Is Space-Time Attention All You Need for Video Understanding?
Gedas Bertasius, Heng Wang, Lorenzo Torresani — ICML 2021
TimeSformer 是视频理解进入 Transformer 时代的标志性工作。它不是把 ViT 机械搬到视频上,而是把问题收束为一个更关键的结构设计:时间维和空间维该如何组织注意力,才能既保留全局建模能力,又避免联合时空注意力带来的计算爆炸。
沿着 Two-Stream → I3D / R(2+1)D / SlowFast → Video Transformer 的演化线看,TimeSformer 的贡献在于把“视频 Transformer 应该怎样做”从一个口号,变成一组可以系统比较的时空注意力方案。
研究动机
在图像任务里,Vision Transformer 已经证明:只要 token 化和训练策略得当,自注意力可以成为一种很强的全局建模机制。但视频比图像多了一条时间维,问题随之立刻升级。
一方面,视频 token 数量会随帧数迅速增长。如果直接对所有时空 token 做联合注意力,计算量与显存占用都会迅速变得不可控。另一方面,TimeSformer 提出时,3D CNN 已经是很强的基线。因此,视频 Transformer 必须回答的不只是“能不能做”,而是:哪种时空注意力设计,才能把精度、效率和可扩展性同时拉到可接受区间。
换句话说,TimeSformer 真正要解决的是结构问题,而不是口号问题:时间维和空间维应该以什么顺序、在什么范围内发生交互,才最适合视频理解。
核心方法/模型架构
根据论文摘要与 ICML 2021 proceedings 页面,TimeSformer 是一个 attention-only 的视频识别模型:它不依赖 3D 卷积主干,而是把视频表示为一串 frame-level patches,再在 Transformer block 内定义不同的时空注意力邻域。
论文没有直接押注某一种结构,而是系统比较了五种把自注意力从 2D 图像扩展到 3D 视频的方法:
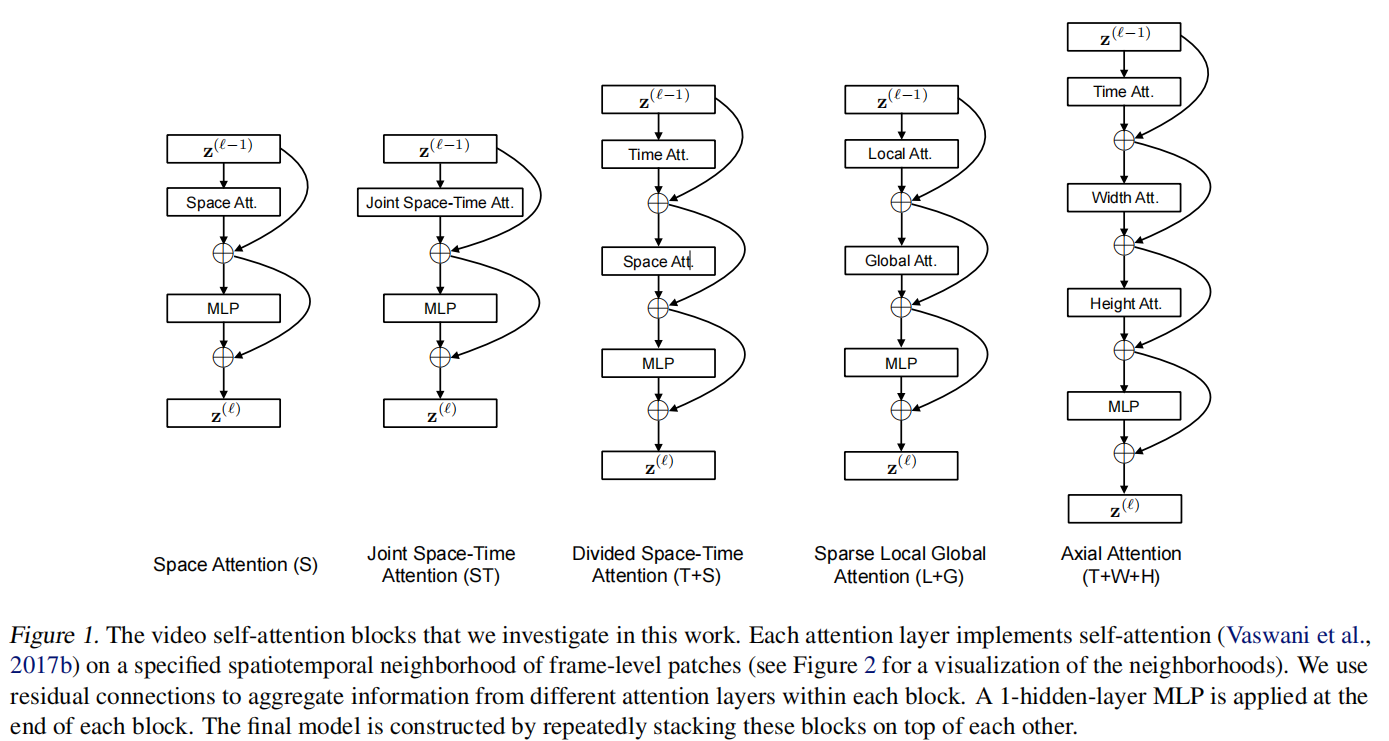
| 方案 | 缩写 | 核心做法 | 直觉特点 |
|---|---|---|---|
| Space Attention | S | 每帧内部独立做空间注意力 | 只能看单帧,无法建模跨帧关系 |
| Joint Space-Time Attention | ST | 所有时空 token 一次性全连接 | 表达力最强,但代价最高 |
| Divided Space-Time Attention | T+S | 先时间后空间分两步建模 | 在效率与表达力之间最均衡 |
| Sparse Local Global Attention | L+G | 先局部后全局地稀疏建模 | 用近似方式降低成本 |
| Axial Attention | T+W+H | 沿时间、宽度、高度分别建模 | 把 3D 注意力进一步分解 |
论文报告,在这五种设计里表现最好的是 Divided Space-Time Attention。它不一次性计算完整的联合时空注意力,而是把一个 block 拆成三步:
这个顺序的含义非常直接:先固定空间位置,只看跨帧变化;再固定时间帧,只看帧内空间关系。模型并没有放弃全局时空建模,而是把一次过于昂贵的 3D 交互拆成两个更可控的子问题。
组件详解
五种时空注意力到底在比较什么
五种方案本质上都在回答同一个问题:一个 query patch 到底应该和哪些时空 token 交互。
- S 几乎不看时间,只保留单帧空间关系。
- ST 一次性看全部时空 token,最完整,也最昂贵。
- T+S 先时间后空间,把问题拆成两个顺序清晰的步骤。
- L+G 用局部 + 全局的稀疏注意力近似完整交互。
- T+W+H 按时间轴、宽度轴和高度轴继续分解。
这也是 TimeSformer 真正有价值的地方:它没有把“视频 Transformer”当成一个抽象标签,而是把设计空间摆到同一框架下比较,因而能回答“哪种时空注意力更合适”而不只是“Transformer 也能做视频”。
为什么拆分时空注意力最有效
Divided Space-Time Attention 的优势不只是更省算力,而是它的归纳偏置更贴合视频本身。
- Temporal Attention 学的是同一位置在不同帧中的变化规律,回答“这里怎么动”。
