ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
Wonjae Kim, Bokyung Son, Ildoo Kim — ICML 2021
ViLT 的价值,不只是“把图像也切成 patch”这么简单。它真正回答的是另一个更关键的问题:视觉语言预训练里,算力到底应该花在视觉预处理上,还是花在图文交互上?
在 ViLT 之前,很多 VLP 模型把大量计算预算消耗在图像侧的 CNN 或区域检测器上,真正负责跨模态理解的 Transformer 反而不是系统瓶颈。ViLT 的判断很激进:既然文本可以直接变成 token 送进 Transformer,那么图像也可以。于是它拿掉了卷积骨干和区域监督,把计算重心重新拉回多模态交互本身。
背景:传统 VLP 模型为什么慢
ViLT 出现之前,主流视觉语言预训练模型通常依赖预训练检测器提取区域特征,或者先用 CNN 抽取稠密网格特征,再交给多模态模块做融合。这条路线虽然有效,但有两个结构性问题。
- 效率瓶颈明显:视觉特征提取往往远比后续图文交互更耗时。
- 表达空间受限:如果视觉侧依赖检测器,那么模型理解能力也会被检测器已有的类别词典限制。

从源稿中的对比数据可以看到,真正拖慢系统的不是模态交互,而是视觉嵌入阶段。
| 模型 | 视觉嵌入方式 | 视觉嵌入耗时 | 模态交互耗时 | 总计 |
|---|---|---|---|---|
| UNITER-Base | Faster R-CNN(Region) | ~810 ms | ~15 ms | ~900 ms |
| Pixel-BERT-R50 | ResNet(Grid) | ~45 ms | ~15 ms | ~60 ms |
| ViLT-B/32 | Linear Embedding(Patch) | ~0.4 ms | ~15 ms | ~15 ms |
这组数字对应的结论非常直接:如果视觉预处理本身已经占掉几乎全部时间,那么继续堆视觉侧复杂模块,并不一定是最优的系统设计。
核心判断:把图像也变成 token
ViLT 的核心贡献,可以压缩成一句话:文本是 token,图像也应该尽可能变成 token。
对文本,模型沿用 BERT 风格的嵌入方式;对图像,模型把输入切成固定大小的 patch,再通过线性层映射到统一隐藏维度。这样,图像 patch token 和文本 token 就能直接拼接,送入同一个 Transformer Encoder 做联合建模。
这一步带来的变化,不只是“把 CNN 换成 patch embedding”,而是改写了整条多模态流水线的计算结构:视觉前处理被大幅压缩,多模态交互第一次成为系统主角。
四类 VLP 架构怎么理解
源稿里最有价值的一部分,是它把视觉语言模型放进一条连续光谱里,而不是孤立看待 ViLT。
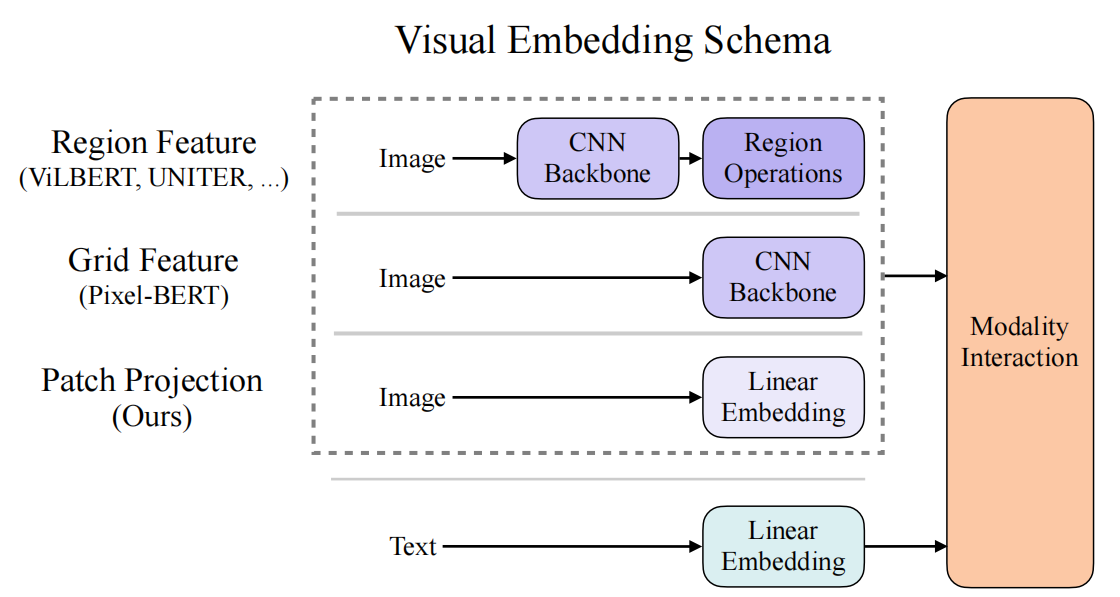
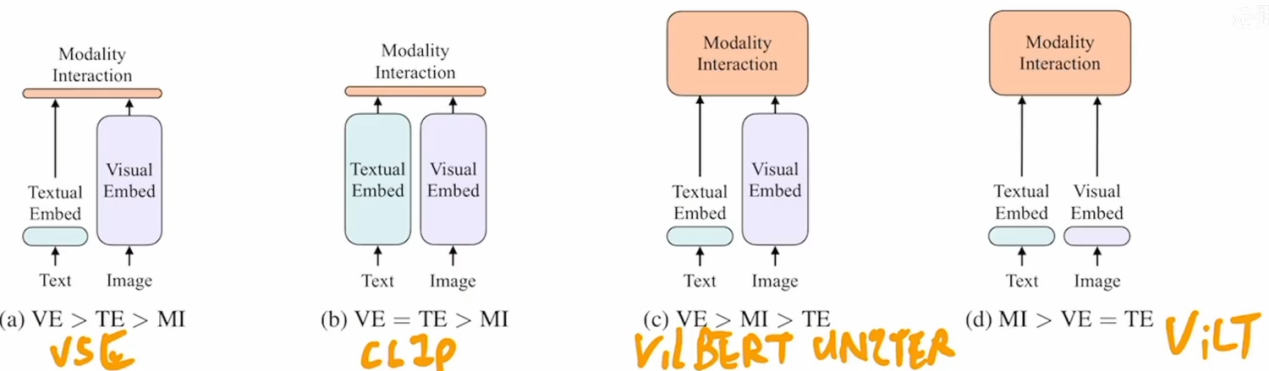
可以把这四类方法概括为下面这张表。
| 框架 | 代表模型 | 权重关系 | 特点 |
|---|---|---|---|
