视频理解早期的发展主线,其实可以浓缩成三个连续追问。第一,如果把视频当成多帧图像送进 CNN,会发生什么? 第二,如果单帧外观不足以表达动作,是否应该显式建模运动? 第三,如果外观与运动已经拆成两条流,它们应该如何融合、在哪一层融合、怎样继续做时间建模?
沿着这条主线,DeepVideo、Two-Stream 与 Early Fusion 形成了一条非常清晰的演进链条。前者证明“多帧 + CNN”是值得探索的方向,中间这篇工作把问题重新拆解为外观与运动两类信号,最后一篇则继续把问题推进到特征交互与时空融合层面。今天回看,这三篇论文几乎奠定了后续 TSN、I3D、SlowFast 乃至 Video Transformer 的很多基本问题意识。
三篇论文列表
- Large-scale Video Classification with Convolutional Neural Networks — Andrej Karpathy et al., CVPR 2014
- Two-Stream Convolutional Networks for Action Recognition in Videos — Karen Simonyan, Andrew Zisserman, NeurIPS 2014
- Convolutional Two-Stream Network Fusion for Video Action Recognition — Christoph Feichtenhofer, Axel Pinz, Andrew Zisserman, CVPR 2016
研究动机
图像分类主要回答“这是什么”,而视频理解还必须回答“它是怎么动的”。这意味着:时间信息不是视频任务的附属品,而是决定类别的重要信号来源。许多动作类别在单帧层面极其相似,例如挥手、投掷、击球、游泳等,真正把它们区分开的往往不是静态姿态,而是运动方向、速度模式和时间上的演化关系。
早期研究者首先尝试的自然思路,是把视频拆成多帧后继续交给 2D CNN 处理。但这很快引出新的问题:
- 时间信息应该在输入层、中间层还是输出层进入网络?
- 外观与运动是否适合由同一条网络统一建模?
- 如果拆成多条分支,应该怎样重建时空交互?
DeepVideo、Two-Stream 与 Early Fusion 分别对应这三个问题阶段,因此把它们放在一起看,比孤立看单篇论文更能理解视频理解方法为何会这样演进。
核心方法/模型架构
DeepVideo:先回答“多帧怎么喂给 CNN”
DeepVideo 是最早系统探索 CNN 处理视频方式的工作之一。它的重要性不在最终精度,而在于它第一次用较完整的实验回答:时间信息究竟应该在网络的哪一层进入。
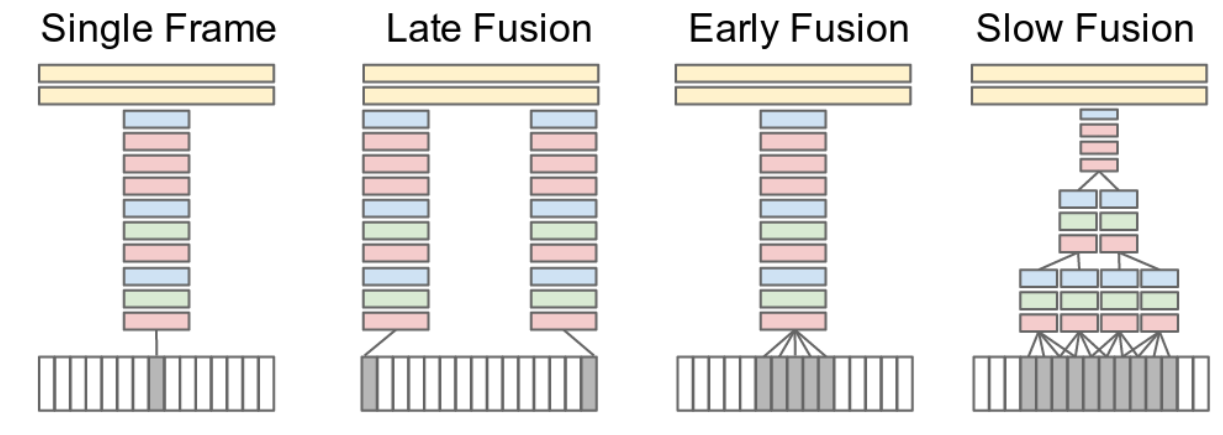
论文比较了四种典型策略:
