Open-vocabulary Object Detection via Vision and Language Knowledge Distillation
Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, Yin Cui — ICLR 2022
ViLD 是开放词汇目标检测方向的代表性工作之一。它抓住了一个关键事实:传统两阶段检测器通常已经能找到目标区域,但第二阶段分类头仍然是闭集的,因此模型即使“看见了”目标,也说不出训练标签之外的类别名称。
这篇论文的价值,不只是把 CLIP 文本特征拿来替换分类器,而是同时把 文本语义对齐 和 视觉知识蒸馏 放进 detector 的训练流程中。前者让模型学会用文本原型分类,后者让区域特征进入开放世界语义空间,因此 detector 才能在只见过基础类标注的前提下泛化到新类别。
研究动机
传统 Faster R-CNN 或 Mask R-CNN 的第二阶段,本质上是一个固定维度的分类器。训练时定义了多少类,推理时就只能输出多少类;即使 proposal 已经准确覆盖目标区域,只要类别没有出现在训练标签中,模型仍然无法给出正确命名。
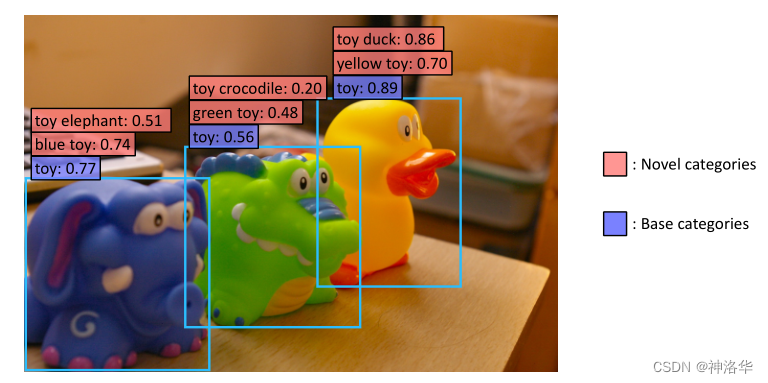
如果用更直观的语言概括,传统检测器更容易把目标停留在“玩具”“动物”这类基础类层面;而 ViLD 希望在已有候选框上进一步识别出更细粒度的新类别名称。这说明 proposal 机制并不是主要瓶颈,真正受限的是闭集分类头。
为了看清 ViLD 为什么建立在两阶段检测器之上,可以先把一阶段与二阶段检测器的差异压缩成一张表:
| 项目 | 一阶段 | 二阶段 |
|---|---|---|
| 流程 | 直接预测类别 + 边框 | 先生成候选框,再分类和回归 |
| 是否使用 Region Proposal | 否 | 是,例如 RPN |
| 特征处理 | 全图密集预测 | 对每个 proposal 做 ROI 特征提取 |
| 推理结构 | 单路径 | 级联两阶段 |
ViLD 的判断很明确:不必推翻现有 detector 的 proposal 流程,重点应该放在 proposal 之后的语义判别部分。
方法总览
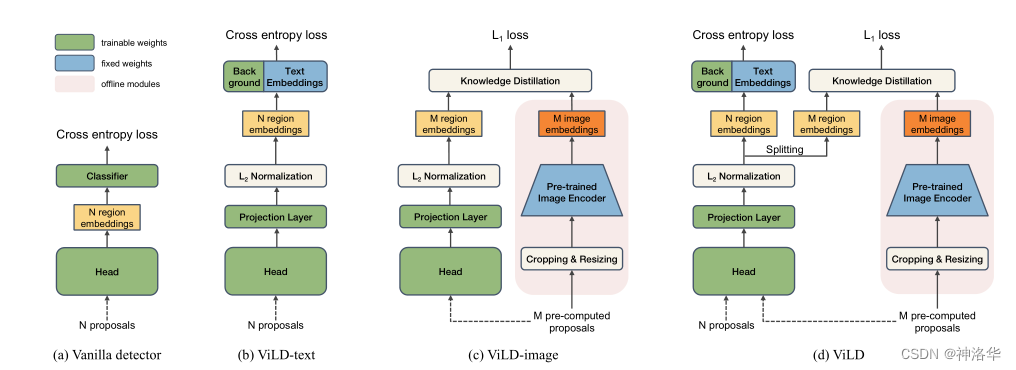
如果把 ViLD 的方法压缩成一句话,它做了两件事:
- 用文本 embedding 替换传统闭集分类器,让 detector 具备文本驱动分类能力;
- 用 CLIP image encoder 蒸馏 detector 的区域表示,让 region embedding 进入开放世界语义空间。
把训练与推理拆开之后,ViLD 的职责边界会更清楚:
| 阶段 | 是否使用 CLIP image encoder | 输入 | 核心计算 | 输出 |
|---|---|---|---|---|
| 训练 | 是 | 图像、proposal、基础类文本、proposal crop | CE 分类、box regression、L1 distillation | 学到的 region embedding |
| 推理 | 否 | 图像、文本 prompt | region-text similarity | 开放词汇类别预测 |
这张表最关键的一点是:CLIP image encoder 只在训练时扮演 teacher。真正部署时,模型只需要 detector 自己输出的 region embedding,再与文本 embedding 做相似度匹配即可。
ViLD-text:把固定分类器替换成文本原型
在传统检测器中,ROI head 后面通常直接接一个线性分类头,输出固定类别 logits。ViLD-text 则改成先得到 region embedding,再与类别文本 embedding 做相似度计算。
如果把基础类名称写成 prompt,例如 a photo of a cat,并送入冻结的文本编码器,就能得到每个类别对应的文本向量。论文还额外引入了一个可学习的背景向量,用来处理不属于基础类的区域。