| VSE++ | VSE++ | VE > TE > MI | 主要在输出空间对齐,模态交互最弱 |
| CLIP | CLIP | VE = TE > MI | 双编码器独立训练,以对比目标完成对齐 |
| 重视觉编码路线 | ViLBERT、UNITER | VE > MI > TE | 视觉前处理重,但跨模态融合更深 |
| 极简单流路线 | ViLT | MI > VE = TE | 视觉编码极轻,把主要计算让给共享 Transformer |
这里可以顺手区分两个常见概念。
单流融合与双流融合
- 单流融合:图像 token 和文本 token 在输入阶段就拼接到同一序列里,由同一个 Transformer 统一建模。
- 双流融合:图像和文本先分别编码,再通过 cross-attention 或后续交互层完成融合。
ViLT 属于典型的单流融合。它不是先把图像和文本各自“理解完”再对齐,而是从一开始就让它们在同一序列空间里交互。
ViLT 的整体结构
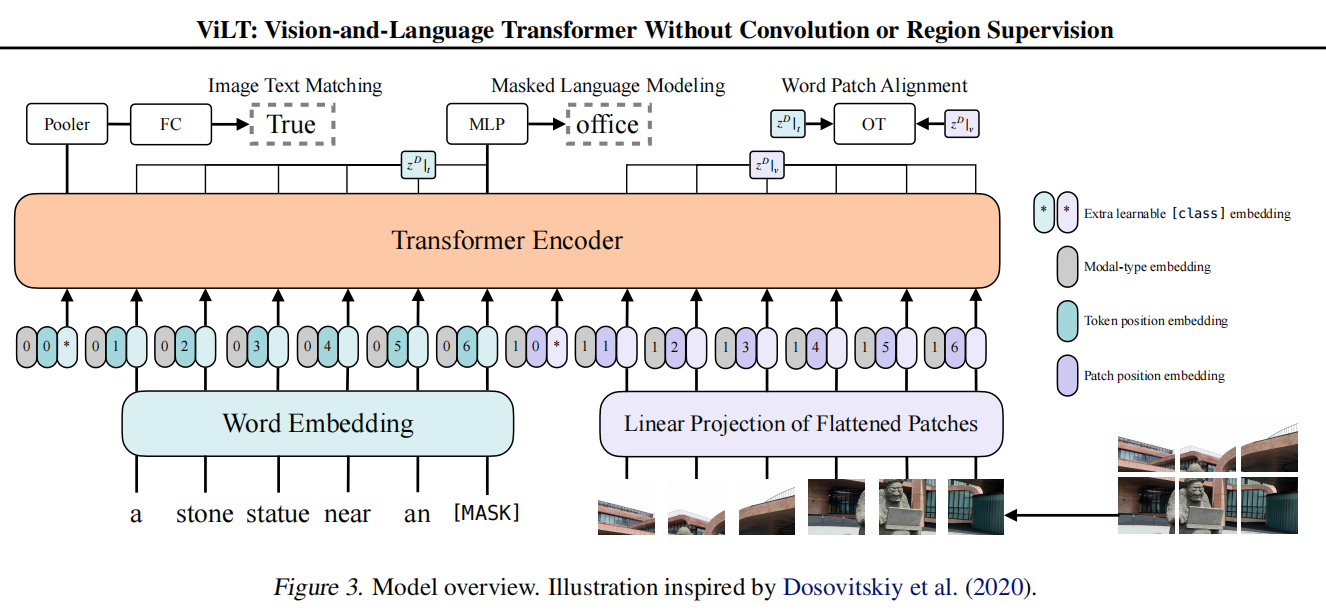
从结构上看,ViLT 很像把 ViT 的 patch token 思路直接迁移到了多模态场景:
- 图像切成 patch,并做线性投影;
- 文本做词嵌入;
- 两个模态都加入类型嵌入和位置嵌入;
- 拼接成统一序列后送入共享 Transformer;
- 用统一表示去支持 ITM、MLM 和 WPA 等目标。
输入嵌入
ViLT 中每个 token 的输入表示由三部分相加得到:
这里最关键的不是公式本身,而是图像与文本在表示层被尽量统一处理。文本有自己的 token 序列,图像也被离散化为 patch token;两个模态都能用同一种 Transformer 数据流去消费。
单流多模态交互
图像嵌入和文本嵌入分别加上各自的模态类型嵌入后,在序列维度直接拼接:
随后整个序列进入 层 Transformer Encoder 做联合建模。源稿中给出的 ViT 风格 pre-norm 结构如下:
最终,模型使用第一个文本 token 的输出作为池化表示:
这意味着 ViLT 的跨模态建模发生得很早,而且贯穿全层,而不是只在顶部做一次轻量对齐。
关键机制详解
Patch Projection:把视觉前处理压缩到最低
ViLT 最关键的简化,就是去掉 CNN 和区域检测器,直接把图像切成 patch 后做线性映射。
这一步继承了 ViT 的思想,但放到 VLP 里意义更大:它不是单纯替换一个模块,而是在系统层面砍掉了最昂贵的视觉预处理部分。与 region feature 或 grid feature 相比,Patch Projection 的优点是:
- 结构简单;
- 前向计算便宜;
- 不依赖外部检测器的类别体系;
- 更适合把算力留给真正的多模态交互。
预训练目标:不只做整体匹配
ViLT 使用三个核心目标:
| 目标 | 作用 | 直觉 |
|---|---|---|
| ITM | 判断图文是否匹配 | 学会全局层面的对应关系 |
| MLM | 恢复被遮蔽的文本 token | 利用图像上下文辅助语言理解 |
| WPA | 做词与 patch 的细粒度对齐 | 从整体相关进一步走向局部对应 |
