
Movie Gen / Hunyuan Video
Video generation data engine notes
很多人谈视频生成,第一反应都是参数规模、Transformer 结构或者 Flow Matching。但如果把系统拆开看,决定上限的往往不只是在模型本身,而是前面那套 数据引擎:你喂给模型的是什么视频、这些视频怎么被切片、分布怎么被重组、字幕是否足够细、镜头语言是否被显式标注。
图像生成也需要数据清洗,但视频多了运动、镜头、时间连续性和长尾概念覆盖这些维度。所以很多最终表现为“运动更自然”“文本对齐更强”“镜头控制更稳”的能力,本质上都和数据构造直接相关。
Key takeaway
视频生成里的数据工程主要在做三件事:过滤低质量模式、重组训练分布、构造更强的条件信号。过滤决定噪声下限,重采样决定模型会偏向哪些概念,字幕与镜头标签决定模型最终能接收什么控制信息。
为什么视频生成更依赖数据引擎
对于图像模型来说,一张图是否适合训练,核心常常是清晰度、构图、语义标签这些问题。但到了视频,问题会立刻扩成一个多维约束系统:
| 问题类型 | 为什么会破坏训练 | 常见处理手段 |
|---|---|---|
| 画质问题 | 低分辨率、边框、水印会污染视觉表示 | 分辨率阈值、OCR、视觉质量模型 |
| 运动问题 | 静态片段、异常抖动、伪运动会扭曲动态分布 | motion score、镜头边界检测、静态视频过滤 |
| 时序切分问题 | 长视频直接训练会让样本边界不清晰 | shot split、片段裁切、关键帧提取 |
| 语义分布问题 | 热门概念过多会压制长尾内容 | 去重、聚类、重采样、概念均衡 |
| 条件信号问题 | 字幕太短或太粗糙,模型学不到细粒度控制 | 详细 caption、结构化字段、镜头标签 |
这也是视频生成数据管线和传统“清洗脏数据”之间最大的差别:它不仅在剔除坏样本,也在主动塑造训练分布和监督接口。
一个总览:原始视频如何变成训练样本

从系统视角看,视频生成的数据引擎大致会经历五层变换:
- 从互联网或内部来源收集原始视频。
- 通过画质和运动过滤,把明显不适合训练的样本剔掉。
- 通过去重、聚类和重采样,重组概念分布。
- 用字幕、结构化字段和镜头标签,把视频变成条件可读的训练样本。
- 将这些样本送入预训练或 SFT 流程,最终影响模型的可控性与覆盖范围。
这套链路的重点不是“让数据更干净”这么简单,而是让数据从原始内容变成一种 可学习、可控制、可组合 的监督资源。
Movie Gen:先过滤,再构造条件
Movie Gen 的数据流程很适合作为一个典型例子,因为它很清楚地区分了两件事:
- 过滤链路:哪些视频不该进训练集。
- 条件构造:哪些信息要显式写给模型。
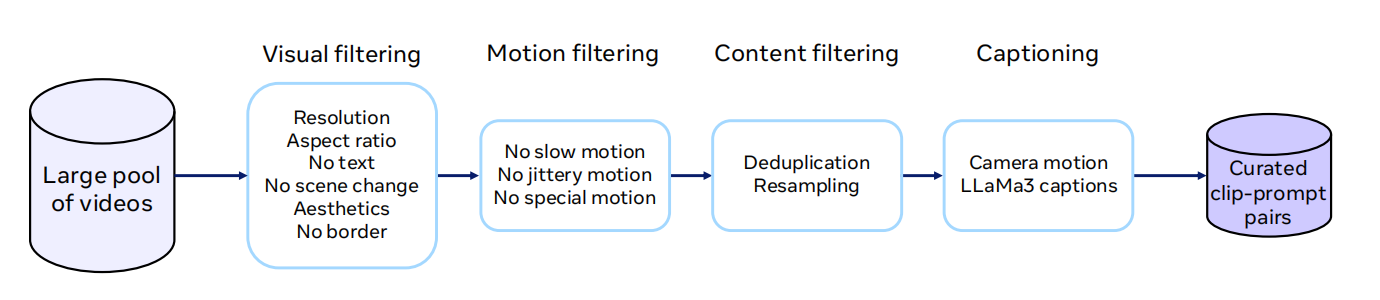
视觉过滤:先保证“看起来像正常视频”
笔记中提到的视觉过滤包括分辨率阈值、宽高比控制、OCR 过滤,以及基于美学、画质、大边框和视觉特效的质量模型筛选。它们解决的是最基础的一层问题:如果样本本身就充满低清、字幕遮挡、奇怪边框和过重特效,那么模型学到的视觉表示会从一开始就带偏。
这一步听起来朴素,但它的作用很直接:把模型最不该浪费容量学习的模式先剔掉。
运动过滤:视频不是“会动的图片”
视频数据最大的特殊性,在于运动本身就是训练目标的一部分。笔记里的运动过滤包括:
- 用静态视频检测模型去掉几乎没有运动的片段。
- 结合 VMAF 运动分数和运动向量筛选合理运动的视频。
- 用 PySceneDetect 的镜头边界检测,去除频繁抖动的视频。
- 去除幻灯片式切换等特殊运动效果明显的视频。
如果没有这层过滤,模型会学到大量不自然的动态模式:硬切、乱抖、无意义平移、伪运动。于是最终生成出来的视频,哪怕单帧清晰,也可能在时间维上显得非常假。
内容过滤:去重解决冗余,重采样解决偏置
数据量大不等于分布合理。视频训练集里常见的问题不是“样本太少”,而是重复太多、头部概念太强、长尾概念太弱。
Movie Gen 在这一步做了两件核心工作。
第一是去重。笔记提到会使用 copy-detection embedding 去计算片段相似度,把感知上重复的内容去掉。这样做的目的不是节省硬盘,而是避免训练阶段反复看到近似样本,导致模型容量被冗余数据吞掉。
第二是概念均衡。大致思路是先用视频—文本联合嵌入得到语义表示,再识别细粒度概念簇、合并相近簇,最后按簇大小的平方根倒数进行采样。结果就是:
- 大簇少采样。
- 小簇多采样。
这种策略追求的不是绝对均匀,而是防止热门概念主导训练过程。换句话说,重采样不是为了让数据看起来更平均,而是为了让模型把容量分配到更广的语义空间。
字幕生成:把视频转成模型能读的条件
过滤之后,系统还要解决一个更关键的问题:视频内容如何被写成足够有用的监督信号。
笔记中提到,Movie Gen 使用 LLaMA3-Video 的 8B 和 70B 版本为视频片段生成详细描述,训练集字幕大约 70% 来自 8B,30% 来自 70B。这里最值得关注的不是具体配比,而是策略本身:系统在主动把原始视频转写成更密集、更可学习的文本条件。
这说明视频字幕在生成任务里并不只是配套元数据,而更像是一层监督接口。字幕越细,模型在训练时接收到的条件密度就越高,后续推理时的文本控制也越有机会更精确。
Camera movement:让模型不只知道“是什么”,还知道“怎么拍”
Movie Gen 还训练了专门的摄像机运动分类器,用来预测镜头运动类别。高置信度预测结果会被前缀到文字描述中,帮助模型在训练阶段学习镜头语言,也让推理阶段更容易响应 camera control 一类需求。
这一点很关键,因为自然语言字幕往往擅长描述对象、动作和环境,却不一定足够稳定地表达镜头语言。显式加入镜头标签,相当于把“画面内容”和“镜头行为”拆成了两个条件维度。
预训练数据与 SFT 数据为什么不能混为一谈
同样叫“训练数据”,预训练和监督微调(SFT)其实解决的是不同问题。
预训练更关心覆盖和规模
笔记里提到,Movie Gen 会先做文生图预热训练,再进行文生图 + 文生视频联合训练。这里的逻辑很清楚:预训练阶段首先追求的是稳定的基础视觉表示,以及足够广的样本覆盖。
因此这一阶段的数据重点通常是:
- 规模足够大。
- 覆盖足够广。
- 基础过滤到位。
- 能为后续视频学习提供足够多样的视觉先验。
SFT 更关心监督质量和控制精度
到了 SFT 阶段,目标就不再只是“学会世界长什么样”,而是“学会在高质量条件下按要求生成”。所以数据要求明显更苛刻:
- 自动过滤美学、运动和场景切换质量。
- 去除主体过小的视频。
- 用 text/video k-NN 做概念均衡。
- 人工筛选片段,保证光线、色彩和运动质量。
- 人工修正自动字幕,补充镜头控制、表情、光线等细节。
这意味着 SFT 数据未必最大,但往往更贵、更稀缺,也更接近模型最终“可控生成能力”的来源。
为什么 model averaging 值得一提
笔记中还提到一个很工程化的手段:用不同数据、不同超参数和不同预训练 checkpoint 分别训练多个 SFT 模型,再直接做权重平均。
这不是本文主线,但它很能说明一个现实:当数据分布和训练配方都在变化时,模型本身也会学到不同偏好。权重平均相当于在后处理阶段再做一次能力融合,把运动、一致性、镜头控制等不同优势合并到一起。
Hunyuan Video:结构化字幕更像一种监督接口
如果说 Movie Gen 让我们看到“先过滤,再生成 caption”的路径,那么 Hunyuan Video 更进一步强调了 结构化监督 的价值。
先把长视频切成可学习的样本
Hunyuan Video 的数据预处理大致包括三步:
- 使用 PySceneDetect 把长视频切成单镜头片段。
- 使用 OpenCV 的拉普拉斯算子提取清晰关键帧。
- 用内部 VideoCLIP 模型计算 embedding,用于相似片段去除和概念聚类。
这里 embedding 的用途有两个:
- 基于 cosine 距离做相似片段去重。
- 用 k-means 聚出概念中心,为后续概念均衡服务。
这套流程的核心思想和 Movie Gen 一致:训练样本不是“找到一段视频就算一个样本”,而是先经过切分、筛选和重新组织之后,才真正成为可学习对象。
根据你指出的截图内容,这类“分层过滤 pipeline”本身就更适合直接转成表格,而不是继续保留为截图。把它写成可复制表格之后,信息密度和可读性都会更好:
| 过滤维度 | 工具 / 方法 | 目的 |
|---|---|---|
| 美学与技术质量 | Dover | 评估视觉美感 |
| 清晰度 | 自训练模型 | 去除模糊视频 |
| 运动速度 | 光流统计(OpenCV) | 过滤静态 / 慢动作视频 |
| 场景边界 | PySceneDetect + TransNet v2 | 获取场景切换信息 |
