
Movie Gen / Hunyuan Video
Video generation model architecture notes
理解视频生成模型,最容易犯的错误,是只盯着扩散、Transformer、DiT、Flow Matching、3D VAE 这些局部名词。真正决定系统能不能跑起来的,是它们怎么被组织成一条完整链路:视频怎样被压缩、压缩后的表示怎样 token 化、条件信息怎样注入、模型最终又怎样从噪声走回目标样本。
Movie Gen 和 Hunyuan Video 的具体实现不同,但主线其实很接近:先把像素视频压到更小的 latent 空间,再把 latent 变成 token 交给 Transformer 建模,最后通过去噪或 Flow Matching 完成生成。
Key takeaway
视频生成模型的核心不是“把图像模型直接搬到视频上”,而是先通过 VAE / TAE 压缩时空表示,再用 patchify + Transformer 建模,最后借助 时间条件、文本条件和 Flow Matching 把噪声逐步推向真实视频分布。
一个总览:视频生成模型到底在做哪几步

如果把整套系统抽象一下,大致可以分成四步:
- 把原始像素视频压缩成更小的 latent 表示。
- 把 latent 切成 patch,再展平成 token 序列。
- 用位置编码、文本条件和时间步条件,让 Transformer 在 token 空间中统一建模。
- 让模型学会从噪声或中间状态,逐步走向目标视频样本。
这个顺序看似简单,但几乎每一步都在解决“视频为什么比图像难得多”这个核心问题。
为什么视频不能直接在像素空间建模
图像任务里,一个 ViT 处理 224 × 224 图片已经不算小;视频不仅分辨率更高,还多了时间维度,一段几十到几百帧的视频会让 token 数量迅速爆炸。直接在像素空间上用 Transformer 建模,计算量通常难以接受。
因此视频生成模型几乎都会先做一层压缩:
- 先把像素视频编码成更小的 latent。
- 在 latent 空间而不是像素空间里完成主要生成过程。
- 最后再把 latent 解码回视频。
这不是一个局部优化,而是系统能够成立的前提。如果不先压缩,后面的 Transformer 根本没有现实的计算预算。
Movie Gen 的整体生成链路
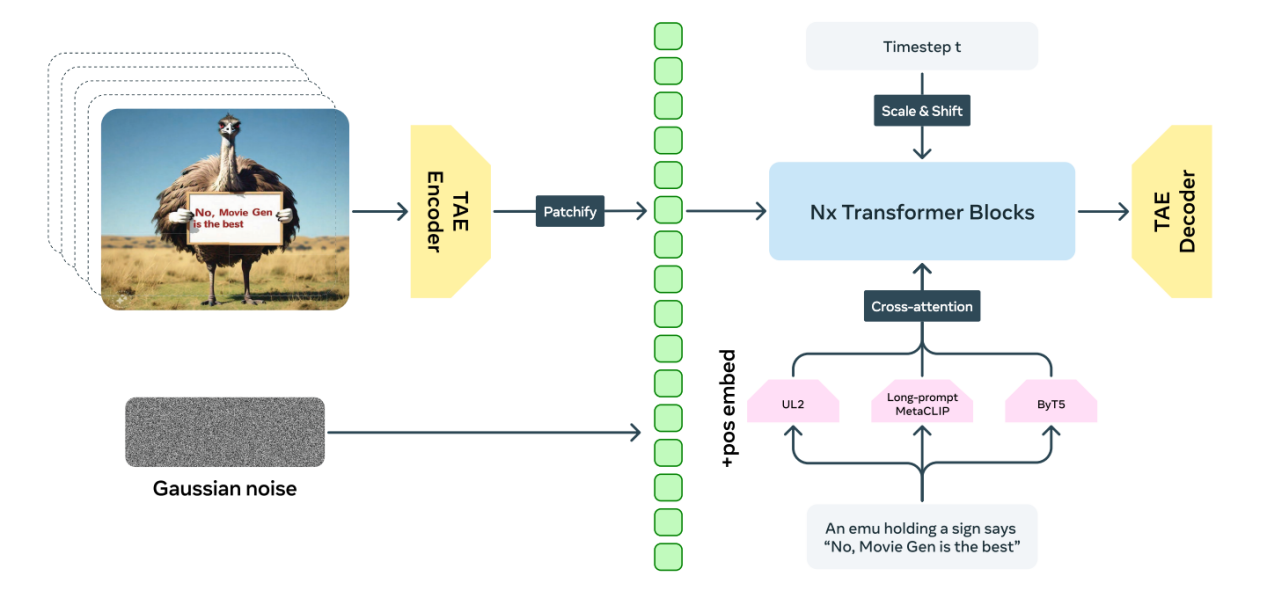
从笔记来看,Movie Gen 的整体流程可以概括为:
- 输入视频帧先经过 TAE Encoder,压缩成更小的 latent。
- latent 经过 patchify,变成视觉 token。
- token 加上位置编码后送入 Transformer。
- 文本提示经过文本编码器处理,再通过 cross-attention 注入主干网络。
- 模型在不同时间步上逐步去噪或预测流动方向。
