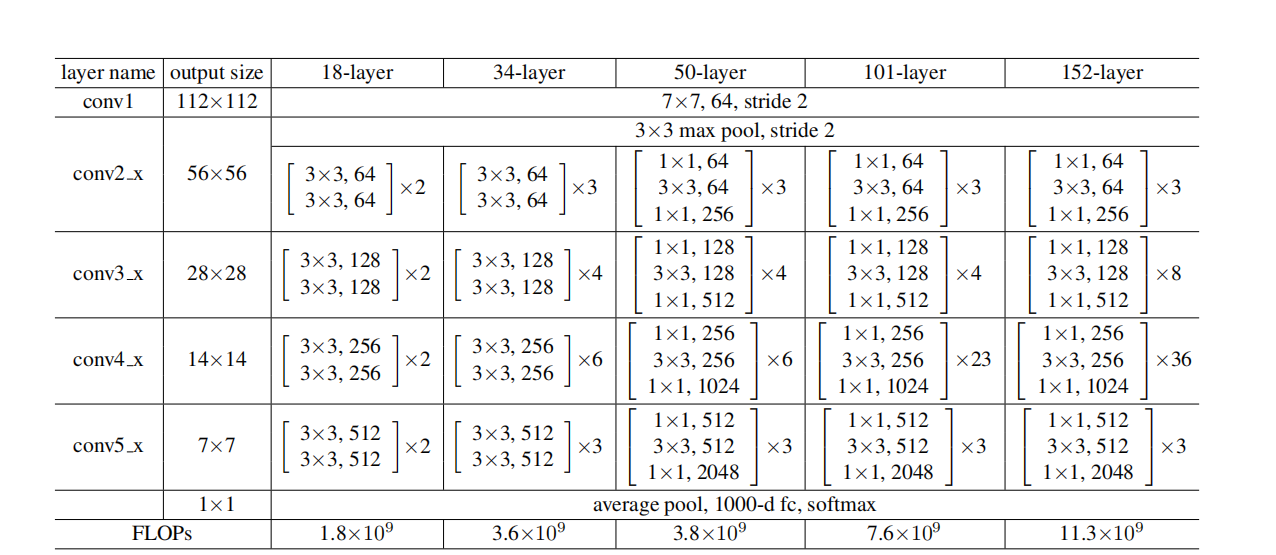
卷积层 FLOPs 计算公式:
其中 为输出特征图尺寸, 为输入输出通道数, 为卷积核大小。 卷积仅改变通道维度而不改变空间维度;通常在下采样阶段设置 stride=2,使空间尺寸减半、通道数翻倍。
实验结果
Plain 网络 vs ResNet
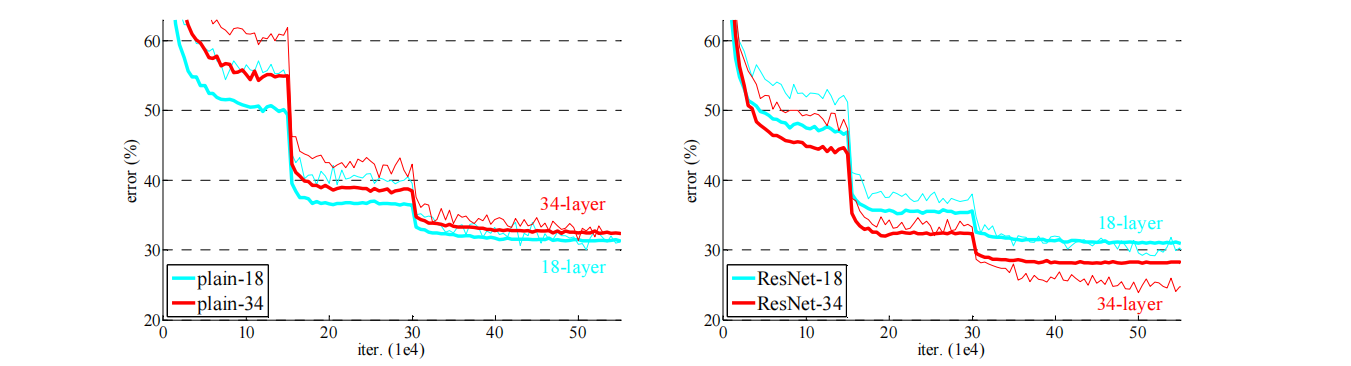
- 左图(Plain 网络):34 层网络的误差高于 18 层网络,验证了退化问题的存在。
- 右图(ResNet):34 层 ResNet 的误差低于 18 层 ResNet,残差连接成功解决了退化问题。
曲线中的阶梯式下降是由学习率衰减造成的——每次学习率乘以 0.1 时误差会出现一次跳跃式下降。现代训练中更多采用余弦退火等平滑的学习率调度策略来替代这种阶梯式衰减。
CIFAR-10 上的结果
| 方法 | 层数 | 参数量 | 错误率(%) |
|---|---|---|---|
| Maxout | - | - | 9.38 |
| NIN | - | - | 8.81 |
| DSN | - | - | 8.22 |
| FitNet | 19 | 2.5M | 8.39 |
| Highway | 19 | 2.3M | 7.54 |
| ResNet | 110 | 1.7M | 6.43 |
| ResNet | 1202 | 19.4M | 7.93 |
ResNet-110 以仅 1.7M 参数取得了 6.43% 的最佳错误率。值得注意的是,1202 层的 ResNet 性能略有下降(7.93%),可能存在过拟合。但关键在于:即使网络深度远超必要,残差连接也能保证模型不会严重退化——多余的层只是学不到有用的东西,而不会破坏已有的表征。
残差连接与梯度传播
残差连接之所以有效,可以从梯度传播的角度理解。
无残差连接时,梯度通过链式法则逐层相乘:
每一项梯度通常小于 1,多层连乘后梯度趋近于零——这就是梯度消失问题。
有残差连接时,输出为 ,梯度变为:
梯度中多了一个加性项 ,即使乘性项趋近于零,梯度仍然不会消失。这解释了两个现象:
- 深层网络可以训练:梯度不会消失
- 收敛更快:梯度信号更强,参数更新更有效
总结
ResNet 通过简洁的残差连接设计,从根本上解决了深度网络的退化问题和梯度消失问题。其核心洞察——让网络学习残差而非完整映射——使得训练上百层甚至上千层的网络成为可能。这一思想深刻影响了后续的网络设计(如 DenseNet、Transformer 等),残差连接已成为现代深度学习架构的标准组件。
代码实战
以下展示 ResNet-18 在 CIFAR-10 上的核心实现。完整代码包含手写实现与 torchvision 简洁实现两种方式的对比。
![]()
BasicBlock — 残差块核心实现:
class BasicBlock(nn.Module):
"""基本残差块:两层 3×3 卷积 + 快捷连接。"""
expansion = 1
def __init__(self, in_channels, out_channels, stride=1, downsample=None):
super().__init__()
self.conv1 = nn.Conv2d(in_channels, out_channels, kernel_size=3,
stride=stride, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(out_channels)
self.conv2 = nn.Conv2d(out_channels, out_channels, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn2 = nn.BatchNorm2d(out_channels)
self.relu = nn.ReLU(inplace=True)
self.downsample = downsample
def forward(self, x):
identity = x
out = self.relu(self.bn1(self.conv1(x)))
out = self.bn2(self.conv2(out))
if self.downsample is not None:
identity = self.downsample(x)
out += identity # H(x) = F(x) + x