- Spatial Attention 学的是同一帧里不同 patch 的空间关系,回答“这一帧内部如何组织”。
把这两步拆开之后,模型既保留了时空建模能力,又显著降低了联合时空注意力的代价。这种思路和 R(2+1)D 把 3D 卷积拆成空间卷积与时间卷积有明显相通之处:都不是放弃 3D 关系,而是通过结构分解让 3D 关系更容易学习、更容易计算。
注意力范围可视化
下图展示了五种方案对同一个 query patch 的关注范围:

从图里可以直接读出它们的差异:
- S 只看当前帧内部。
- ST 同时看所有帧与所有 patch,最完整也最昂贵。
- T+S 先沿时间轴聚合同位置 patch,再在单帧内建模空间关系。
- L+G 先局部、后全局,用稀疏方式近似完整时空交互。
- T+W+H 把注意力拆成时间轴、宽度轴和高度轴上的多个 1D 关系。
这张图其实浓缩了整篇论文的中心问题:视频 Transformer 最难的,不是有没有时间维,而是时间维和空间维应该如何以可承受的成本发生交互。
TimeSformer 在视频理解演化中的位置
TimeSformer 论文把视频理解的发展大致分成四个阶段:
- DeepVideo:最早把 CNN 用到大规模视频上,但运动建模仍偏弱。
- Two-Stream / TSN:显式把外观与运动拆开,建立了经典视频识别问题分解方式。
- I3D / R(2+1)D / Non-Local / SlowFast:3D CNN 系列持续强化时空联合建模。
- Video Transformer:开始尝试用注意力机制直接处理更长程、更全局的时空关系。
从这条脉络看,TimeSformer 的历史意义在于:它是最早把 Video Transformer 的结构问题讲清楚、拆清楚、并在主流视频基准上验证有效性的代表工作之一。
实验结果
根据 arXiv 摘要与 ICML 2021 proceedings 页面,TimeSformer 在多个动作识别基准上达到当时最好的结果,其中包括 Kinetics-400 和 Kinetics-600。更重要的是,论文强调最优的 divided attention 变体不仅精度强,而且在效率与扩展性上也更有吸引力。
这部分结论可以压缩成三条:
- 联合时空注意力并不自动等于最好。理论上它最完整,但实践中代价太高,未必换来最佳效果。
- 拆分时空注意力是论文里表现最好的设计。它在精度、训练速度和推理成本之间取得了更好的平衡。
- TimeSformer 的优势之一是长视频可扩展性。论文指出,相比 3D CNN,它支持处理超过 1 分钟的视频片段;在部分设置下,测试效率显著更高,而精度代价很小。
因此,这篇论文真正证明的不是“Transformer 已经彻底取代 3D CNN”,而是:视频理解也可以像图像和 NLP 一样,逐步转向统一的注意力式全局关系建模。
总结
TimeSformer 的核心贡献可以压缩成三点:
- 它把 ViT 稳健地扩展到了视频理解任务。
- 它系统比较了五种视频自注意力方案,而不是只给出单一结构。
- 它证明拆分时空注意力是一条兼顾精度、效率与可扩展性的路线。
如果只记一句话,我觉得最值得记住的是:TimeSformer 的价值不在于把注意力做得更大,而在于先把时空交互拆成结构清晰、计算可控的步骤,再去获得全局建模能力。这也是它后来影响 ViViT、MViT、Video Swin 等视频 Transformer 路线的重要原因。
代码实战
为了把论文里的结构思想落到可运行代码,我配套写了一份 Notebook,把 学习路径 和 工程路径 放在同一份文件里。前者从零手写 tiny TimeSformer,后者直接调用 Hugging Face 的 TimesformerForVideoClassification,两条路径共享同一个 toy video classification 任务,因此既适合面试式讲解,也适合工程侧快速验证。
完整代码实战:
![]()
这份 Notebook 最值得看的第一段代码,是手写的时序注意力模块。它把 shape 从 (B, T, N, D) 重排成 (B*N, T, D),让“同一个空间位置在不同帧上的 token”先彼此交互:
class TemporalSelfAttention(nn.Module):
def __init__(self, d_model, num_heads, dropout=0.1):