- 最终 latent 经过 TAE Decoder,恢复成视频或图像。
这个链路最值得记住的,不是每个模块名字,而是它背后的工程逻辑:先把最重的时空信息压缩,再在压缩空间里做统一生成建模。
如果把 Movie Gen 和 Hunyuan Video 并排看,二者在“大方向”上是一致的,但在具体实现上各有取舍:
| 模块 | Movie Gen | Hunyuan Video |
|---|---|---|
| 压缩表示 | TAE,强调在图像 AE 基础上扩到视频 | 3D VAE,显式在时空维度做压缩 |
| 时间建模 | 2+1D 思路,空间模块上补时间卷积 / 注意力 | CausalConv3D,更强调时间方向约束 |
| token 化 | latent 经 3D 卷积 patchify,再送入 Transformer | 同样先压缩后建模,但笔记里更突出 3D VAE 的时空压缩收益 |
| 条件注入 | 文本 cross-attention + 时间步条件 + 位置编码 | 同样依赖条件注入,但文章笔记更突出系统化视频生成框架 |
| 训练目标 | Flow Matching 路线更突出 | 系统框架视角更强,强调大规模视频生成整体设计 |
这样看会更清楚:两者真正共享的不是某一个单点模块,而是“先压缩,再 token 化,再条件驱动生成”这条主线。
TAE:先把视频压到时空 latent 空间
TAE 的任务,是把原始视频压缩到一个更小的时空 latent 空间中,让后续模型不必直接处理像素级视频。
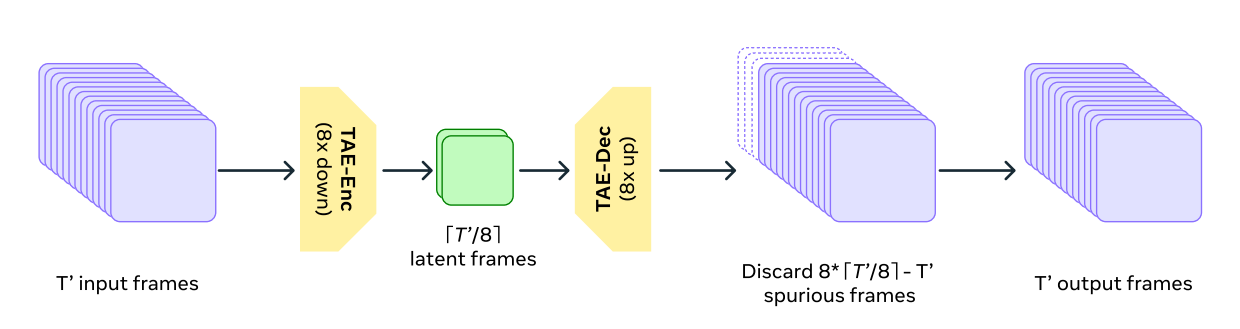
即使不看图,这里真正需要记住的也只有三点:
| 关键点 | 含义 |
|---|---|
| 编码器(Encoder) | 把原始视频压缩到更小的 latent |
| 解码器(Decoder) | 把 latent 还原回视频 |
| 核心目标 | 减少 token 数量,同时尽量保留空间结构与时间信息 |
这也是它和普通图像 AE 最本质的区别:它不是只做空间压缩,而是要把时间维也一起纳入可计算的表示里。
怎么从图像 autoencoder 扩展到视频 autoencoder
已有的图像 VAE 很成熟,但它只处理空间,不处理时间。笔记里的扩展方式接近 2+1D:先处理单帧内部的空间结构,再处理跨帧时间关系;具体做法是在每个 2D spatial convolution 后增加 1D temporal convolution,在每个 spatial attention 后增加 1D temporal attention。
它的价值在于:不用从零发明全新视频编码器,而是在成熟图像 AE 的基础上,以较小代价补上时间建模能力。
为什么它能支持任意长度视频
笔记中提到,时间维的下采样采用 stride convolution,而不是要求输入长度严格匹配固定 patch 大小。因此即使视频长度不完全对齐,也可以在上采样后裁掉多余边缘帧。
这带来两个很实际的工程好处:
- 同一套编码器可以兼容视频和单帧图像。
- 输入格式不会被固定帧长死死绑住。
Hunyuan Video 的 3D VAE 与 CausalConv3D
如果说 Movie Gen 更强调 TAE 的工程折中,那么 Hunyuan Video 展示的是另一条更显式的 3D VAE 路线。
从表示角度看,一个视频通常可以写成:
这里:
| 符号 | 含义 |
|---|---|
| 视频帧数 | |
| RGB 三个颜色通道 | |
| 高度 | |
| 宽度 |
也就是说,视频本质上就是很多张 RGB 图像沿时间维堆叠起来的结果。问题在于,这个表示太大了,不能直接高效送进后续生成模型。
Hunyuan Video 的 3D VAE 要做的,就是把这种原始像素表示压缩成更小的时空 latent:
- 时间缩小 4 倍。
- 空间缩小 8 倍。
- 通道数变成 16。
可以把压缩前后写成一个更直观的对照:
| 阶段 | 典型表示 | 目的 |
|---|---|---|
| 原始视频 | 保留完整像素信息,但计算量极大 | |
| 3D VAE latent | 大幅压缩时空尺寸,降低后续 Transformer 成本 |
这样做的直接收益,是显著减少后续 diffusion transformer 的计算量,使得高分辨率、原帧率视频训练成为可能。
CausalConv3D 的意义
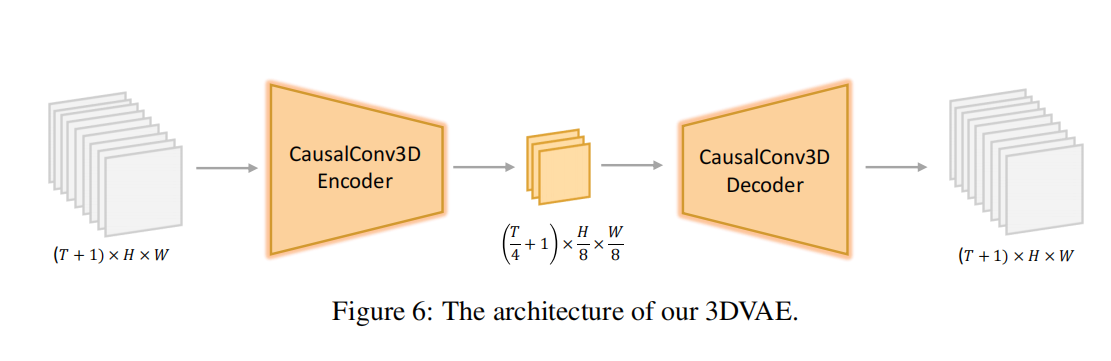
CausalConv3D 的含义是:在处理第 t 时刻的帧时,只看当前和过去帧,不看未来帧。
把它直接压成一句工程判断就是:
| 设计 | 直接作用 |
|---|---|
| 只看过去和当前帧 | 避免当前表示偷看未来信息 |
| 在编码阶段保留时间方向性 | 更容易维持生成时的时间一致性 |
所以它的价值不是“换一种卷积写法”,而是把时间上的因果约束显式写进编码模块。
Patchify:Transformer 为什么非要把视频切成 token
Transformer 不能直接吃一个五维视频张量,所以还需要一步 token 化。
Movie Gen 在这里做的事情,其实可以直接写成一个三步流程:
| 步骤 | 发生了什么 | 目的 |
|---|---|---|
| 1 | 用 3D 卷积把视频 latent 切成 patch | 把大张量拆成更小局部块 |
| 2 | 把 patch 展平成 1D token 序列 | 适配 Transformer 输入形式 |
| 3 | 把 token 送入 Transformer 统一建模 | 在 token 空间里处理整段视频表示 |
如果用时空 patch 大小 去切一个大小为 的时空表示,那么 token 数量可以近似写成:
这条式子的含义很直观:每个 token 对应一个大小为 的时空块,所以 patch 越大,token 越少;patch 越小,序列越长。
笔记中特别提到,作者采用的是 1 × 2 × 2 patch,也就是:
- 只在空间上分块。
- 不在时间上分块。
核心权衡很简单:尽量减少 token 数量,同时保留时间连续性。
Position Embedding:位置信息不能只在第一层打一遍补丁
视频的位置信息不是单一维度,而是时间、高度、宽度三维共同决定的。
这块真正重要的不是图本身,而是下面这个结论:
| 设计选择 | 作用 |
|---|---|
| 时间、高度、宽度三维分解位置编码 | 同时编码时空位置信息 |
| 在所有 Transformer 层持续注入 | 防止位置信息随层数加深被淡化 |
| 支持任意尺寸和长度输入 | 降低时间维漂移和形变伪影 |
如果把一个 patch 的位置不再看成单个索引 ,而是拆成时间、高度、宽度三个坐标,那么对应的位置编码可以写成:
- 时间位置编码:
- 高度位置编码:
- 宽度位置编码:
最后把三者相加,得到最终位置编码:
这就是 factorized positional embedding 的含义:把三维位置拆成多个独立的一维位置编码,再组合成最终的时空位置信号。
换句话说,这不是为了“多加一点信息”,而是为了让模型始终记得 token 在时空上的相对位置。
Transformer 主干:文本条件、时间条件与双向注意力
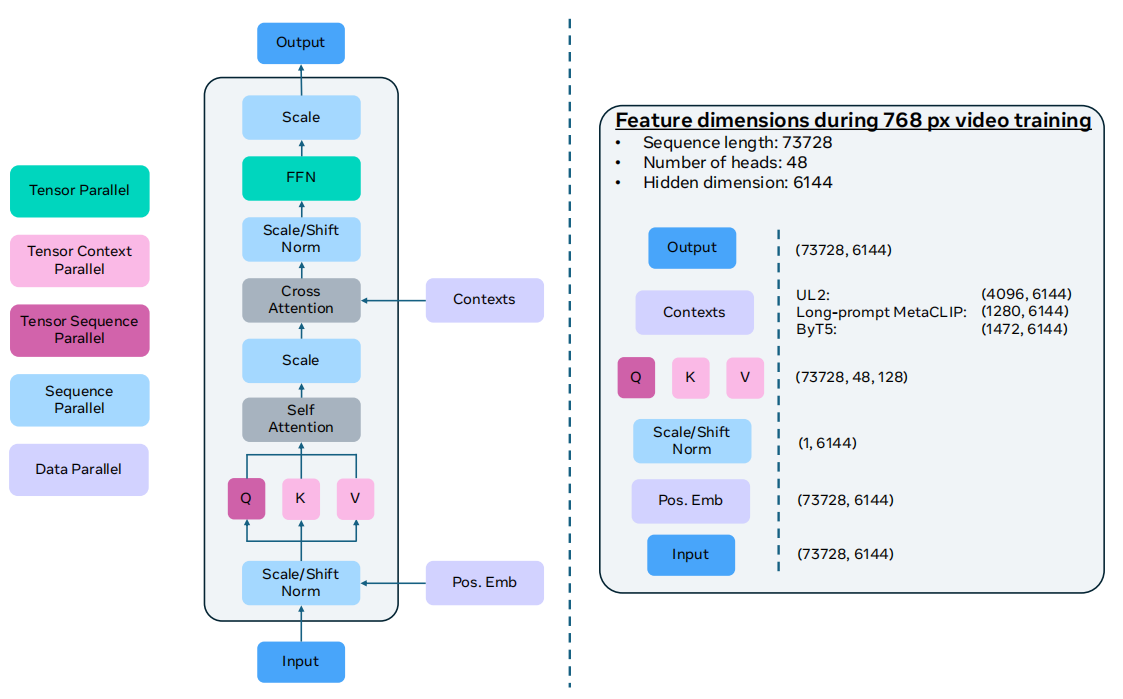
Movie Gen 的 baseline 沿用了 LLaMA3 风格的 Transformer block,并保留 RMSNorm 和 SwiGLU,但为了适配视频生成,又增加了几个关键改动。
在连续看概念时,这里也适合直接用表格压缩信息,而不是全部靠段落解释:
| 组件 | 作用 | 为什么重要 |
|---|---|---|
| Cross-Attention | 让视觉 token 接收文本条件 | 决定“生成什么”如何持续进入主干 |
| 时间步条件 | 告诉模型当前噪声水平 / 生成阶段 | 决定当前该如何更新状态 |
| 双向注意力 | 让 token 访问全局上下文 | 更适合联合建模整段视频 latent |
| 位置编码 | 持续编码时间、高度、宽度位置 | 减少时空漂移与形变 |
| AdaLN | 用条件动态调制层内特征 | 低成本、持续地注入条件信号 |
Cross-Attention:把“生成什么”注入视觉建模
在每个 Transformer block 中加入 cross-attention,让视觉 token 可以接收文本提示的 embedding。这一步的作用不是简单拼接,而是在 token 级交互中把“我要生成什么内容”持续注入视觉建模过程。
时间步条件:让模型知道自己正在哪一个生成阶段
视频生成模型必须知道当前处于第几个扩散或流匹配时间步,否则就无法判断当前噪声水平和应该采取的更新方向。因此系统会通过 adaptive layer normalization 一类模块,把时间步信息注入网络内部。
双向注意力:视频生成不是 next-token prediction
与语言模型常见的 causal attention 不同,这里更适合使用 full bi-directional attention。原因在于视频生成不是单向预测下一个 token,而是在整个 latent 或 token 空间上联合建模。让每个位置看到全局上下文,通常比强行维持严格单向约束更合理。
AdaLN:条件信息是怎样调制 Transformer 的
为了理解视频生成里的“时间条件”,先看 AdaLN 的作用会比较直观。
普通 LayerNorm 可以写成:
LN(x) = (x - mean(x)) / sqrt(var(x) + eps)y = gamma * LN(x) + beta
而 AdaLN 的思路是,让 gamma 和 beta 不再是固定参数,而是由额外条件动态生成:
y = (1 + scale(c)) * LN(x) + shift(c)
这里的条件 c 可以是:
- 时间步 embedding
- 文本条件 embedding
- 类别标签
- 分辨率、帧率、镜头条件等控制信号
也就是说,LayerNorm 负责稳定特征分布,而条件网络负责告诉模型:在当前条件下,这一层应该朝什么方向偏移。AdaLN 的价值不是替代注意力,而是在每一层里提供一种低成本、可持续的条件调制机制。
DiT:条件到底该怎么注入
笔记里提到的 DiT 条件注入方式,本质上可以直接压成一个对比表:
| 方式 | 怎么做 | 更适合解决什么问题 |
|---|---|---|
adaLN-Zero | 用全局条件调制归一化和残差强度 | 低成本地把时间步、类别等条件持续注入每层 |
Cross-Attention | 让视觉 token 和条件 token 直接交互 | 文本条件较长、需要显式对齐时更自然 |
In-Context Conditioning | 把条件 token 和输入 token 拼接后统一建模 | 希望由 Transformer 自己学习条件与内容关系 |
三者的核心差别不在“谁更高级”,而在条件信息通过哪条路径进入主干:是调制特征、显式对齐,还是直接拼接后统一处理。
Flow Matching:训练时到底在学什么

如果只把 Flow Matching 理解成“另一种扩散训练法”,很容易抓不到重点。更准确的理解是:模型在学习一个连续动力系统中的方向场。
笔记里把训练过程概括得很清楚:给定某个中间状态 X_t,模型学习预测它应该沿哪个方向移动,才能从噪声逐步流向真实视频样本 X_1。
