Swin Transformer: Hierarchical Vision Transformer using Shifted Windows
Ze Liu, Yutong Lin, Yue Cao, Han Hu et al. — ICCV 2021 Best Paper (Microsoft Research Asia)
ViT 证明了 Transformer 可以做图像分类,但它在视觉密集任务里仍有两块短板:单尺度特征和全局注意力的平方复杂度。Swin Transformer 的价值就在于,它不是简单把 ViT 搬到视觉里,而是把“层级金字塔 + 局部建模 + 跨窗口通信”组合成了一套可落地的通用视觉 backbone。
摘要
这篇文章聚焦一个核心问题:为什么 ViT 在分类成功后,仍很难直接成为检测/分割的通用 backbone。
Swin Transformer 的答案可以概括为两点:
- 层级式特征图:通过 Patch Merging 构建金字塔特征,解决单尺度问题。
- 移动窗口注意力:在局部窗口内算注意力,再通过 Shifted Window 建立跨窗口连接,将复杂度从二次降到线性。
下文按“动机 -> 架构 -> 复杂度 -> SW-MSA 细节 -> 实验与讨论”展开。
引言与动机
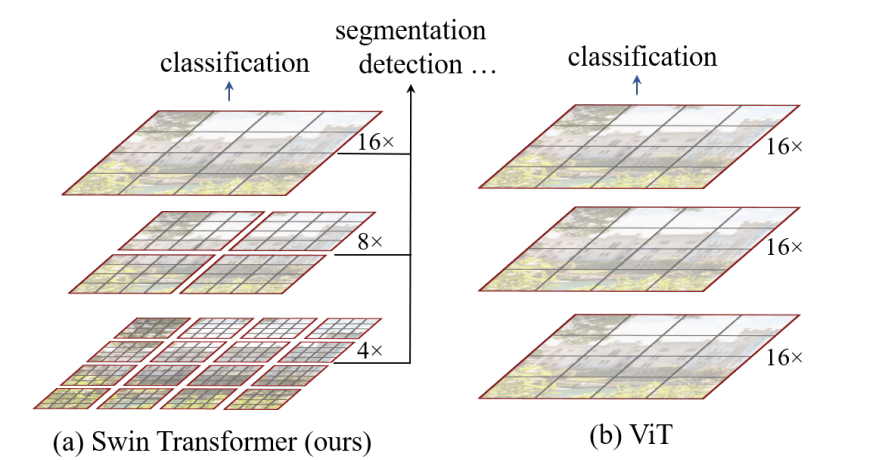
一句话概括:Swin 用窗口约束计算,ViT 用全局 Patch 计算。
ViT 在视觉密集任务里主要卡在两点:
- 尺度变化巨大:检测和分割依赖多尺度特征,而 ViT 的主干特征通常是单一分辨率。
- 高分辨率复杂度过高:全局注意力在输入变大后代价迅速上升,难以直接用于高分辨率密集预测。
从复杂度视角看,两者差异可以直接写成:
- ViT 使用全局自注意力,复杂度近似为 。
- Swin 把注意力限制在局部窗口,在窗口大小固定时复杂度近似为 。
ViT 的 patch_size 固定,当输入分辨率增大时,Patch 数上升会导致平方级开销;Swin 则因为每个窗口内计算规模固定,总开销主要随窗口数量线性增长。
| 对比维度 | ViT | Swin Transformer |
|---|---|---|
| 自注意力范围 | 全局 | 局部窗口 + 移动窗口 |