- Single Frame:只看一帧,把视频退化成图像分类;
- Late Fusion:两帧分别过 CNN,最后在输出层融合;
- Early Fusion:多帧在通道维拼接,让时间信息在输入层进入;
- Slow Fusion:在中间特征层逐步融合多帧信息。
这四种方式表面上是不同结构,实质上是在比较同一个设计维度:时间信息到底何时进入网络、以什么粒度进入网络。
论文还尝试了多分辨率输入,用两个权重共享的网络分别处理原图与 center crop 图像,以同时学习全局信息与中心区域细节。
但真正有启发性的地方在于结果:四种融合方式最终差异并不大。 即使在 Sports-1M 这类百万级数据集上预训练,再迁移到 UCF-101,精度也只有约 65%。这说明在当时条件下,简单地把多帧堆给 2D CNN,还不足以真正学到强时序表示。DeepVideo 证明了方向可行,却也清楚暴露了“简单堆帧”的上限。
Two-Stream:把外观与运动拆开建模
Two-Stream 的核心突破在于,它不再把视频简单看成“多帧图像集合”,而是明确区分两类互补信号:
- 空间流(Spatial Stream):看单帧 RGB,建模外观、场景、姿态;
- 时间流(Temporal Stream):看连续光流堆叠,建模方向、速度与运动模式。
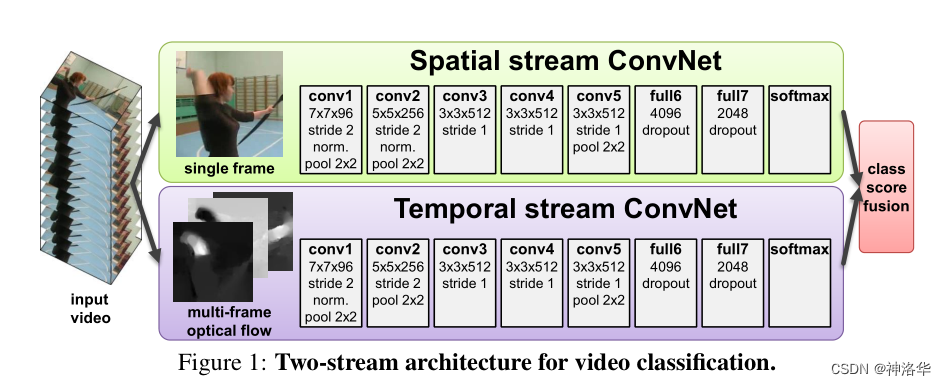
这个架构之所以成为经典,并不是因为它结构复杂,而是因为它对问题拆解得非常准确。空间流回答“画面里有什么”,时间流回答“目标怎么动”,最后再把两条流的分类分数做 late fusion。形式上可写成:
其中 和 分别是两条流输出的 logits, 是融合权重。
这种设计有三个直接优势:
- 可以直接复用成熟图像 CNN;
- 运动信息被显式而不是隐式建模;
- 工程上两条流可以独立训练、独立分析,再统一融合。
Early Fusion:继续追问“如何融合、在哪里融合、怎样做时间融合”
Two-Stream 把问题拆开后,新的问题变成:两条流不该只在最后融合。 如果空间流与时间流直到输出层才交互,中间大量丰富的特征关系就会被浪费。于是 Early Fusion 研究的重点转向三个问题:
- 如何融合;
- 在哪一层融合;
- 时间维度上怎样继续做特征聚合。
论文比较了多种空间融合方式,设输入特征为 和 ,输出为 :
- Sum Fusion:
- Max Fusion:
- Concatenation Fusion:
- Conv Fusion:
- Bilinear Fusion:通过更强的乘性交互捕捉两条流之间的关系
在这些方式里,最值得关注的是 Conv Fusion,因为它第一次把“融合”从固定规则推进成了可学习变换。这也是后来很多时空融合模块不断演化的起点。
组件详解
