SlowFast Networks for Video Recognition
Christoph Feichtenhofer, Haoqi Fan, Jitendra Malik, Kaiming He — ICCV 2019 (Facebook AI Research / UC Berkeley)
SlowFast 是视频理解发展中的一个关键转折点。它没有继续沿着“把单一路径 3D CNN 做得更深、更宽、更密”这条路线硬推,而是先追问一个更本质的问题:视频里的空间语义和快速运动,真的应该由同一条路径、用同一种时间分辨率去建模吗。作者给出的答案是否定的。
这篇论文真正有启发性的地方,不只是又一次刷新了 Kinetics 和 AVA 上的结果,而是把视频建模拆成了两个职责清晰的子问题:Slow 路径负责低频语义,Fast 路径负责高频运动。相比依赖光流的 Two-Stream,SlowFast 只用 RGB 就把双时间尺度建模显式写进了网络结构本身;相比统一时空建模的 I3D 或 R(2+1)D,它进一步强调了“时间分工”而不是“单路径统一堆叠”。
研究动机
SlowFast 的设计灵感,部分来自人类视觉系统里对静态外观和动态变化的分工。论文用 P/M 细胞的类比来帮助理解:有些通路更适合稳定地识别“是什么”,另一些通路更适合快速响应“怎么动”。这并不是说生物视觉系统和网络结构可以一一对应,而是提示我们:语义与运动也许天然就不该共享完全相同的时间建模策略。
在 SlowFast 之前,视频理解主流方法大致可以分成两类:
- Two-Stream:一条 2D CNN 看 RGB 外观,一条 2D CNN 看光流运动。优点是职责分离清楚,但运动信息高度依赖光流预处理,训练和部署链路都比较重。
- 3D CNN:直接在时间、高度、宽度三个维度上做卷积。优点是端到端统一建模,但同一条路径既要理解空间语义,又要追踪快速运动,很容易陷入时间分辨率与计算成本的矛盾。
问题的核心在于:语义信息和运动信息对时间采样的需求并不一样。识别“是什么”通常不需要看非常密的帧,因为相邻帧的空间内容高度冗余;但识别“怎么动”恰恰依赖更高的时间分辨率。如果把所有帧都高频送进一条重网络,代价会迅速变高;如果过早做时间下采样,又会把动作变化抹平。
SlowFast 的解决思路因此非常直接:让慢路径专注低频语义,让快路径专注高频运动,再通过横向连接把两者协同起来。它不是把视频模型继续做成一条更重的主干,而是把“时间尺度”本身提升为架构设计的一等公民。
核心方法/模型架构
SlowFast 的输入仍然是 RGB 视频,但进入网络后会被拆成两种时间采样:
其中 是 Slow 路径的时间步长, 是 Fast 相对 Slow 的速度比。论文还进一步控制 Fast 路径的通道预算:若 Slow 某层通道数为 ,Fast 通常只保留 个通道,其中 。直观理解就是:Slow 看得少但看得深,Fast 看得多但看得轻。
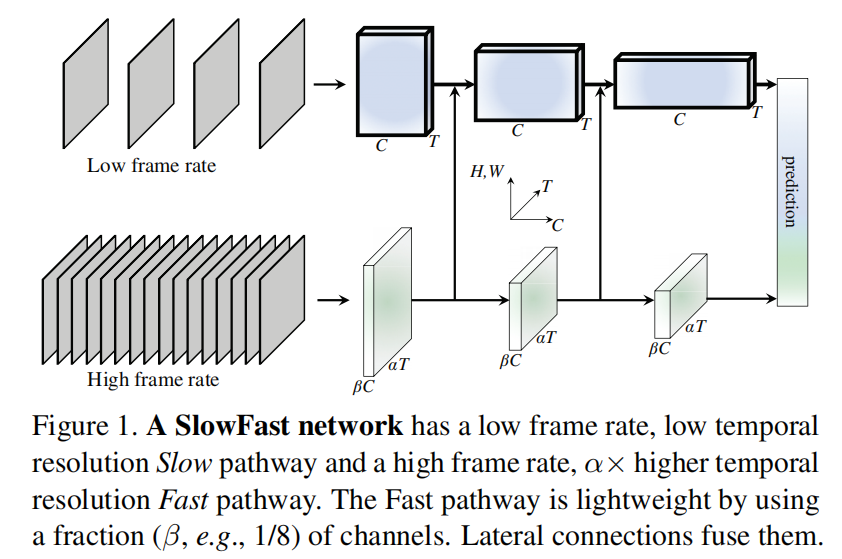
从职责划分上看,整个架构可以压缩成下面这张表:
| 路径 | 时间采样 | 通道预算 | 主要职责 |
|---|---|---|---|
| Slow pathway | 稀疏 | 高 | 捕获稳定空间语义 |
| Fast pathway | 稠密 | 低 | 捕获细粒度运动变化 |
这个设计最重要的,不是“并联两条网络”本身,而是两条路径对时间维采取了完全不同的预算策略。Slow 路径可以使用更强的主干去抽取语义特征,因为它只看稀疏帧;Fast 路径虽然看更多帧,但通道数显著更少,因此总体计算量仍然可控。按论文中的典型设定,Fast 路径只增加了相对有限的计算开销,却能显著补足动作变化建模。
组件详解
Slow 路径:低帧率建模稳定语义
Slow 路径是整个架构的语义主干。它使用较大的时间步长做稀疏采样,例如当 时,30 fps 视频里大约每秒只取 2 帧。这样做的直觉很简单:视频中大多数相邻帧在空间内容上高度相似,没有必要让最重的主干重复处理大量冗余信息。
因此,Slow 路径更像是一个语义聚合器。它负责理解人物、场景、姿态、物体关系等相对稳定的结构信息,也承担最终分类或检测表示里的主要语义负载。论文里这条路径可以直接复用成熟的 3D ResNet 类骨干,本质上是在保留强空间表征能力的前提下,把时间采样频率降低。
Fast 路径:高帧率捕获细粒度运动
Fast 路径是 SlowFast 真正的创新核心。它以更高的帧率读取视频,但显著压缩通道数,因此强调的是时间敏感性,而不是空间语义容量。
在论文设定里,Fast 路径通常满足两个特征:
- 时间采样更密:它会看到比 Slow 路径更多的帧,因此更容易捕捉加速、摆动、挥手、转身这类快速变化。
- 时间分辨率保持更久:网络大部分层尽量不在时间维做强下采样,让动态变化能持续保留下来。
- 通道数显著更小:它不是完整复制一条重主干,而是一个轻量级时间分支,重点是保住运动线索,而不是重复学习完整空间语义。