out = self.relu(out)
return outResNet-18 完整组装(CIFAR-10 适配版,将 conv1 从 7×7/stride=2 改为 3×3/stride=1,移除 maxpool):
class ResNet18Scratch(nn.Module):
def __init__(self, block=BasicBlock, layers=(2, 2, 2, 2),
in_channels=3, num_classes=10):
super().__init__()
self.in_channels = 64
# Stem:3×3 Conv(替代 ImageNet 版的 7×7)
self.conv1 = nn.Conv2d(in_channels, 64, kernel_size=3,
stride=1, padding=1, bias=False)
self.bn1 = nn.BatchNorm2d(64)
self.relu = nn.ReLU(inplace=True)
# 4 个 Stage
self.layer1 = self._make_layer(block, 64, layers[0], stride=1)
self.layer2 = self._make_layer(block, 128, layers[1], stride=2)
self.layer3 = self._make_layer(block, 256, layers[2], stride=2)
self.layer4 = self._make_layer(block, 512, layers[3], stride=2)
self.avgpool = nn.AdaptiveAvgPool2d((1, 1))
self.fc = nn.Linear(512 * block.expansion, num_classes)
def _make_layer(self, block, out_channels, num_blocks, stride):
downsample = None
if stride != 1 or self.in_channels != out_channels * block.expansion:
downsample = nn.Sequential(
nn.Conv2d(self.in_channels, out_channels * block.expansion,
kernel_size=1, stride=stride, bias=False),
nn.BatchNorm2d(out_channels * block.expansion),
)
layers = [block(self.in_channels, out_channels, stride, downsample)]
self.in_channels = out_channels * block.expansion
for _ in range(1, num_blocks):
layers.append(block(self.in_channels, out_channels))
return nn.Sequential(*layers)
def forward(self, x):
x = self.relu(self.bn1(self.conv1(x)))
x = self.layer1(x)
x = self.layer2(x)
x = self.layer3(x)
x = self.layer4(x)
x = self.avgpool(x)
x = torch.flatten(x, 1)
x = self.fc(x)
return xtorchvision 简洁实现(等价架构,仅需修改 conv1 和 maxpool):
from torchvision import models
net = models.resnet18(num_classes=10)
net.conv1 = nn.Conv2d(3, 64, kernel_size=3, stride=1, padding=1, bias=False)
net.maxpool = nn.Identity()参考文献
- He, K., Zhang, X., Ren, S., & Sun, J. (2016). Deep Residual Learning for Image Recognition. CVPR 2016.
- Mu Li. ResNet 论文逐段精读. 沐神论文精读系列.