| 复杂度随分辨率变化 | 二次增长 | 线性增长 |
| 特征图结构 | 单尺度 | 多尺度层级 |
| 下游任务适配 | 以分类为主 | 分类/检测/分割通用 |
这也是 Swin 的核心价值:把 Transformer 变成可以像 ResNet 一样直接接到 FPN/U-Net 的通用骨干。
如何生成多尺度特征
在 CNN 里,多尺度通常来自 pooling/stride;在 Swin 里,对应操作是 Patch Merging。
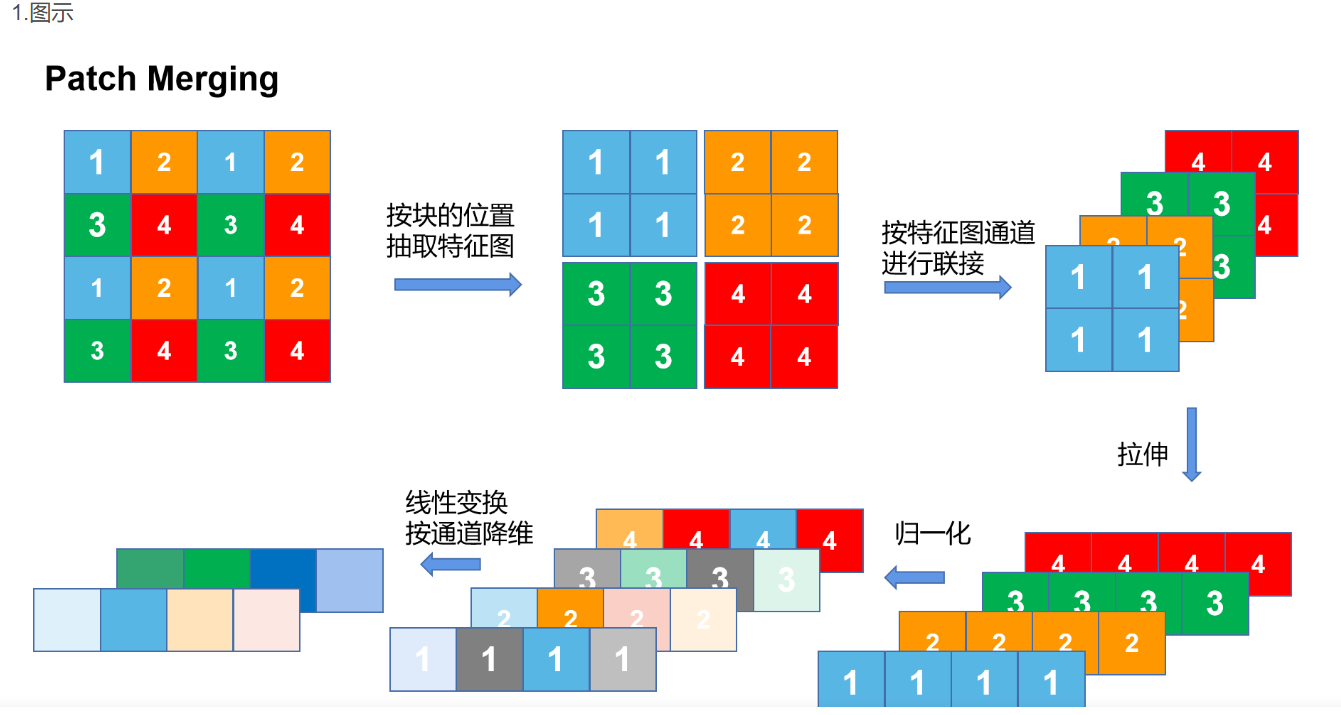
其思路可以理解为“空间降采样 + 通道重排 + 线性映射”:
- 对特征图做间隔采样,得到 4 个 子张量。
- 在通道维拼接为 。
- 再用线性层映射到 。
这一步可理解为 Pixel Shuffle 的逆过程:把空间分辨率折叠进通道,再做线性压缩。这样得到的层级特征可以直接接 FPN 做检测,或接 U-Net 做分割。
整体结构(以 Swin-T 为例)
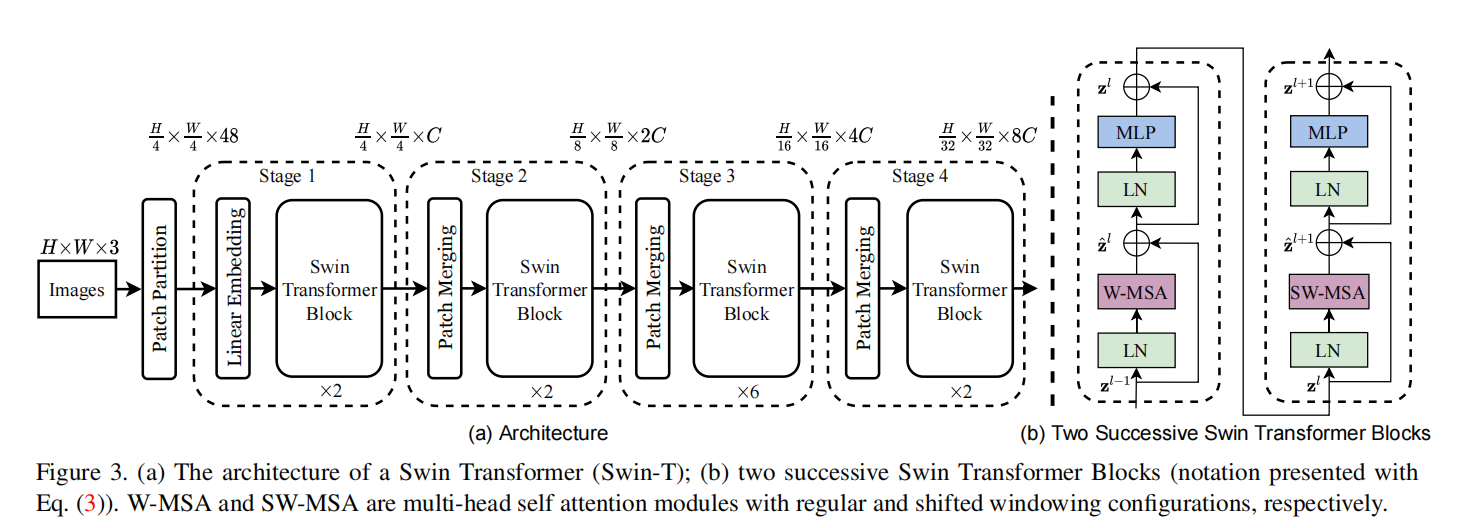
输入是 ,先做 Patch Partition + Linear Embedding:
然后进入 4 个 Stage,每个 Stage 内堆叠 Swin Transformer Block。Swin-T 的层数配置是 ,Stage 之间通过 Patch Merging 下采样并扩展通道。
通道与分辨率沿网络深度变化为:
对应到 Swin-T 的 Stage 级配置可写成:
| Stage | 分辨率 | 通道数 | Block 数 |
|---|---|---|---|
| Stage 1 | 96 | 2 | |
| Stage 2 | 192 | 2 | |
| Stage 3 | 384 | 6 | |
| Stage 4 | 768 | 2 |
最后经 Average Pooling 变为 ,再接分类头。这个流程和经典 CNN 在形态上非常接近,但核心计算单元从卷积替换成了窗口注意力。
窗口自注意力(W-MSA)
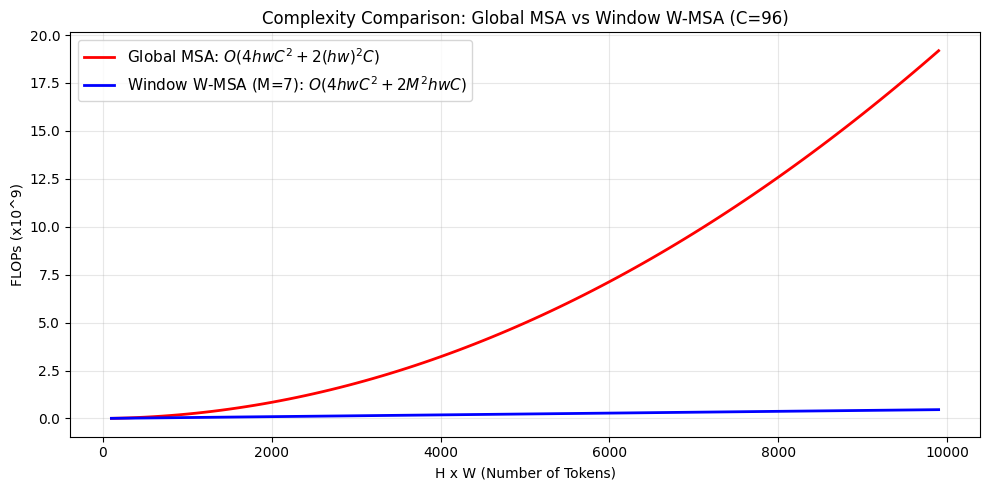
复杂度推导(详细版)
记 ,窗口大小为 ,每个窗口 token 数为 。全局 MSA 的主要开销可拆成四步:
- 线性映射得到 :约 。
- 计算注意力矩阵 :约 。
- 注意力矩阵与 相乘:约 。
- 输出投影:约 。
合并后得到:
若将注意力限制在 窗口内,窗口数量是 。把每个窗口开销乘以窗口数可得:
当 固定(默认 )时,复杂度关于 为线性。以第一阶段 为例,W-MSA 的 FLOPs 约为全局注意力的 1/8。
相对位置偏置
Swin 在注意力中加入相对位置偏置 :
窗口内相对坐标范围是 ,因此可学习偏置表大小为 。这种设计在密集预测里通常比绝对位置编码更稳。
核心创新:窗口注意力与移动窗口
这里的核心模块是“连续两个 Block 交替使用 W-MSA 与 SW-MSA”。其对应关系可写为:
以第一阶段特征图 为例,默认窗口大小是 ,因此窗口数量是 。
为什么需要 Shifted Window
只做 W-MSA 会导致窗口间没有通信,所以 Swin 在连续两个 block 里交替使用:
- W-MSA(常规窗口)
- SW-MSA(移动窗口)
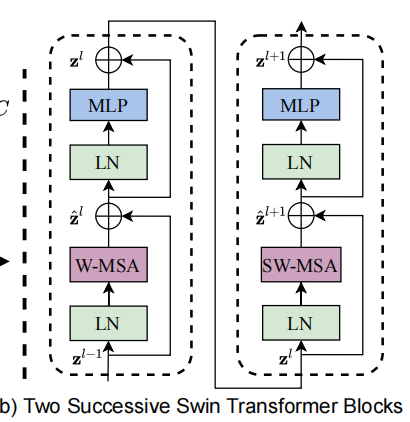
这样就把“局部高效”与“跨窗口信息流动”结合起来。
SW-MSA 的实现细节:Cyclic Shift + Mask
直接移动窗口会出现窗口数量变化和不规则分块问题。
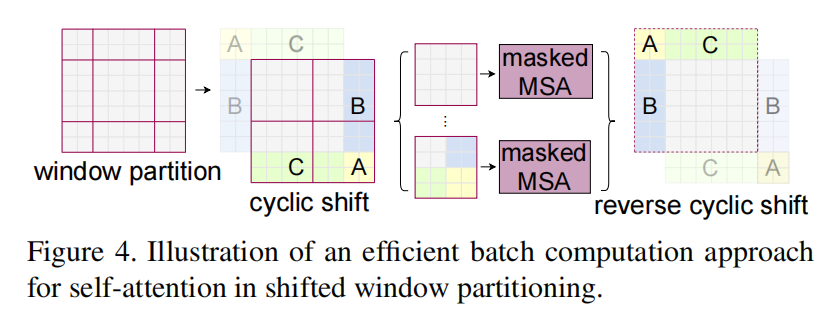
Swin 采用 Cyclic Shift:先对特征图循环位移,再按常规窗口切分。这样移位前后窗口数量保持一致,便于 batch 化计算。
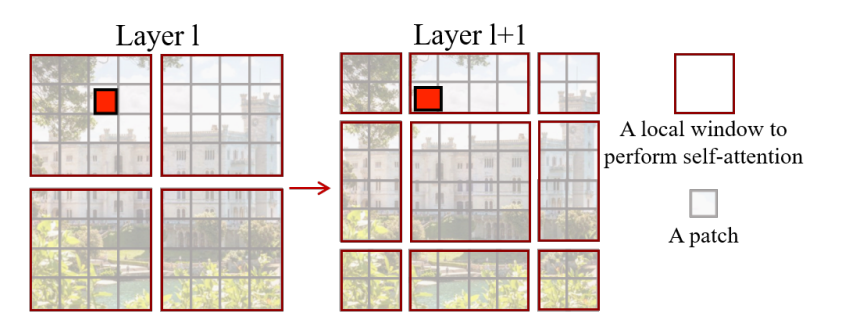
移位后原本不同窗口的 token 会进入同一个局部窗口参与注意力计算,这就是 SW-MSA 建立跨窗口连接的核心。
但 Cyclic Shift 会把空间上不相邻区域拼到同一窗口,需用 Mask 约束:
- 对循环移位后的区域做编号并展平。
- 先算注意力分数矩阵 。
- 构造掩码矩阵 :允许位置填 0,不允许位置填大负数(如 -100)。
- 计算 ,非法位置权重会趋近于 0。
- 注意力计算后再 reverse cyclic shift 回原位。
这个流程既保留了批处理友好性,也避免了错误的跨区域信息混合。
可以把它理解成“先制造跨窗口邻接,再用 Mask 切掉伪邻接”。
架构配置与实验结果
模型变体
| 变体 | 基础通道数 | 各 Stage 层数 | 参数量 | 对标 |
|---|---|---|---|---|
| Swin-T | 96 | 2, 2, 6, 2 | 28M | ResNet-50 |
| Swin-S | 96 | 2, 2, 18, 2 | 50M | ResNet-101 |
| Swin-B | 128 | 2, 2, 18, 2 | 88M | ViT-B |
| Swin-L | 192 | 2, 2, 18, 2 | 197M | — |
ImageNet 分类
| 模型 | 分辨率 | 参数量 | FLOPs | Top-1 |
|---|---|---|---|---|
| DeiT-S | 22M | 4.6G | 79.8% | |
| Swin-T | 29M | 4.5G | 81.3% | |
| DeiT-B | 86M | 55.4G | 83.1% | |
| Swin-B | 88M | 47.0G | 84.5% | |
| ViT-L/16 | 307M | 190.7G | 85.2% | |
| Swin-L | 197M | 103.9G | 87.3% |
COCO 检测与关键消融
在同等参数和 FLOPs 下,采用 Cascade Mask R-CNN 时,Swin-T 相比 ResNet-50 的 Box AP 提升约 +4.2,Mask AP 提升约 +3.3。更大模型结合更强检测策略后,Swin-L 可达到 58.7 Box AP。
关键消融结果显示:
- 去掉 Shifted Window,ImageNet Top-1 下降约 1.1%,COCO AP 下降约 2.8。
- 相对位置偏置优于绝对位置编码,尤其在密集预测任务中更稳定。
讨论与展望
创新价值
- 架构形态与 CNN 金字塔对齐,工程适配成本低。
- Window + Shift 设计同时解决了复杂度和跨窗口建模问题。
- 在检测和分割任务上实现了对传统 CNN backbone 的显著超越。
局限性
- 仍然依赖局部感受野堆叠来扩大信息范围,不是首层全局建模。
- 窗口大小、位移规则、Patch Merging 方式都带有较强人工设计先验。
适用边界
- 对高分辨率、密集预测友好的任务(检测、分割)通常更能体现 Swin 优势。