这个文本分支本质上仍然属于有监督训练:文本原型对应的是基础类 ,它们和常规检测器中的 base categories 一一对应;同时,为了让模型学会拒识不属于基础类的区域,还需要额外引入一个可学习的背景 embedding。
更精确地说,如果把 proposal 记为 ,图像记为 ,检测器在 proposal 上抽取到的区域表示记为 ,则可以写成:
其中 表示图像特征提取结果, 表示基于 proposal 的区域特征抽取。接着,ViLD-text 会把该区域表示与背景向量 以及基础类文本特征 做相似度匹配:
然后对 logits 做 softmax,并与真实标签 计算交叉熵:
这里的关键不只是“把文本拿来算点积”,而是 把检测分类器从固定权重矩阵改造成文本驱动的相似度分类器。分类头不再显式存储每个类别的闭集参数,而是通过文本 embedding 动态定义类别原型。
ViLD-image:把 CLIP 的视觉语义蒸馏给 detector
如果只有 ViLD-text,模型虽然已经能做文本条件分类,但它学到的视觉特征仍然主要由基础类检测标注决定,泛化到新类别时能力有限。为了解决这个问题,ViLD 又引入了一个 teacher-student 蒸馏分支。
这个分支可以拆成两条路径:
| 路径 | 输入 | 编码器 | 输出 | 作用 |
|---|---|---|---|---|
| teacher | proposal crop | 冻结的 CLIP image encoder | image embedding | 提供开放世界视觉语义 |
| student | proposal | detector 的 ROI head + projection | region embedding | 学习可与文本对齐的区域表示 |
然后用 L1 损失约束两者接近:
这种蒸馏的本质不是分类监督,而是 embedding-level matching:让 detector 学习 CLIP 的视觉表示空间,而不是直接学习某个固定类别标签。
换句话说,ViLD-image 提供的监督信号不再来自人工标注类别,而是来自 CLIP 的图像编码。因此它突破了基础类 的限制,让 detector 可以从更开放的视觉语义空间里学习区域表示。
联合训练与工程折中
ViLD 的完整训练流程,并不是在 ViLD-text 和 ViLD-image 之间二选一,而是把两者合并起来共同优化。
| 损失项 | 形式 | 作用 | 来源 |
|---|---|---|---|
| cross-entropy loss | 基础类分类 | 基础类文本原型 | |
| L1 distillation loss | 对齐 CLIP 视觉 embedding 空间 | 冻结的 CLIP teacher | |
| bounding box regression loss | 边框回归 | 检测标注 |
因此总目标可以写成:
为了让 detector 输出可与文本对齐的区域表示,ROI 特征的生成路径也需要统一起来:
| 步骤 | 输入 / 变换 | 输出 | 作用 |
|---|---|---|---|
| 1 | RoIAlign + Box Head | 1024-d region feature | 提取区域视觉特征 |
| 2 | Projection Layer | 512-d feature | 映射到文本空间 |
| 3 | L2 Normalization | region embedding | 进入共享语义空间 |
| 4 | 与 text embedding 点积 | similarity score | 完成分类 |
这里的绿色 Head 本质上仍然是 Faster R-CNN 的 ROI Box Head,只是它不再直接输出闭集分类 logits,而是输出一个可继续投影和归一化的区域向量。
工程上,ViLD-image 分支还有一个重要折中:它并不是每次训练都对当前 RPN 生成的所有 proposal 重新跑一遍 CLIP,而是先离线抽取一批 pre-computed proposals,并预先计算好对应的 CLIP image embeddings。这样做牺牲了一部分“proposal 实时更新”的灵活性,但显著降低了训练成本;否则当 CLIP backbone 很大、每张图又要处理上百上千个 proposal 时,训练几乎无法落地。