这里最核心的信息其实也可以直接压成表格:
| 阶段 | 模型在做什么 |
|---|---|
| 训练 | 给定中间状态 X_t,学习预测当前该往哪个方向移动 |
| 推理 | 从纯噪声 X_0 出发,沿着模型给出的方向一步步积分到目标样本 X_1 |
| 本质 | 学连续空间中的速度场,而不是离散的下一个 token |
如果再往下写到训练定义,这里真正需要保留下来的变量也应该直接写在正文里:
| 符号 | 含义 |
|---|---|
X_1 | 真实视频的 latent 表示 |
X_0 | 高斯噪声,通常满足 |
t | 时间步,取值在 |
\sigma_{\min} | 很小的正数,用来控制路径末端噪声下界 |
对应地,中间样本可以写成:
其中,笔记里给出的取值是:
对应的真实速度场可以写成:
如果把模型记作 ,其中 是文本提示 embedding,那么训练时最小化的是预测速度和真实速度之间的均方误差:
把这些式子直译成人话,就是:训练时先构造一个位于噪声和真实样本之间的中间状态 X_t,再让模型学习“从这个位置该往哪里走”。
推理:从噪声积分到最终视频
有了上面的视角,推理阶段就变得容易理解了:从纯高斯噪声 X_0 开始,把模型预测的速度 dX_t/dt 送入 ODE 求解器,逐步积分,得到最终样本 X_1。
可以把这个过程理解成:
- 噪声是起点。
- 真实视频是终点。
- 模型学的是每个时刻“该往哪里走”。
- ODE 求解器负责把这些局部方向拼成整条轨迹。
因此 Flow Matching 的推理更像是在一个连续场中“流动到目标分布”,而不是一步步机械地修补噪声。
结果图真正说明了什么
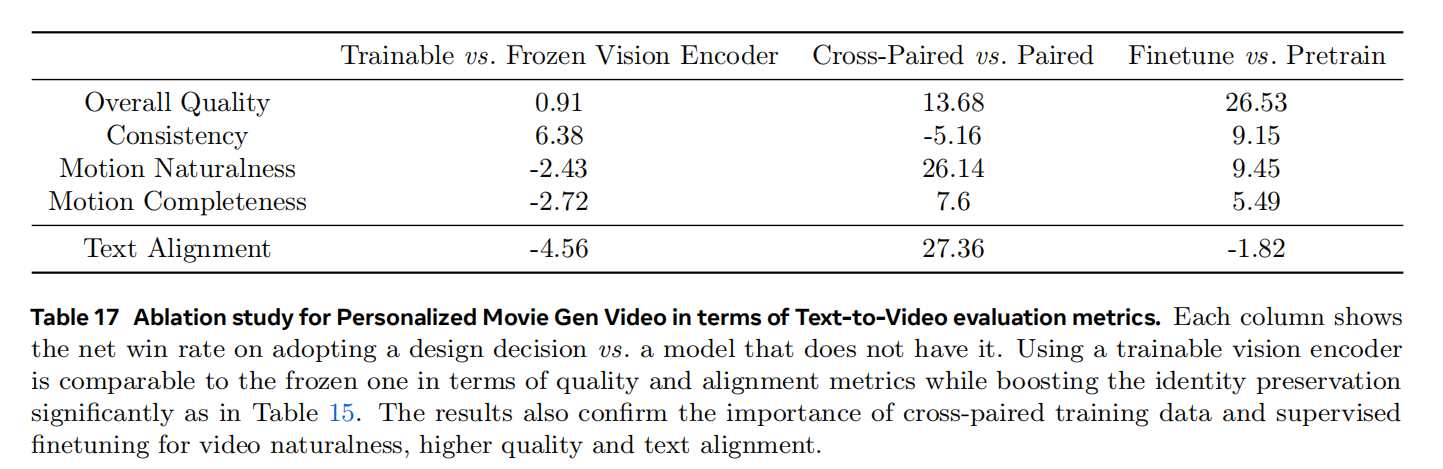
这张结果图本身只适合做直观展示,真正该从正文里带走的是下面四点:
| 观察维度 | 结果图想说明什么 |
|---|---|
| 分辨率 | 系统在高分辨率表示上有可用性 |
| 时间一致性 | 结果不只是单帧清晰,还要跨帧稳定 |
| 条件控制 | 文本与镜头条件能够影响最终输出 |
| 效率 | 训练成本与生成质量之间要取得平衡 |
换句话说,这类系统追求的并不只是单帧画质,而是压缩表示、token 化、条件注入和训练目标共同协作后的整体效果。
总结
如果把第一篇的数据引擎看成“模型会学到什么”的上游约束,那么这一篇谈的就是模型内部“究竟怎么学”。
从这份笔记可以把视频生成模型的工作流程浓缩成四步:
- 先把原始视频压缩到 latent 空间。
- 再把 latent 切成 token 交给 Transformer。
- 用文本条件、时间条件和位置编码约束生成过程。
- 通过 Flow Matching 或类似目标,让模型学会从噪声走向真实视频。
因此,视频生成模型真正的核心不在于某个单独模块有多“新”,而在于它怎样把压缩、建模与生成三件事在时空表示上重新组织起来。