- 若任务更强调首层全局建模,纯局部窗口机制可能需要借助更大模型或额外全局模块补强。
小结
Swin Transformer 的价值不只是“指标高”,而是其工程形态真正接上了视觉任务生态:
- 层级特征让它天然兼容检测与分割框架。
- 局部窗口把复杂度从平方降到线性。
- Shifted Window + Mask 在效率和表达力之间取得了可用平衡。
这也是它能从分类扩展到通用视觉 backbone 的根本原因。
代码实战
完整代码包含两种实现——从零手写核心组件 vs 调用 torchvision 预训练模型:
![]()
实现 A:从零手写 Swin Transformer
逐组件实现适配 CIFAR-10(32x32)的小型 Swin Transformer:
核心的窗口注意力 + 相对位置偏置实现:
class WindowAttention(nn.Module):
def __init__(self, dim, window_size, num_heads):
super().__init__()
self.scale = (dim // num_heads) ** -0.5
# 相对位置偏置表: (2M-1)^2 x num_heads
self.relative_position_bias_table = nn.Parameter(
torch.zeros((2*window_size-1)**2, num_heads))
# 预计算相对位置索引
coords = torch.stack(torch.meshgrid(
torch.arange(window_size),
torch.arange(window_size), indexing='ij'))
relative_coords = coords[:,:,None] - coords[:,None,:]
# ... 偏移到非负并展平为查表索引
self.qkv = nn.Linear(dim, dim * 3)
def forward(self, x, mask=None):
qkv = self.qkv(x) # (nW*B, M*M, 3C)
q, k, v = ... # 分头
attn = (q @ k.T) * self.scale + relative_position_bias
if mask is not None:
attn = attn + mask # 移动窗口掩码
return softmax(attn) @ v循环移位实现 SW-MSA 的关键代码:
# 循环移位
shifted_x = torch.roll(x, shifts=(-shift, -shift), dims=(1, 2))
# 窗口划分 + 注意力计算(带掩码)
x_windows = window_partition(shifted_x, window_size)
attn_windows = self.attn(x_windows, mask=attn_mask)
# 逆循环移位
x = torch.roll(shifted_x, shifts=(shift, shift), dims=(1, 2))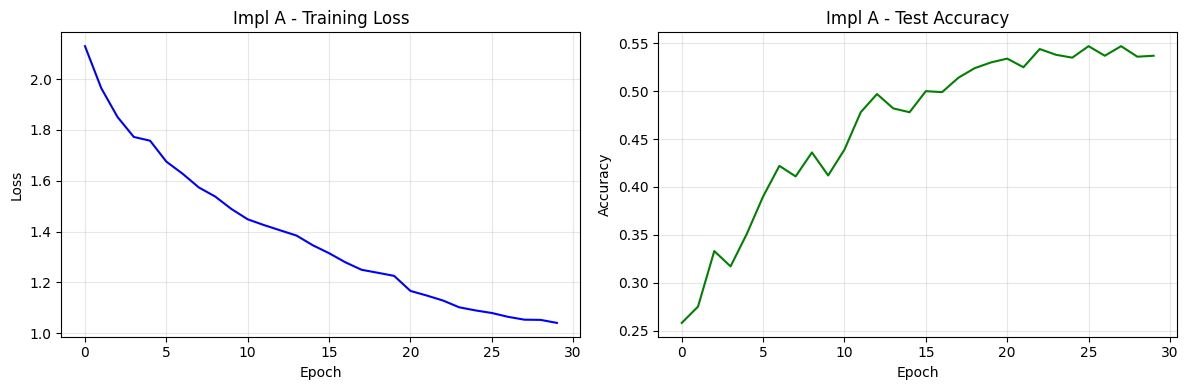
实现 B:torchvision 预训练微调
使用 torchvision.models.swin_t 加载 ImageNet 预训练权重,仅微调分类头:
from torchvision.models import swin_t, Swin_T_Weights
model = swin_t(weights=Swin_T_Weights.IMAGENET1K_V1)
model.head = nn.Linear(model.head.in_features, 10) # CIFAR-10
# 冻结骨干,仅训练分类头
for name, param in model.named_parameters():
if 'head' not in name:
param.requires_grad = False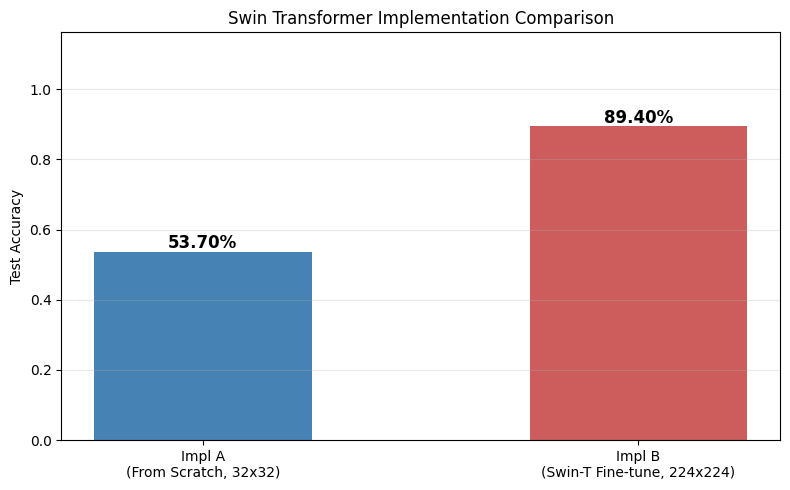
参考文献
- Liu, Z., Lin, Y., Cao, Y., et al. (2021). Swin Transformer: Hierarchical Vision Transformer using Shifted Windows. ICCV 2021 Best Paper.
- 李沐. Swin Transformer 论文精读. Bilibili.