这种配置体现了一个很重要的判断:运动信息首先是一种时间结构,而不是一定要依赖很大通道容量才能表达的空间语义。也正因为如此,Fast 路径即使更轻,也依然能为整体模型提供非常有价值的动态线索。
横向连接:为什么是 Fast → Slow
SlowFast 不只是“各算各的”双路径。论文在多个阶段加入了从 Fast 到 Slow 的单向横向连接,让高时间分辨率特征周期性注入 Slow 主干中:
这里的关键不是相加这个操作本身,而是时间对齐。由于 Fast 的时间维通常是 Slow 的 倍,作者实验了多种对齐方式,包括时间步长采样、time-to-channel,以及时间步长卷积。论文结论是:时间步长卷积(time-strided convolution)效果最好,因为它既能做时间对齐,也让融合过程具有可学习性。
为什么连接方向通常是 Fast → Slow,而不是双向?原因在于职责分工。Fast 路径需要尽量保持对原始运动变化的敏感性,而 Slow 路径更适合作为语义主干去吸收这些动态情报。如果把 Slow 的低频语义大量反灌回 Fast,反而会削弱 Fast 作为“高时域侦察兵”的纯度。
最终融合:双路径在头部汇合
两条路径完成各自的时空建模后,会在尾部通过全局平均池化和拼接进行最终融合:
这个 head 很朴素,但它很好地体现了 SlowFast 的整体哲学:先分工,再汇总。Fast 不负责独立完成最终语义判断,而是提供高时域分辨率的补充证据;Slow 则在吸收这些动态信息后,承担更主要的判别职责。
SlowFast 和前代视频模型的关系
如果把视频理解模型放在一条演化线上看,SlowFast 的位置非常清楚:
- Two-Stream:显式把外观和运动分开,但运动严重依赖光流。
- I3D / R(2+1)D:把时空建模统一放入单路径 3D 卷积框架。
- SlowFast:进一步指出“时间尺度”本身值得单独拆成双路径来建模。
因此,SlowFast 的贡献不是简单替代所有 3D CNN,而是提出一种更细粒度的时间资源分配方式。它回答的问题是:既然不同信息类型对时间分辨率的需求不同,为什么还要强迫所有特征共享同一种时间采样策略。
实验结果
SlowFast 的实验结论可以概括为一句话:把高频运动信息单独交给一条轻量 Fast 路径,比在单一路径里一味加密时间采样更划算。
论文中的代表结果可以概括为:
| 任务 | 代表结果 | 说明 |
|---|---|---|
| Kinetics 视频分类 | 79.0% top-1 | 双路径时间分工显著提升动作识别 |
| AVA 动作检测 | 28.3 mAP | 高时域分辨率对检测同样有价值 |
这些结果重要的地方不只在于数值本身,更在于它们支撑了两个结构判断。
第一,运动信息确实值得单独开一条高帧率路径。如果只靠单一路径 3D CNN 同时完成语义和运动两类任务,模型要么时间分辨率不足,要么计算代价过高。SlowFast 证明了把二者显式拆分后,性能和效率可以取得更好的平衡。
第二,横向连接不是装饰,而是关键机制。论文比较了多种 Fast 到 Slow 的融合方式,最终发现时间步长卷积的横向连接最有效。这说明 Fast 路径的价值不只是“额外多一条辅助分支”,而是它确实在持续给 Slow 主干输送有判别力的动态补充。
需要注意的是,这些结论成立的前提是大规模视频数据、较强的主干网络和严格的视频训练流程。本文配套 Notebook 的定位是教学型实现,用来理解结构,而不是复现论文里的完整工程规模。
总结
SlowFast 的核心贡献可以压缩成三点:
- 它把视频理解中的语义与运动拆成了两条不同时间尺度的路径,而不是强迫所有信息共享同一种采样频率。
- 它用轻量 Fast 路径保留高时域分辨率,在不显著增加总计算量的前提下补足了动作变化建模。
- 它通过 Fast → Slow 横向连接把动态信息持续注入语义主干,让双路径不是简单并联,而是真正协同。
如果说 Two-Stream 的时代强调“外观和运动要分开看”,那么 SlowFast 更进一步强调:就算都只看 RGB,时间尺度本身也应该被拆开建模。这正是它对视频理解架构最持久的启发。
它的边界也同样明确:结构会比单路径 3D CNN 更复杂,长程依赖的建模能力仍主要受卷积感受野限制。但即便后来视频 Transformer 逐渐兴起,SlowFast 这套“按信息类型分配时间预算”的思想依然非常值得反复体会。
代码实战
为了把论文里的核心结构落到可运行代码,我配套写了一份教学型 Notebook。它不是 SlowFast-R50 的工业级复现,而是围绕三个最关键的问题展开:如何做双路径采样、如何实现 Fast → Slow 横向连接、如何把论文结构落成学习路径与工程路径两种 PyTorch 写法。
完整代码实战:
![]()
第一段关键代码,是双路径采样逻辑。它直接把原始视频拆成 Slow 和 Fast 两路输入,对应论文里的 和 两个核心超参数。
def sample_frames(videos, tau, alpha):
"""原始视频 -> Slow / Fast 两条路径输入
videos: (B, C, T, H, W)
"""