实验结果
ViLD 的重要性,首先体现在它把开放词汇检测从概念验证推进到了更困难、更贴近真实长尾分布的数据集上。原始笔记中提到,ViLD 是较早在 LVIS 这类高难度数据集上验证开放词汇检测有效性的代表性方法之一,这使它成为后续 Detic、GLIP、OWL-ViT 等工作的关键前置节点。
从实验结果里真正值得保留的,不是某几个孤立数字,而是下面三类趋势:
| 观察 | 含义 |
|---|---|
novel categories 上有稳定提升 | ViLD 的收益不局限于基础类 |
| 提升来自视觉语言知识迁移 | 效果不是靠单纯扩大标签空间换来的 |
| 区域表示被明显重塑 | detector 的 region representation 真正进入了共享语义空间 |
如果换一种更贴近阅读图表的方式理解,实验部分想说明的是:ViLD 不是只在个别样例上偶然奏效,而是在更困难、更长尾的数据分布下,依然表现出开放词汇检测的系统性收益。它把“语言可查询”这件事真正落实到了 detector 的 region representation 上。
定性结果应该怎么看
定性结果的重点,也不在于某一张例图本身,而在于模型开始能够在 proposal 已经足够准确的前提下,把基础类区域重新命名为更细粒度、更开放的类别标签。这说明 ViLD 真正改变的是第二阶段的语义判别能力,而不是 proposal 生成能力。
从这些可视化案例里,可以读出三点:
- proposal 机制本身并不是开放词汇检测的主要瓶颈,真正受限的是闭集分类头;
- 当 region embedding 被拉到视觉语言共享空间后,检测器就有机会用更细粒度的文本语义重新解释同一个区域;
- ViLD 的价值不是替换整个检测框架,而是在保留两阶段检测结构的前提下,把开放世界识别能力注入到 ROI 表征里。
总结
ViLD 的核心贡献,可以浓缩成一句话:用文本特征改造检测器的分类方式,再用图像特征蒸馏检测器的视觉表示。
只做第一步,模型会具备文本驱动分类能力,但开放世界泛化仍然有限;只做第二步,模型又缺少显式的文本语义接口。ViLD 的价值恰恰在于把这两部分结合起来,使两阶段检测器既能保留目标检测的结构优势,又能获得开放词汇识别能力。
从今天回看,这篇论文未必是工程上最简洁的方案,但它非常清楚地回答了一个关键问题:为什么开放词汇目标检测是可能的,以及应该把视觉语言模型的知识蒸馏到检测器的哪个位置。
代码实战
这份 notebook 的价值,不在于复现完整论文训练流程,而在于把 ViLD 最关键的机制拆成可运行、可讲解的几个局部模块。
![]()
第一个关键片段,是把传统 ROI 特征映射成 region embedding,并与文本 embedding 做相似度分类。下面这段实现直接对应 ViLD-text 的核心思想。
class ViLDTextBranch(nn.Module):
def __init__(self, roi_feat_dim=256 * 7 * 7, hidden_dim=1024, embed_dim=512):
super().__init__()
self.fc1 = nn.Linear(roi_feat_dim, hidden_dim)
self.fc2 = nn.Linear(hidden_dim, hidden_dim)
self.projection = nn.Linear(hidden_dim, embed_dim)
self.bg_embedding = nn.Parameter(torch.randn(1, embed_dim))
def get_region_embeddings(self, roi_features):
x = F.relu(self.fc1(roi_features))
x = F.relu(self.fc2(x))
x = self.projection(x)
x = F.normalize(x, p=2, dim=-1)
return x
def forward(self, roi_features, text_embeddings):
region_embeds = self.get_region_embeddings(roi_features)
bg_norm = F.normalize(self.bg_embedding, p=2, dim=-1)
classifier = torch.cat([text_embeddings, bg_norm], dim=0)
logits = region_embeds @ classifier.T
return logits, region_embeds第二个关键片段,是用 CLIP image encoder 对 proposal 做蒸馏。它对应 ViLD-image 的 teacher-student 机制,也解释了为什么训练时可以利用开放世界视觉语义,推理时却不需要再保留图像 teacher。
def simulate_vild_image_distillation(image, proposals_boxes, clip_model, clip_processor, student_head):
teacher_embeds = []
width, height = image.size
for box in proposals_boxes:
x1, y1, x2, y2 = box
crop = image.crop((int(x1 * width), int(y1 * height), int(x2 * width), int(y2 * height)))
teacher_inputs = clip_processor(images=crop, return_tensors='pt')
teacher_inputs = {k: v.to(device) for k, v in teacher_inputs.items()}
with torch.no_grad():
teacher_embed = clip_model.get_image_features(**teacher_inputs)
teacher_embed = F.normalize(teacher_embed, p=2, dim=-1)
teacher_embeds.append(teacher_embed)
teacher_embeds = torch.cat(teacher_embeds, dim=0)
dummy_roi = torch.randn(len(proposals_boxes), ROI_FEAT_DIM, device=device)
student_embeds = student_head.get_region_embeddings(dummy_roi)
distill_loss = F.l1_loss(student_embeds, teacher_embeds)
return teacher_embeds, student_embeds, distill_lossNotebook 的最后一部分没有强行复现完整 ViLD,而是借助 OWL-ViT 做了一个更容易运行的 open-vocabulary demo。这种安排很合理:ViLD 更适合理解方法设计,OWL-ViT 更适合作为实际可跑的演示入口。
如果你的目标是准备面试、课程汇报或论文分享,这份 notebook 已经覆盖了最关键的三件事:
- 传统 detector 为什么是闭集的。
- ViLD-text 如何把分类器改成文本驱动匹配。
- ViLD-image 如何把 CLIP 的开放世界视觉语义蒸馏进检测器。
参考文献
- Xiuye Gu, Tsung-Yi Lin, Weicheng Kuo, Yin Cui. Open-vocabulary Object Detection via Vision and Language Knowledge Distillation.
- OpenReview. Open-vocabulary Object Detection via Vision and Language Knowledge Distillation.
- Colab Notebook. ViLD 代码实战.
- Google Research Demo Code. ViLD Project in tensorflow/tpu.
- 知乎专栏文章. 参考链接.