DeepVideo 的四种融合策略
DeepVideo 之所以重要,是因为它把视频 CNN 的几个最基本选项都摆到了实验台上。Single Frame 是最弱但最干净的静态基线;Late Fusion 延迟交互,结构简单但时空信息结合太晚;Early Fusion 让多帧从第一层就进入网络,但会显著增加输入通道;Slow Fusion 则试图在表示层级更高的位置逐步引入时间信息,在表达力和结构复杂度之间做折中。
从今天回看,这四种策略几乎可以看作后续很多视频模型设计的原始模板:时间信息要么早进、要么晚进、要么分层进入、要么单独建模再融合。
Two-Stream 的时间流与特征聚合
Two-Stream 的历史意义在于它第一次明确承认:动作识别不仅是外观识别,更是运动识别。 这一步使视频理解从“把多帧堆进 CNN”升级为“按信号类型拆解建模”。
在原始双流网络基础上,后续研究很快沿着四个方向推进:特征层融合、更强 backbone、引入 LSTM、扩展到更长时间跨度。其中特征聚合与 LSTM 是最直观的延展路线:先逐帧提特征,再沿时间轴做 pooling 或序列建模。
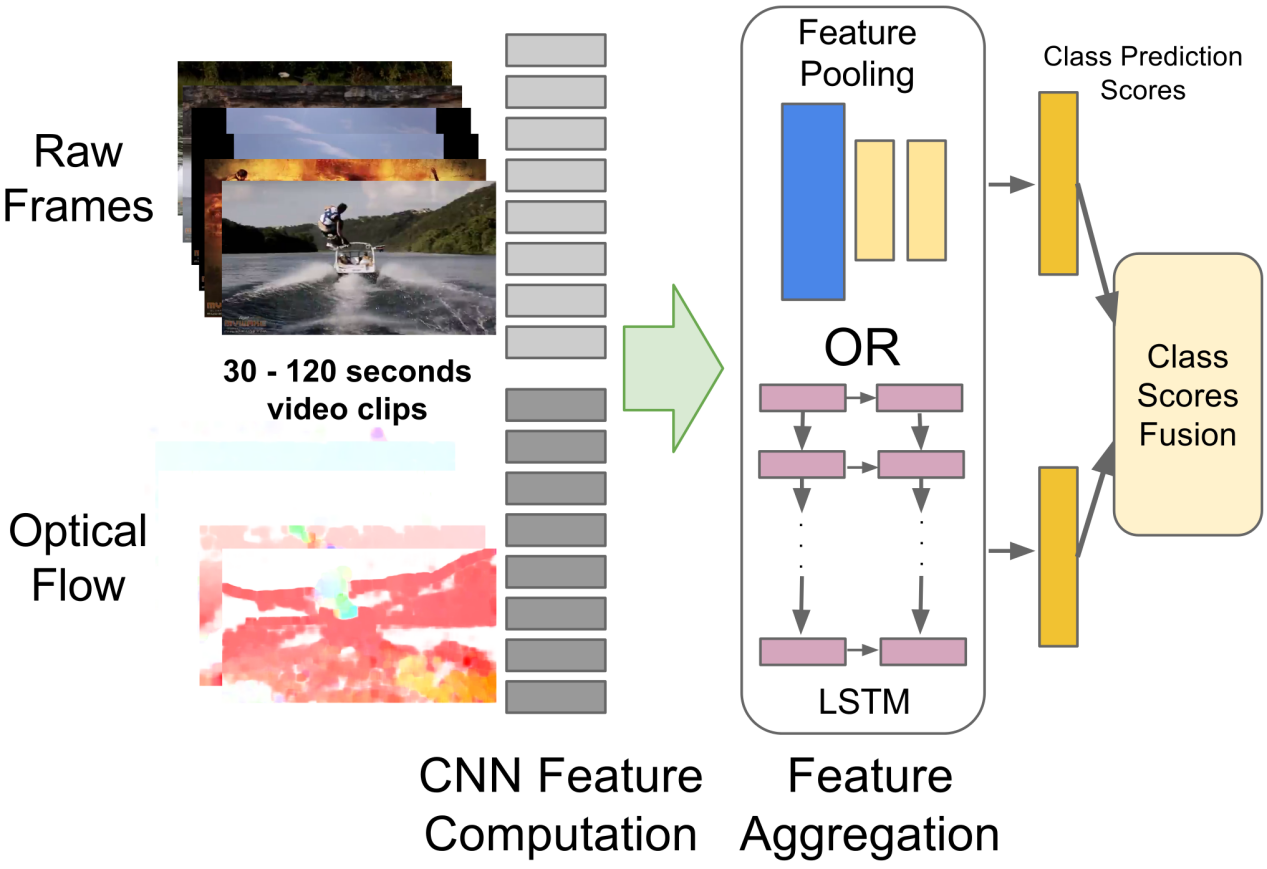
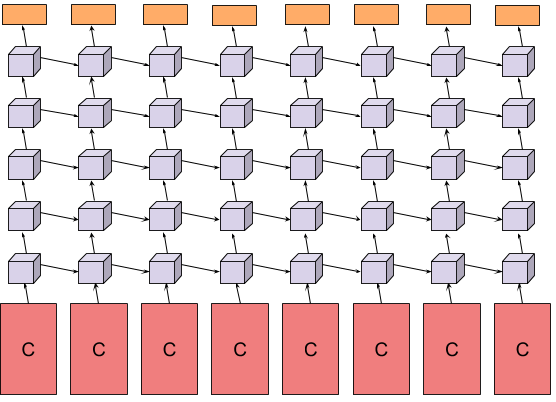
但一个很有价值的经验是:LSTM 在 UCF-101 这类短视频上提升并不明显。 原因不是 LSTM 不够强,而是短视频本身语义变化有限,相邻帧表示过于相似,难以给高层时序模型提供足够强的学习信号。这一结论提醒我们:时序建模的有效性与视频长度、动作节奏和数据规模直接相关。
Early Fusion 的融合位置与时间融合
除了“怎么融合”,Early Fusion 还证明了“在哪里融合”同样关键。
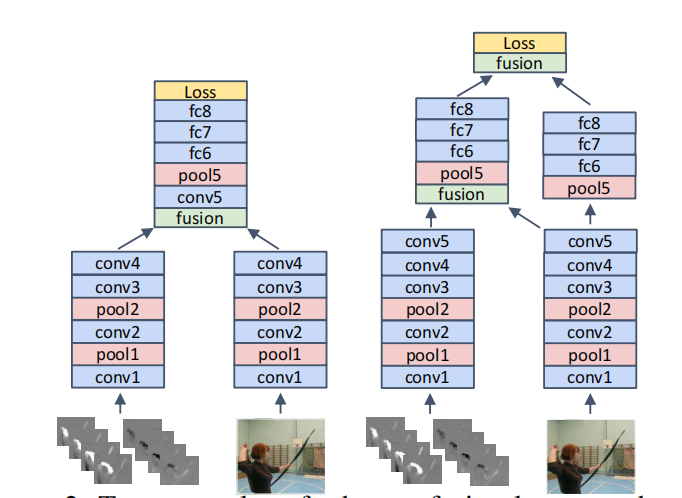
实验表明,在较高层卷积特征之后融合通常更合理,因为此时两条流已经分别提取出较有语义的表示;若融合过早,特征过于底层,语义不足;若融合过晚,又会退化回原始的 late fusion。
更进一步,作者把时间轴上的特征聚合也纳入系统比较:
- 2D Pooling:基本忽略时序结构;
- 3D Pooling:开始把时间维纳入聚合;
- 3D Conv + 3D Pooling:显式学习时空联合模式。
这里的转折非常关键。3D Conv + 3D Pooling 不再只是“在时间上平均一下”,而是让模型真正去学时间维和空间维之间的联合结构。这条思路实际上已经预示了后来 I3D、SlowFast、R(2+1)D 等 3D 视频模型的发展方向。
完整架构:从双流到时空联合建模
Early Fusion 的完整架构不只是简单加一个融合层,而是更系统地组织时空联合表示。
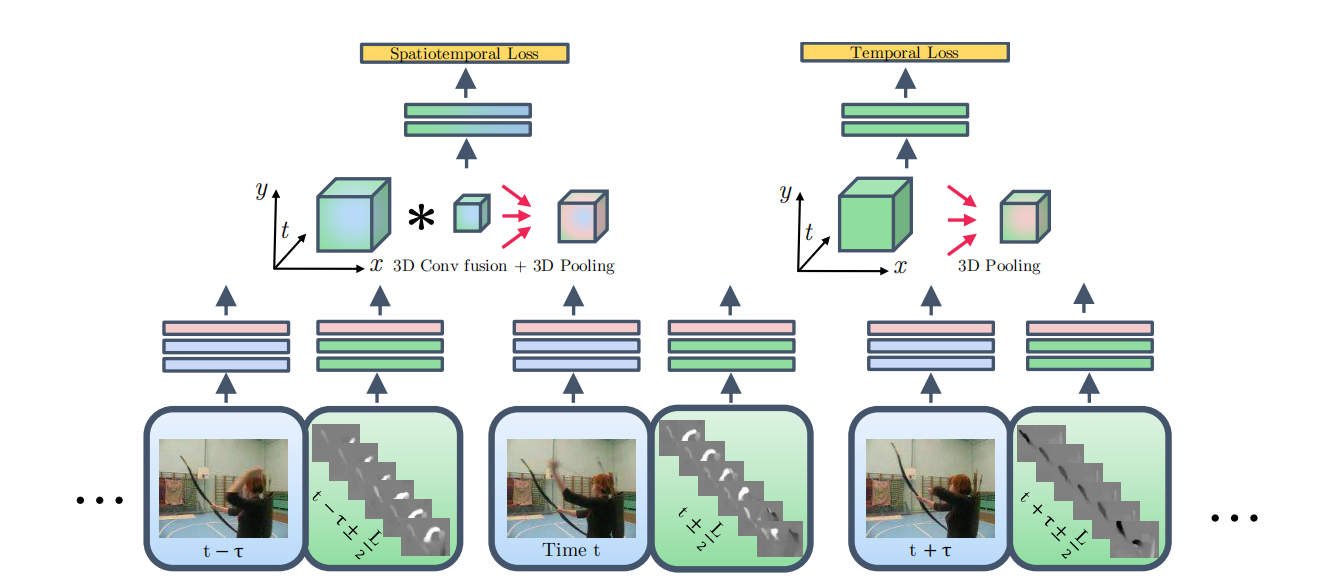
整体流程可以概括为:
- 在多个时间点采样视频;
- 分别提取 RGB 外观特征与光流运动特征;
- 在合适卷积层做空间融合;
- 再沿时间轴堆叠后使用 3D 卷积 / 3D 池化;
- 通过不同分支的损失共同监督时空信息与纯运动信息。
这种做法的核心思想可以概括成一句话:不要等到最后才让外观与运动相遇,而要尽早让它们在特征层发生交互,并继续沿时间轴学习联合表示。
实验结果
把三篇论文放在一起看,实验结论比单独记住某一篇的精度更重要。
- DeepVideo 证明了多帧 CNN 是可行方向,但简单堆帧难以得到足够强的时间表示;
- Two-Stream 证明了显式运动建模非常有效,空间流与时间流具有明显互补性;
- Early Fusion 进一步证明了更早的特征交互和更强的时空融合,在小数据集上尤其能带来收益。
如果从方法演进角度总结,这三篇论文共同完成了三件事:
- 找到时间信息进入 CNN 的几种基本方式;
- 找到外观与运动拆分建模的经典范式;
- 找到从分数融合走向特征融合、再走向时空联合建模的方向。
总结
DeepVideo、Two-Stream 与 Early Fusion 代表的不是三篇彼此孤立的论文,而是视频理解早期最重要的一条方法演化链。DeepVideo 说明“多帧 + CNN”值得做,但也暴露了简单堆帧的上限;Two-Stream 把问题重新拆成外观与运动两类信号,建立了视频动作识别的经典范式;Early Fusion 则继续推进到特征交互与时间融合层面,把问题从“是否分流”推进到“分流之后如何重新统一”。
从今天回看,这条路线之所以重要,是因为它几乎定义了后续视频模型长期围绕的几个核心问题:时间信息怎样进入网络、外观与运动如何协调建模、时空交互应发生在哪个层级。后来的 TSN、I3D、SlowFast 和 Video Transformer,只是在更强的数据、算力和建模工具下,对这些问题给出了新的答案。
代码实战
为了把这三篇论文的思想落到可运行代码,我配套写了一份教学型 Notebook。它不是对原论文完整 benchmark 的复现实验,而是用一个可在 Colab 运行的 toy video 任务,把“视频分类为什么需要时间信息”“双流结构为什么合理”“融合方式如何体现在代码里”讲清楚。
完整代码实战:
![]()
这份 Notebook 同时包含学习路径和工程路径两条线。学习路径里,我把 DeepVideo 的几种融合策略、Two-Stream 的双流建模、以及 Early Fusion 的空间融合模块都拆成最小可理解组件;工程路径里,则用 torchvision.models.resnet18 组装了更接近真实项目代码的双流基线。
第一段最关键的代码,是用帧差分近似运动信息:
def compute_frame_diffs(videos):
return videos[:, 1:] - videos[:, :-1]这当然不等价于真实光流,但足以在教学环境里保留“时间流负责运动信息”的核心思想。
第二段关键代码,是教学版双流网络的核心实现:
class TwoStreamLearningNet(nn.Module):
def __init__(self, temporal_channels, num_classes, spatial_weight=0.5):
super().__init__()
self.spatial = Small2DBackbone(in_channels=1)
self.temporal = Small2DBackbone(in_channels=temporal_channels)
self.spatial_head = nn.Linear(128, num_classes)
self.temporal_head = nn.Linear(128, num_classes)
self.spatial_weight = spatial_weight
def forward(self, spatial_input, temporal_input):
spatial_logits = self.spatial_head(self.spatial(spatial_input))
temporal_logits = self.temporal_head(self.temporal(temporal_input))
fused_logits = self.spatial_weight * spatial_logits + (1 - self.spatial_weight) * temporal_logits
return fused_logits这段实现基本把 Two-Stream 的思想压缩成最核心的计算图:一条分支看外观,一条分支看运动,最后做 logits 级融合。
第三段关键代码,对应 Early Fusion 里的可学习融合思想:
class SpatialFusionConv(nn.Module):
def __init__(self, channels):
super().__init__()
self.conv = nn.Conv2d(channels * 2, channels, kernel_size=1)
def forward(self, a, b):
x = torch.cat([a, b], dim=1)
return self.conv(x)这段代码的意义在于:它不再把融合当成固定规则,而是通过一个可学习卷积去决定空间流和时间流特征应如何组合。
最后,工程路径版本把相同思想迁移到更成熟的 backbone 上:
class TwoStreamResNet(nn.Module):
def __init__(self, temporal_channels, num_classes, spatial_weight=0.5):
super().__init__()
self.spatial_stream = ResNetStream(in_channels=1, num_classes=num_classes)
self.temporal_stream = ResNetStream(in_channels=temporal_channels, num_classes=num_classes)
self.spatial_weight = spatial_weight
def forward(self, spatial_input, temporal_input):
spatial_logits = self.spatial_stream(spatial_input)
temporal_logits = self.temporal_stream(temporal_input)
fused_logits = self.spatial_weight * spatial_logits + (1 - self.spatial_weight) * temporal_logits
return fused_logits这一版更接近真实工程:保留双流思想,但把卷积细节交给成熟 backbone,让模型结构更简洁、可维护性更强。
参考文献
- Karpathy, A., Toderici, G., Shetty, S., Leung, T., Sukthankar, R., & Li, F. F. (2014). Large-scale Video Classification with Convolutional Neural Networks. CVPR 2014.
- Stanford. DeepVideo project page.
- Simonyan, K., & Zisserman, A. (2014). Two-Stream Convolutional Networks for Action Recognition in Videos. NeurIPS 2014.
- University of Oxford VGG. Project Page: Two-Stream Convolutional Networks for Action Recognition in Videos.
- Feichtenhofer, C., Pinz, A., & Zisserman, A. (2016). Convolutional Two-Stream Network Fusion for Video Action Recognition. CVPR 2016.