其中,WPA 是很值得注意的设计。它说明 ViLT 不满足于“知道一张图和一句话是否匹配”,而是希望模型内部还能学习词和视觉区域之间更细粒度的对齐关系。
训练细节:高效不是单点技巧
源稿里还提到几条很容易被忽略、但实际上很关键的训练策略:
- 整词掩码:避免 MLM 只靠 subword 局部线索作弊。
- 图像增强:因为不再依赖预缓存区域特征,ViLT 可以自然地在训练过程中做增强。
- 较低输入分辨率:预训练和微调时采用更小图像尺寸,进一步压缩 patch 数量和计算量。
例如,对于 的输入,ViLT-B/32 只会产生 个 patch。这个数量与重视觉编码方案相比已经相当克制,也进一步解释了它的效率来源。
ViLT 的意义与边界
ViLT 传达出的最重要判断,不是“CNN 没用了”,而是:在视觉语言预训练里,过重的视觉编码器不一定总是必要条件。
只要共享 Transformer 足够有效,直接从 patch 开始做联合建模,也能拿到很有竞争力的结果。它的意义主要有三点:
- 证明了极简视觉前处理路线是可行的;
- 把多模态交互重新放回系统中心;
- 为后续高效多模态模型提供了方法论起点。
但这条路线也有明确边界。对于特别依赖细粒度局部结构的任务,纯 patch 表示未必总优于更强的视觉骨干网络。后续工作如 METER、BEiT-3,本质上都是在 ViLT 打开的“效率优先”方向上继续寻找更好的精度-效率平衡。
与 CLIP 的区别
源稿后半段有一段 CLIP 串讲,但如果放到 ViLT 正文里,更适合浓缩成一个边界说明,而不是单开专题。
| 维度 | ViLT | CLIP |
|---|---|---|
| 结构 | 单流共享 Transformer | 双塔编码器 |
| 交互位置 | 输入后立即开始深度交互 | 主要在表示空间做对齐 |
| 强项 | 细粒度图文理解、联合建模 | 检索、零样本分类、大规模对比学习 |
| 系统取向 | 减轻视觉前处理,增强融合 | 保持编码器解耦,扩大对比训练规模 |
所以,ViLT 和 CLIP 并不是简单的“谁更先进”。它们代表的是两条不同的系统设计路线:一个强调深交互,一个强调可扩展的双塔对齐。
代码实战
这篇文章对应的 notebook 采用了两条并行路线:一条是教学版 Mini-ViLT,用来解释结构和张量流;另一条是直接调用 Hugging Face 的预训练权重,做图文匹配推理。
![]()
下面这段代码展示了 ViLT 如何把图像 patch 直接变成 token 序列:
class PatchEmbedding(nn.Module):
def __init__(self, img_size: int, patch_size: int, d_model: int, in_channels: int = 3):
super().__init__()
self.num_patches = (img_size // patch_size) ** 2
self.proj = nn.Conv2d(in_channels, d_model, kernel_size=patch_size, stride=patch_size)
self.cls_token = nn.Parameter(torch.randn(1, 1, d_model))
self.pos_embed = nn.Parameter(torch.randn(1, 1 + self.num_patches, d_model))
def forward(self, x):
batch_size = x.shape[0]
x = self.proj(x)
x = x.flatten(2).transpose(1, 2)
cls = self.cls_token.expand(batch_size, -1, -1)
x = torch.cat([cls, x], dim=1)
x = x + self.pos_embed
return x如果切到工程实践,notebook 还展示了如何直接使用预训练检索模型进行图文匹配:
from transformers import ViltForImageAndTextRetrieval, ViltProcessor
model_name = 'dandelin/vilt-b32-finetuned-coco'
processor = ViltProcessor.from_pretrained(model_name)
model = ViltForImageAndTextRetrieval.from_pretrained(model_name)
model.eval()这两部分结合起来,既能帮助理解 ViLT 为什么快,也能帮助快速掌握一个今天仍然可运行的调用入口。
总结
ViLT 的真正贡献,不只是把视觉侧换成 patch embedding,而是重新定义了视觉语言预训练里的“主战场”。它证明了系统瓶颈未必在视觉编码器本身,而可能在于:我们把太多算力浪费在了交互发生之前。
从这个意义上说,ViLT 是一篇方法论价值很高的论文。它用极简设计挑战了当时“重视觉编码”的主流范式,也为后续一系列高效多模态模型提供了清晰起点。
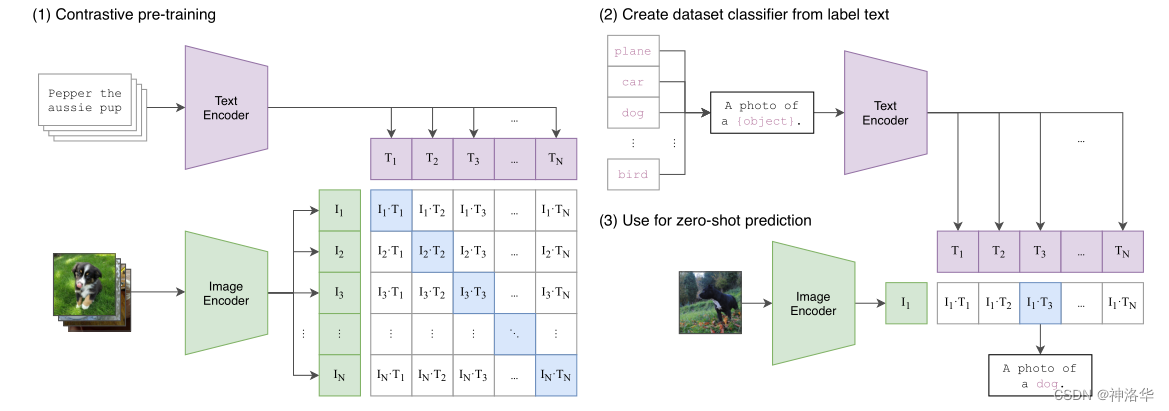
延伸阅读:为什么容易拿 ViLT 和 CLIP 对照
源稿里还引用了一张 CLIP 训练流程图。它不属于 ViLT 论文正文的一部分,但作为对照材料是有价值的:ViLT 代表的是单流深交互路线,而 CLIP 更代表双塔对比学习路线。把这张图留在文末更合适,不会打断 ViLT 主线,同时也能帮助读者建立方法谱系。
参考资料
- Wonjae Kim, Bokyung Son, Ildoo Kim. ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision. ICML 2021. arXiv
- PMLR Proceedings page: ViLT: Vision-and-Language Transformer Without Convolution or Region Supervision
- Hugging Face model card: dandelin/vilt-b32-finetuned-coco
- 原始源稿:
03_ViLT(简单,高效).md - 配套 notebook:
papers/ViLT/code.ipynb