| 文字 / 字幕 | 内部 OCR 模型 | 去除文字过多片段、裁剪字幕 |
| 水印 / 边框 / Logo | YOLOX-like 模型 | 去除遮挡或敏感信息 |
如果再和 Movie Gen 放在一起看,两者的数据处理思路其实很接近,但强调点并不完全相同:
| 维度 | Movie Gen | Hunyuan Video |
|---|---|---|
| 起点问题 | 先过滤,再生成 caption | 先切片、清洗,再强化结构化监督 |
| 质量过滤 | 强调视觉质量、美学、OCR、运动质量 | 强调分层过滤、场景边界、OCR、水印等显式清洗 |
| 去重 / 均衡 | copy-detection embedding + 概念重采样 | embedding 去重 + k-means 概念聚类 |
| 条件构造 | 详细自然语言字幕 + camera control | JSON 风格结构化字幕 + 多维标签 |
| 控制能力来源 | caption 前缀中写入镜头运动 | 结构化字段和元数据共同组成监督接口 |
| 整体侧重点 | 把原始视频转成高质量 captioned samples | 把原始视频转成更稳定、更结构化的 supervision |
结构化字幕:把一句话拆成多维控制信号
传统 caption 的问题,不只是短,而是粒度不稳定:有时只写主体,有时只写动作,有时会补环境和风格,有时则完全不写镜头信息。
Hunyuan Video 的方向是用自研 VLM 生成 JSON 风格的结构化字幕,把原来混在一句话里的信息拆成更稳定的字段。与其继续把这类 schema 放在图里,更适合直接抽成正文表格:
| 字段类型 | 作用 |
|---|---|
| 主体 / 对象 | 明确画面里“是什么” |
| 动作 / 行为 | 明确主体“在做什么” |
| 环境 / 场景 | 补足地点、背景、空间关系 |
| 风格 / 氛围 | 提供视觉风格与情绪线索 |
| 镜头运动 | 显式编码推镜、平移、跟随等 camera language |
| 来源 / 质量标签 | 补充样本上下文与可靠性信息 |
这样做的价值可以压缩成三点:
- 让条件输入的粒度更稳定。
- 让模型更容易学习不同控制维度。
- 为后续的人机交互控制保留更清晰的接口。
笔记中还提到,系统会附加来源标签、质量标签等元数据,并通过字段 dropout 和排列组合来缓解过拟合。它的目标不是把格式搞复杂,而是让监督信号同时具备信息密度、结构稳定性和组合能力。
控制能力为什么依赖“信号叠层”

从训练视角看,视频生成模型并不只是读取一句 caption,而是在接收多层条件信号:自然语言字幕、结构化字段、镜头运动标签,以及各种质量或来源元数据。它们叠在一起,形成了一个更强的监督接口。
这个视角很重要,因为它解释了为什么结构化字幕和 camera movement 标注会显著影响模型可控性:
- caption 负责提供高层语义。
- 结构化字段负责把语义拆成更稳定的维度。
- 镜头标签负责显式编码镜头语言。
- 元数据标签负责补充样本上下文与可靠性信息。
一句话概括就是:caption 让模型知道“画面是什么”,而结构化字段和镜头标签进一步告诉模型“该如何生成”和“该如何拍”。
一个统一视角:数据引擎到底在优化什么
把 Movie Gen 和 Hunyuan Video 放在一起看,可以把视频生成数据引擎的目标浓缩成四件事:
- 过滤低质量模式:避免模型浪费容量去学低清、水印、伪运动和异常抖动。
- 重组训练分布:通过去重、聚类和重采样,把容量从头部概念重新分配到更广的语义空间。
- 提高条件信号密度:把原始视频转成更详细、更稳定的字幕和字段。
- 显式编码镜头语言:让模型不只学会“生成什么”,还学会“如何拍”。
这也是为什么视频生成里的数据工程不能被看成模型前面的附属环节。它并不是简单的预处理,而是在定义模型最终会学到哪些视觉规律、运动规律和控制接口。
总结
如果把模型结构看成“计算骨架”,那数据引擎更像是在决定骨架里到底会长出什么能力。
从这份笔记可以看到,一个成熟的视频生成数据系统至少要同时处理质量、运动、分布和条件这四个问题。Movie Gen 和 Hunyuan Video 在具体实现上并不完全相同,但方向是一致的:先把原始视频切成可学习样本,再把样本转成可控制的监督信号。
所以,很多最终表现为“更稳定的运动”“更强的文本对齐”“更好的镜头控制”的能力,往往不是单个模型技巧突然带来的,而是数据引擎长期塑造出来的结果。