assert tau % alpha == 0, 'This notebook assumes tau is divisible by alpha.'
t_raw = videos.size(2)
assert t_raw % tau == 0, 'This notebook assumes clip length is divisible by tau.'
slow_idx = torch.arange(0, t_raw, tau)
fast_stride = tau // alpha
fast_idx = torch.arange(0, t_raw, fast_stride)
x_slow = videos.index_select(2, slow_idx.to(videos.device))
x_fast = videos.index_select(2, fast_idx.to(videos.device))
assert x_fast.size(2) == x_slow.size(2) * alpha
return x_slow, x_fast第二段关键代码,是 Fast → Slow 的横向连接。这里使用的是 time-strided Conv3d 对齐时间维,然后用残差相加把动态特征注入 Slow 路径。
class LateralConnection(nn.Module):
def __init__(self, fast_ch, slow_ch, alpha):
super().__init__()
self.proj = nn.Conv3d(
fast_ch,
slow_ch,
kernel_size=(alpha, 1, 1),
stride=(alpha, 1, 1),
bias=False,
)
self.bn = nn.BatchNorm3d(slow_ch)
def forward(self, x_slow, x_fast):
aligned_fast = self.bn(self.proj(x_fast))
assert aligned_fast.shape == x_slow.shape, 'Lateral fusion shape mismatch.'
return x_slow + aligned_fast第三段关键代码,则把双路径、横向融合和最终 head 组装成一个最小可训练版本。它最适合用来观察 SlowFast 的张量流动,而不是追求工业级复现。
class SlowFastNet(nn.Module):
def forward(self, x_slow, x_fast):
s1 = self.slow_stem(x_slow)
f1 = self.fast_stem(x_fast)
s1 = self.lateral1(s1, f1)
s2 = self.slow_block2(s1)
f2 = self.fast_block2(f1)
s2 = self.lateral2(s2, f2)
s3 = self.slow_block3(s2)
f3 = self.fast_block3(f2)
s_out = self.pool(s3).flatten(1)
f_out = self.pool(f3).flatten(1)
return self.fc(torch.cat([s_out, f_out], dim=1))完整 Notebook 还包含两种实现路径:
- 学习路径:从零实现
SlowFastNet,把 slow stem、fast stem、lateral fusion 和最终 head 的张量流动讲清楚。 - 工程路径:用更紧凑的
ConciseSlowFast表达同一结构思想,更适合做原型验证或面试展示。
这份代码实战的价值,不只是“能跑一个 toy video baseline”,而是它把 SlowFast 最容易讲抽象的部分拆成了可以直接观察的代码结构:双路径采样怎么做、Fast 为什么通道更小、横向连接为什么通常只从 Fast 指向 Slow。如果你是在准备面试、课程作业或论文复现,这种可运行版本会比只背结构图更有帮助。
参考文献
- Feichtenhofer, C., Fan, H., Malik, J., & He, K. (2019). SlowFast Networks for Video Recognition. ICCV 2019.
- 配套代码实战 Notebook. SlowFast Code Notebook.
- Carreira, J., & Zisserman, A. (2017). Quo Vadis, Action Recognition? A New Model and the Kinetics Dataset. CVPR 2017.
- Simonyan, K., & Zisserman, A. (2014). Two-Stream Convolutional Networks for Action Recognition in Videos. NeurIPS 2014.