Temporal Segment Networks: Towards Good Practices for Deep Action Recognition
Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, Luc Van Gool — ECCV 2016 (ETH Zurich / CUHK / SIAT, CAS)
TSN 是视频理解发展史上一个很关键、但常被低估的转折点。它没有试图立刻用更重的时空模型去吞掉整段长视频,而是先把问题拆开:如何在可接受的计算成本下,让模型真正“看过”整段视频。在 2016 年这个时间点,这个问题比“局部时序建模得多精细”更迫切。
更重要的是,TSN 不只是提出了一个分段采样框架,还系统总结了一套在小规模视频数据集上非常有效的训练实践,包括 Cross-Modality Pre-training、Partial BN、Corner Cropping 和 Scale Jittering。很多后续视频基线真正继承的,不只是 Segmental Consensus 这个结构想法,也包括这套工程化训练范式。
研究动机
TSN 之前的视频分类主流方法,往往依赖双流网络:一条 2D CNN 处理 RGB 外观,另一条 2D CNN 处理光流运动。这个设计在当时已经很强,但有一个根本限制:每次看到的时间范围太短。
例如,空间流通常只看单帧,时间流往往只看一小段光流堆叠。这样的输入足以识别短时局部动作,却很难稳定覆盖整段长视频的时序变化。很多动作真正区分类别的关键,不在某一帧“长什么样”,而在于动作是如何在更长时间范围内展开的。
另一个直接但代价高昂的思路,是把视频密集切成很多 clip 再逐个处理。然而长视频帧数大、冗余高,如果对整段视频做密集推理,计算成本和存储开销都会迅速上升。TSN 的核心判断因此非常明确:与其密集处理所有帧,不如用稀疏采样换取全局时间覆盖。
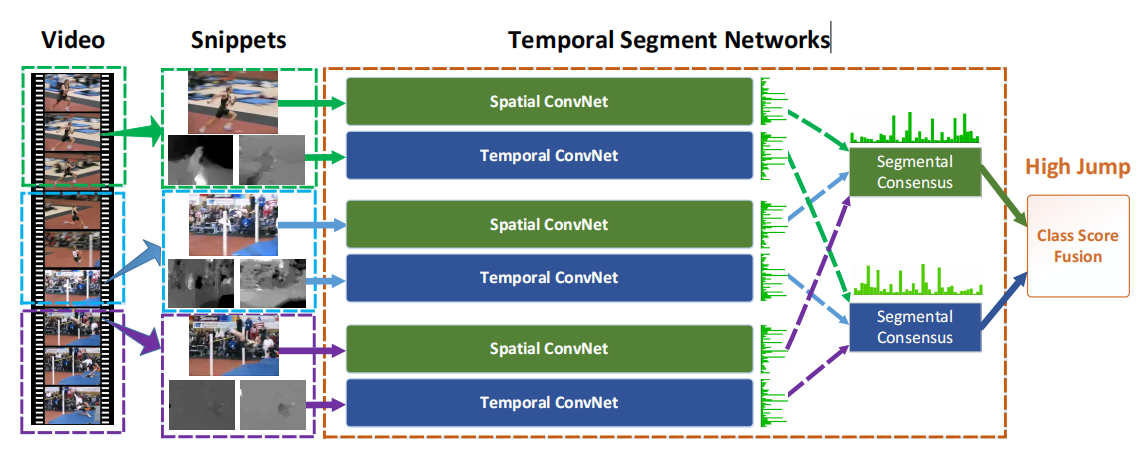
核心方法/模型架构
TSN 的整体结构可以概括为一句话:把一个长视频均匀分成 个时间段,每段采一个代表性 snippet,经过共享参数的网络分别提特征,再做视频级共识融合。
如果把每一段采样得到的输入记为 ,共享参数主干网络记为 ,共识函数记为 ,最终分类器记为 ,那么 TSN 的视频级预测可以写成:
这里最关键的不是公式形式本身,而是两个结构性决定:
- 段内采样、段间覆盖:模型不再只盯着局部短片段,而是显式覆盖从视频开头到结尾的多个时间位置。
- 共享参数:所有 segment 使用同一个 backbone,因此不同时间位置的特征被映射到同一语义空间,后续 consensus 才有意义。
在完整论文里,TSN 通常以双流方式使用:RGB 流和光流流各自独立做 segment sampling 与 consensus,最后再做一次 late fusion。也就是说,TSN 的核心不是“某个特定 backbone”,而是一种视频级时间建模框架。
组件详解
Segment-based Sampling:用稀疏采样换长时程覆盖
TSN 最本质的创新,是把“长视频建模”转化为“分段后做代表采样”。假设一个视频被均匀切成 段,训练时每段随机采一个 snippet,推理时通常取中心位置或固定策略采样。这样做有两个直接收益:
- 时间覆盖更完整:即使每段只取一个代表帧或一个短 snippet,整体上仍然覆盖了视频的多个阶段。
- 计算成本更可控:相比对全视频密集解码和推理,TSN 只处理少量关键位置。
从今天回看,这其实是一种很典型的“稀疏时间建模”思想。它不擅长捕捉非常细粒度的局部运动细节,但非常擅长在有限预算下获得视频级全局视野。
Segmental Consensus:从片段判断到视频判断
如果只对每个 segment 独立分类,那么模型仍然停留在“短片段识别”层面。TSN 真正把问题提升到视频级的关键,是 Segmental Consensus。
最常见的共识函数是平均:
这里的 可以理解为第 个 segment 的预测结果或特征表示。平均共识的优点在于稳定、简单,而且天然适合端到端反向传播。论文中也讨论过 max 或更复杂的时序模块,但平均往往已经足够强,尤其适合作为默认基线。
这个设计非常重要,因为它把目标从“识别单个时刻”改成了“让多个时间位置达成一致判断”。从建模视角看,TSN 实际上是在做一种轻量级的视频级证据聚合。
Cross-Modality Pre-training:让光流分支继承图像预训练
TSN 论文最有影响力的工程技巧之一,是把 ImageNet 上训练好的 RGB 模型参数迁移到光流分支。难点在于第一层卷积的输入通道数不同:RGB 模型通常是 3 通道,而光流堆叠常见是 20 通道。
论文的做法很巧妙:先把第一层 RGB 卷积核在通道维上求平均,得到单通道滤波器,再复制到所有光流通道。这样做并不意味着光流和 RGB 在语义上完全一样,而是给光流分支一个远好于随机初始化的起点。
这类初始化后来影响很大。很多视频模型在把已有视觉模型迁移到新模态时,都会沿用类似思路:先把可迁移的低层统计结构迁过去,再让后续训练去适配具体模态差异。
Partial BN 与数据增强:让小数据集微调更稳定
论文另一个非常实用的贡献,是系统解决“小视频数据集微调不稳定”的问题。
其中最经典的是 Partial BN:冻结除第一层以外的大多数 Batch Normalization 层,只允许最靠近输入的统计量继续适应新数据分布。这样做的直觉很直接:光流与 RGB 或新数据集与预训练数据之间的分布偏移,首先影响的是底层激活;如果所有 BN 统计量都在小数据集上被剧烈更新,模型反而容易漂掉。
除此之外,TSN 还强调了两类简单但有效的数据增强:
- Corner Cropping:强制裁剪位置覆盖四角和中心,减少只偏向中间区域的采样偏置。
- Scale Jittering:从多个尺度组合中随机裁剪,例如
[256, 224, 192, 168]这类候选边长,增强尺度鲁棒性。
这些技巧之所以重要,不是因为它们在概念上多新,而是因为它们把视频分类从“能不能训起来”推进到“能不能稳定复现”。
TSN 与 3D CNN 的边界:全局覆盖强,但局部运动建模有限
TSN 很强,但它解决的问题有明确边界。它更像是在回答:如何用低成本方式覆盖更长时间范围,而不是回答:如何在网络内部精细学习连续帧之间的局部运动结构。
这也是为什么后续研究会继续走向 C3D、I3D、SlowFast 以及 Video Transformer。与 TSN 相比,3D CNN 直接在卷积核内部建模时空邻域关系,更适合捕捉连续运动模式,但代价是计算和显存开销明显更高。

因此可以把 TSN 和 3D CNN 的关系理解为两种不同取舍:
- TSN:稀疏采样,强调长时间覆盖,成本低,适合作为强基线。
- 3D CNN:密集建模,强调局部时空关系,表达更强,但成本更高。
TSN 不是 3D CNN 的“低配替代”,而是视频理解里另一条非常有价值的路线。
实验结果
论文在 UCF101 等数据集上的实验表明,TSN 的提升并不只来自分段采样本身,而是“框架设计 + 训练技巧”共同作用的结果。下面这组消融结果很能说明问题:
| 训练策略 | Spatial ConvNets | Temporal ConvNets | Two-Stream |
|---|---|---|---|
| Baseline | 72.7% | 81.0% | 87.0% |
| From Scratch | 48.7% | 81.7% | 82.9% |
| Pre-train Spatial | 84.1% | 81.7% | 90.0% |
| + Cross modality pre-training | 84.1% | 86.6% | 91.5% |
| + Partial BN with dropout | 84.5% | 87.2% | 92.0% |
从这张表里可以读出三个结论:
- 预训练非常关键:尤其是空间流,从头训练会明显退化。
- 光流分支同样受益于更好的初始化:Cross-Modality Pre-training 直接带来稳定提升。
- 小数据集视频分类高度依赖训练细节:Partial BN 和 dropout 这类技巧不是锦上添花,而是基线性能的重要组成部分。
如果只从论文历史地位看,TSN 的价值并不只是刷高了某个 benchmark,而是把“长视频分类 baseline 应该怎么搭”这件事讲清楚了。
总结
TSN 的核心贡献可以压缩为三句话:
- 它用 segment-based sampling 把长视频建模变成了一个可计算、可训练的问题。
- 它用 Segmental Consensus 把局部片段预测提升为视频级判断。
- 它连同 Cross-Modality Pre-training、Partial BN 和数据增强技巧,一起定义了早期视频分类的强基线范式。
即使后来 3D CNN 和 Video Transformer 成为主流,TSN 依然值得认真读,因为它代表的是一种非常经典的研究思路:先把问题拆对,再谈把模型做大。
代码实战
为了把论文里的结构思想落到可运行代码,我配套实现了一份教学型 Notebook。它不是原论文 benchmark 的工业级复现,而是聚焦三个最重要的问题:如何做分段采样、如何做 consensus、如何把 TSN 组装成学习路径与工程路径两套实现。
完整代码实战:
![]()
第一段关键代码,是 TSN 最核心的时间采样逻辑。训练时每段随机采样,推理时每段中心采样,这正是 TSN 在“泛化能力”和“预测稳定性”之间的基本平衡:
def sample_segment_indices(num_frames, k_segments, training=True):
boundaries = np.linspace(0, num_frames, k_segments + 1)
indices = []
for seg_id in range(k_segments):
start = int(boundaries[seg_id])
end = int(boundaries[seg_id + 1])
end = max(end, start + 1)
if training:
idx = random.randint(start, end - 1)
else:
idx = (start + end - 1) // 2
idx = min(idx, num_frames - 1)
indices.append(idx)
return indices第二段关键代码,是把多个 segment 的特征聚合成视频级表示的 consensus。它很短,但正是这一步把“多帧输入”变成了“视频判断”:
def segmental_consensus(feats, mode='avg'):
if mode == 'avg':
return feats.mean(dim=1)
if mode == 'max':
return feats.max(dim=1).values
raise ValueError(f'Unsupported consensus mode: {mode}')第三段关键代码,对应论文里最有代表性的工程技巧之一:Cross-Modality Pre-training。它演示了如何把 RGB 第一层卷积权重变形后迁移到光流分支:
def cross_modality_init(pretrained_conv, flow_channels=20):
old_weight = pretrained_conv.weight.detach().cpu()
mean_weight = old_weight.mean(dim=1, keepdim=True)
new_weight = mean_weight.repeat(1, flow_channels, 1, 1)
new_conv = nn.Conv2d(
in_channels=flow_channels,
out_channels=old_weight.shape[0],
kernel_size=pretrained_conv.kernel_size,
stride=pretrained_conv.stride,
padding=pretrained_conv.padding,
bias=(pretrained_conv.bias is not None),
)
new_conv.weight.data.copy_(new_weight)
if pretrained_conv.bias is not None:
new_conv.bias.data.copy_(pretrained_conv.bias.detach().cpu())
return new_conv这份 Notebook 的价值,不只是“能跑通一个 TSN toy baseline”,而是它把论文里最容易讲抽象的三件事拆得非常清楚:时间采样策略、视频级共识、以及从论文技巧到工程实现的映射关系。如果你是在准备面试、课程作业或论文复现,这样的代码比直接背结论更有帮助。
参考文献
- Limin Wang, Yuanjun Xiong, Zhe Wang, Yu Qiao, Dahua Lin, Xiaoou Tang, Luc Van Gool. Temporal Segment Networks: Towards Good Practices for Deep Action Recognition. ECCV 2016. arXiv.
- ECCV 2016 chapter page. Springer / DOI.
- 配套代码实战 Notebook. TSN Code Notebook.