super().__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(d_model, d_model * 3)
self.proj = nn.Linear(d_model, d_model)
self.dropout = nn.Dropout(dropout)
def forward(self, x, num_frames, num_patches):
b, _, d = x.shape
cls_token = x[:, :1]
patches = x[:, 1:].reshape(b, num_frames, num_patches, d)
patches = patches.permute(0, 2, 1, 3).reshape(
b * num_patches,
num_frames,
d,
)
...第二段关键代码,是把 temporal attention、spatial attention 和 MLP 串成完整的 divided space-time block:
class DividedSTBlock(nn.Module):
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.temporal_attn = TemporalSelfAttention(d_model, num_heads, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.spatial_attn = SpatialSelfAttention(d_model, num_heads, dropout)
self.norm3 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
def forward(self, x, num_frames, num_patches):
x = x + self.temporal_attn(self.norm1(x), num_frames, num_patches)
x = x + self.spatial_attn(self.norm2(x), num_frames, num_patches)
x = x + self.mlp(self.norm3(x))
return x第三段代码展示工程路径。这里不直接加载大规模预训练权重,而是用 tiny config 构造一个更适合教学的小模型,让它和手写版在同一任务上对齐:
engineering_config = TimesformerConfig(
image_size=IMAGE_SIZE,
patch_size=PATCH_SIZE,
num_frames=NUM_FRAMES,
num_channels=3,
hidden_size=D_MODEL,
num_hidden_layers=NUM_LAYERS,
num_attention_heads=NUM_HEADS,
intermediate_size=D_FF,
hidden_dropout_prob=DROPOUT,
attention_probs_dropout_prob=DROPOUT,
num_labels=NUM_CLASSES,
)
engineering_model = TimesformerForVideoClassification(engineering_config)如果你是在准备面试,这份 Notebook 的价值在于可以把 TimeSformer 讲到 shape 级别;如果你是在做工程验证,它也提供了一条从论文结构过渡到现成库实现的路径:先在学习路径里彻底看懂,再在工程路径里快速复用。
参考文献
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding?. arXiv.
- Bertasius, G., Wang, H., & Torresani, L. (2021). Is Space-Time Attention All You Need for Video Understanding?. ICML 2021.
- Facebook Research. TimeSformer Official Repository.
- Dosovitskiy, A., et al. (2021). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale.