Two-Stream Convolutional Networks for Action Recognition in Videos
Karen Simonyan, Andrew Zisserman — NeurIPS 2014 (University of Oxford)
Two-Stream ConvNet 是视频动作识别发展史上的里程碑工作。它最重要的贡献,不是简单把 CNN 用到视频上,而是明确提出:动作识别需要同时理解静态外观与动态运动。论文将这两类信息拆分成两条独立分支处理,让当时已经成熟的 2D CNN 能够自然迁移到视频任务。
在 2014 年这个时间点,3D 卷积、Video Transformer、端到端时空建模都还没有成为主流。Two-Stream 提供了一条极其实用的中间路径:一条空间流看单帧 RGB,另一条时间流看光流堆叠,最后在分数层做融合。这种设计简单、有效、可解释,也为后续 TSN、I3D、SlowFast 等方法奠定了问题拆解方式。
研究动机
视频动作识别和图像分类的根本区别在于:图像只需要回答“这是什么”,而视频还要回答“它是怎么动的”。
传统 CNN 在静态图像分类上已经表现优异,但如果直接逐帧处理视频,模型主要只能利用场景、物体和姿态这些空间线索。对于很多动作类别,这远远不够。例如游泳、跳水、挥拍、投掷等动作,单帧外观往往高度相似,真正区分类别的是时间维度上的运动模式。
论文因此提出一个非常直接的分工方案:
- 空间流(Spatial Stream) 负责建模当前画面里有什么
- 时间流(Temporal Stream) 负责建模目标如何移动
- 后期融合(Late Fusion) 负责综合两条流的证据得到最终分类
这个拆分背后的关键判断是:外观与运动虽然相关,但统计特性并不相同,最好分别建模,再在决策层汇合。在当时数据规模和算力条件都有限的背景下,这种方案比直接训练复杂的视频模型更现实。
核心方法/模型架构
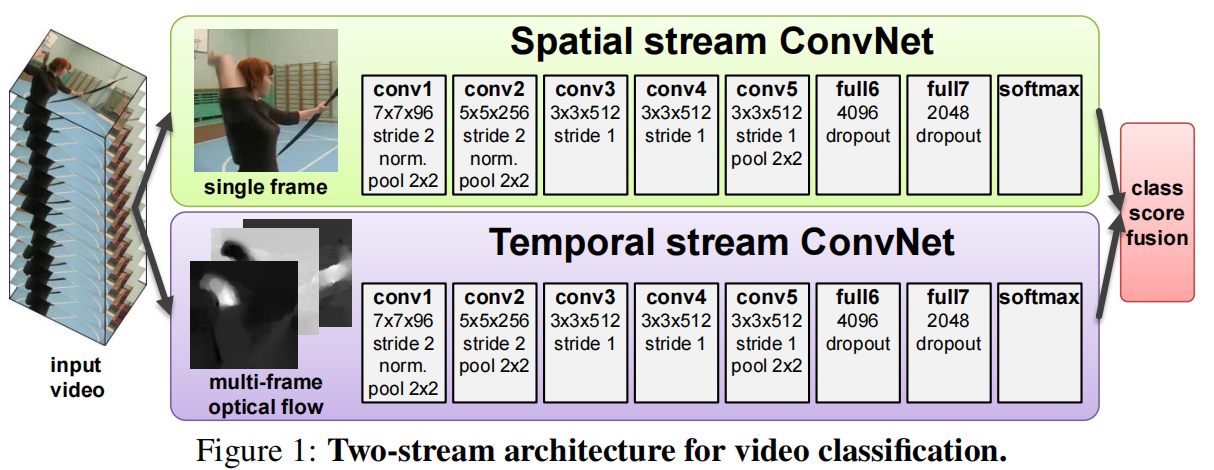
Two-Stream 的整体结构非常清晰:空间流输入单帧 RGB 图像,时间流输入连续多帧计算得到的密集光流堆叠,两个分支各自输出分类分数,再将分数进行加权融合。
形式上,可以把最终预测写成:
其中 表示空间流输出的分类分数, 表示时间流输出的分类分数, 是融合权重。论文的核心思想并不在于复杂的联合优化,而在于先把两类互补信息各自学好,再做稳定的分数级融合。
这种设计有三个直接优势:
- 充分复用图像模型:空间流可以直接使用 ImageNet 预训练 CNN。
- 显式引入运动信息:时间流通过光流把“怎么动”编码为可学习输入。
- 工程实现简单:两条流可以独立训练,最终只需在分数层融合。
组件详解
空间流:建模外观与场景
空间流的输入是视频中抽取的单帧 RGB 图像。它负责识别物体、场景、人体姿态等静态视觉线索,本质上与图像分类网络非常接近。
这一分支的优势在于可以直接继承大规模图像分类预训练带来的表示能力。例如篮球场、泳池、乐器、人体姿态等信息,都能为动作判断提供强先验。但它的局限也很明显:如果两个动作的关键差异主要体现在运动轨迹而不是单帧外观上,空间流往往难以单独做出可靠判断。
时间流:建模运动模式
时间流的输入不是 RGB 图像,而是连续帧之间的密集光流。光流可以理解为一张“运动场”,每个像素都带有从前一帧到后一帧的位移信息,因此更直接地反映运动方向和速度。
论文不是只输入一张光流图,而是把连续多个时间步的光流场堆叠起来,形成多通道输入。若每个时间步包含水平和垂直两个光流分量,那么堆叠 帧后,输入通道数就是 。
这使得时间流能够从短时间窗口内观察连续运动模式,而不是只看某个瞬时速度。对于挥手、跑步、投掷、击球等动作,这类时序信息往往比单帧外观更关键。
光流堆叠:如何把运动编码成 CNN 可处理的输入
论文讨论了两种堆叠方式:固定位置堆叠与沿轨迹堆叠。
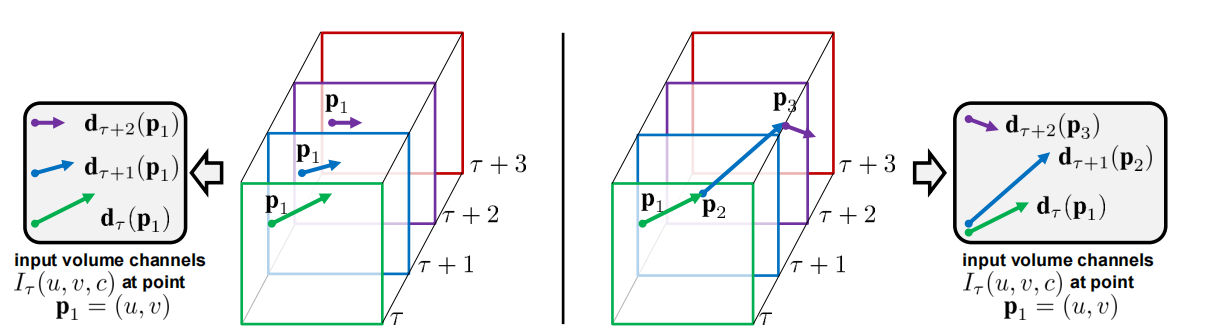
固定位置堆叠(Naive Stacking) 在相同像素位置上,连续读取多个时间步的光流向量并按通道拼接。这种方式实现简单,但如果目标快速移开该位置,后续通道可能更多记录到背景信息。
沿轨迹堆叠(Trajectory Stacking) 则尝试跟随像素的运动轨迹,在下一帧的新位置继续读取光流。这样堆叠出的输入更贴近真实物体运动轨迹,因此在捕捉持续动作时更合理。
这部分内容非常重要,因为它说明 Two-Stream 并不是“随便把光流喂给 CNN”,而是认真考虑了运动信号在时间上的组织方式。
分数融合:为什么采用 Late Fusion
论文采用的是非常经典的后期融合策略:两条流各自完成分类,然后对分数做加权平均。
这样做有几个现实原因:
- 训练稳定:两条流可以分别学习各自最擅长的信息。
- 模块化强:空间流和时间流可以单独替换、调参、评估。
- 实现代价低:不需要复杂的跨模态对齐或中间特征交互。
当然,Late Fusion 的限制也很明显:两条流直到最后才交互,无法在更早层次学习细粒度时空耦合关系。这也是后续研究不断尝试早融合、3D 卷积或显式时空建模的原因。
训练技巧:让时间流真正可用
论文中还有几项非常关键的工程技巧。
首先是数据增强。作者强调,全图随机裁剪比只从中心裁剪更有效,因为它显著提高了训练样本的多样性。其次是测试时多视图平均:从时间维和空间维进行密集采样,再对多个预测结果取平均,以降低单次采样带来的偶然性。
另一个常被忽视但非常重要的点是光流压缩。原始光流为浮点数,存储开销巨大。论文把光流先线性缩放到 的整数范围,再用 JPEG 进行压缩,大幅降低了数据存储与读取成本。这说明 Two-Stream 不只是一个“模型想法”,而是一整套可落地的视频训练方案。
实验结果
论文在 UCF-101 和 HMDB-51 这两个经典视频动作识别数据集上进行了实验,并取得了当时非常强的结果。核心结论不是某一个百分点本身,而是以下三点:
- 时间流单独就很强,说明光流中确实包含高价值的动作信息。
- 空间流与时间流具有明显互补性,融合后性能进一步提升。
- 预训练与数据增强非常关键,尤其对空间流效果影响显著。
从今天回看,这篇论文最值得记住的并不是具体数值,而是它证明了一个强事实:只要把运动信息显式建模出来,2D CNN 体系也可以在视频理解任务上取得强竞争力。
总结
Two-Stream ConvNet 的历史意义在于,它首次把视频动作识别清晰拆解为两个互补问题:看见什么,以及如何运动。空间流负责吸收成熟的图像表示能力,时间流负责显式建模运动模式,后期融合则把两类证据稳定地结合起来。
从方法论上看,Two-Stream 是一种非常典型的“先问题分解,再模块组合”的研究范式。它的后续局限同样清晰:光流预计算成本高,时空交互发生得太晚,难以实现真正端到端的统一建模。但也正因为它把问题拆得足够清楚,后来的 TSN、I3D、SlowFast、Video Transformer 才能在更强建模框架中继续推进。
代码实战
为了把论文思想落到可运行代码,我配套实现了一份教学型 Notebook。它没有直接复现 UCF-101 全流程,而是用一个轻量 toy video dataset 去演示 Two-Stream 的核心机制:空间流看外观,时间流看运动,最后做 late fusion。
完整代码实战:
![]()
Notebook 里最值得关注的有三部分。
第一部分是时间流输入的轻量近似。原论文使用 dense optical flow,这在教学环境里实现和运行成本都较高,因此 Notebook 使用帧差分来近似时间流输入:
def compute_frame_diffs(video_tensor):
if video_tensor.dim() == 3:
return video_tensor[1:] - video_tensor[:-1]
if video_tensor.dim() == 4:
return video_tensor[:, 1:] - video_tensor[:, :-1]
raise ValueError(f'Unsupported tensor shape: {tuple(video_tensor.shape)}')这段代码并不等价于真实光流,但足以把“运动变化堆叠成多通道输入”的思想讲清楚。
第二部分是从零手写的双流模型。Notebook 分别实现了 SpatialStreamCNN、TemporalStreamCNN 和最终的 TwoStreamLearningModel,把论文的数据流拆成最直观的形式:
class TwoStreamLearningModel(nn.Module):
def __init__(self, num_classes, temporal_channels, alpha=0.5):
super().__init__()
self.spatial = SpatialStreamCNN(num_classes)
self.temporal = TemporalStreamCNN(temporal_channels, num_classes)
self.alpha = alpha
def forward(self, spatial_input, temporal_input, return_parts=False):
spatial_logits = self.spatial(spatial_input)
temporal_logits = self.temporal(temporal_input)
fused_logits = self.alpha * spatial_logits + (1.0 - self.alpha) * temporal_logits
if return_parts:
return fused_logits, spatial_logits, temporal_logits
return fused_logits这里最核心的一步就是分数级融合:
第三部分是工程路径版本。Notebook 进一步用 torchvision.models.resnet18 组装了一个更接近真实工程基线的双流模型,用来对比“手写教学实现”和“成熟 backbone 迁移实现”的差异。这样做的价值在于:不仅能理解论文原理,还能把这种结构迁移到现代深度学习工具链中。
参考文献
- Simonyan, K., & Zisserman, A. (2014). Two-Stream Convolutional Networks for Action Recognition in Videos. NeurIPS 2014.
- University of Oxford VGG. Project Page: Two-Stream Convolutional Networks for Action Recognition in Videos.
- Feichtenhofer, C., Pinz, A., & Zisserman, A. (2016). Convolutional Two-Stream Network Fusion for Video Action Recognition. CVPR 2016.