An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale
Dosovitskiy et al. — ICLR 2021 (Google Research, Brain Team)
Vision Transformer(ViT)由 Google 于 2020 年提出,首次将 NLP 领域的 Transformer 架构直接应用于图像分类任务。其核心思想是将图像划分为固定大小的 Patch 序列,类比文本中的 Token,输入标准 Transformer Encoder 进行建模,在大规模数据预训练下取得了超越 CNN 的性能。这一工作证明了纯 Transformer 架构在视觉任务中的可行性,为后续 DeiT、Swin Transformer、MAE 等一系列视觉 Transformer 工作奠定了基础。
研究动机
Transformer 在 NLP 任务中大获成功(如 BERT 处理长度为 512 的序列),但直接将其迁移到视觉领域面临一个关键挑战:序列长度过大。以常见的 分辨率图像为例,如果将每个像素作为一个 Token,序列长度将达到 50176,远超 Transformer 的处理能力。目标检测、实例分割等任务的分辨率更高,问题更加严峻。
ViT 的核心创新在于:用 Patch 切分将图像转化为可控长度的序列,从而用标准 Transformer 替代 CNN 作为视觉主干网络。与 NLP 中常见的无监督预训练不同,ViT 采用有监督学习进行预训练。
模型架构
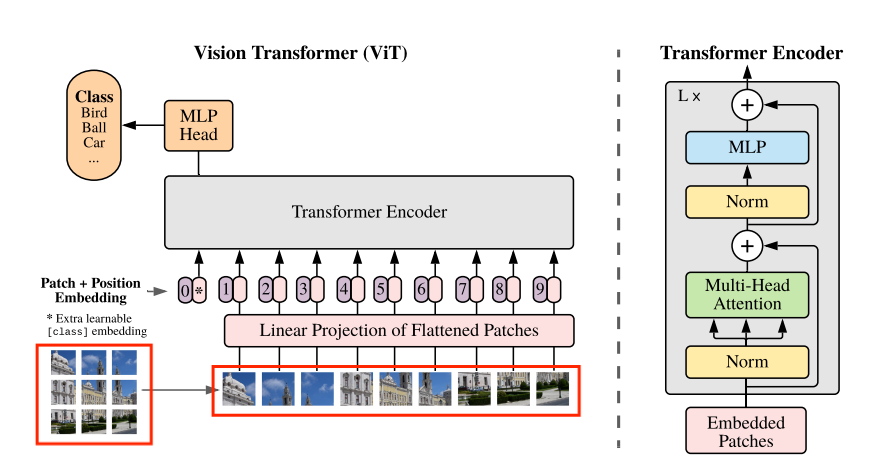
图像切分为 Patch
输入图像被均匀切分为固定大小的非重叠 Patch。以 的图像、 的 Patch 大小为例:
- Patch 数量: 个
- 每个 Patch 展平后的维度:
这样,一张图像被转化为长度为 196 的序列,每个元素是一个 768 维向量。
Patch Embedding
每个展平的 Patch 通过一个线性投影层(全连接层)映射为固定长度的嵌入向量。以 ViT-Base 为例,投影矩阵维度为 ,其中输入维度 768 由 Patch 展平大小决定,输出维度 768 为超参数设定。这一过程类似于 NLP 中的词嵌入(Word Embedding)。
位置编码(Position Embedding)
Transformer 的自注意力机制对序列中元素做两两交互,但本身不包含位置信息。由于图像 Patch 具有空间顺序,需要为每个 Patch Embedding 加上可学习的位置编码以保留空间结构。

ViT 论文探讨了三种位置编码策略:
- 1D 位置编码:将 Patch 按光栅顺序排列,每个位置分配一个长度为 的可学习向量。这是 ViT 的默认方案。
- 2D 位置编码:分别学习 X 轴和 Y 轴方向的编码,各自长度为 ,拼接后仍为长度 。序列数量从 变为 (每个轴方向)。
- 相对位置编码:基于 Patch 之间的相对距离编码空间信息。
实验结果表明三种方案性能接近,1D 编码已能隐式学到 2D 的空间结构信息。
CLS Token
借鉴 BERT 的设计,ViT 在 Patch 序列前拼接一个可学习的 CLS Token(维度为 ),用于聚合全局图像特征并完成最终分类。
因此,Transformer Encoder 的输入维度为 (196 个 Patch + 1 个 CLS Token),整个输入 = Patch Embedding + CLS Token + Position Embedding(逐元素相加)。
Transformer Encoder
ViT 直接采用标准 Transformer Encoder 结构,由 层堆叠而成,每层包含:
- Layer Norm + 多头自注意力(Multi-Head Self-Attention, MSA)+ 残差连接
- Layer Norm + 前馈网络(MLP,含 GELU 激活)+ 残差连接
数学表示如下:
其中 为 Patch 大小, 为通道数, 为嵌入维度, 为 Patch 数量, 为 Encoder 层数。最终取 (即 CLS Token 的输出)作为图像的全局表示。
分类头(Classification Head)
Transformer Encoder 输出的 CLS Token 向量经过一个 MLP 分类头,输出最终的类别概率。预训练时使用一个隐藏层的 MLP,微调时替换为单层线性层。
混合模型(Hybrid Architecture)
ViT 还提出了一种混合架构:
- 先用 CNN(如 ResNet)提取特征图
- 将特征图切分为 Patch 序列
- 对特征 Patch 进行线性投影(若 CNN 输出通道数已匹配 Transformer 维度则可省略)
- 添加位置编码和 CLS Token 后输入 Transformer Encoder
微调与高分辨率处理
ViT 采用典型的预训练-微调范式:先在大规模数据集上预训练,再迁移到下游任务。微调时:
- 移除预训练的分类头
- 添加新的全连接层(, 为下游任务类别数),使用零初始化
微调时通常使用比预训练更高的分辨率以提升性能。由于 Patch 大小保持不变,更高分辨率意味着更多的 Patch、更长的序列。Transformer 本身可处理任意长度序列(受内存限制),但预训练的位置编码需要调整。
解决方案:对预训练的位置编码进行 2D 插值,根据 Patch 在原始图像中的位置进行空间插值。
实验分析
数据规模的影响
数据集规模对 ViT 性能影响显著。在小规模数据集(如 ImageNet)上训练时,ViT 不如同等大小的 ResNet,这表明 Transformer 缺乏 CNN 内置的归纳偏置(如局部性和平移不变性)。但随着数据量增加到 JFT-300M,ViT 性能优势逐渐显现并超越 CNN,说明大规模数据能弥补归纳偏置的缺失。
迁移学习能力
在 19 个下游分类任务中,ViT 平均比基于 ResNet 的 BiT 模型高出 2.7% 的准确率,在 CIFAR-10/100、Oxford Flowers 等数据集上表现尤为突出,展现了优秀的泛化能力。
计算效率
与达到相同性能的 EfficientNet 相比,ViT 所需训练计算资源显著更少,在 TPU 上训练速度快 2.5 倍以上,得益于 Transformer 架构的高度并行性。
可视化分析
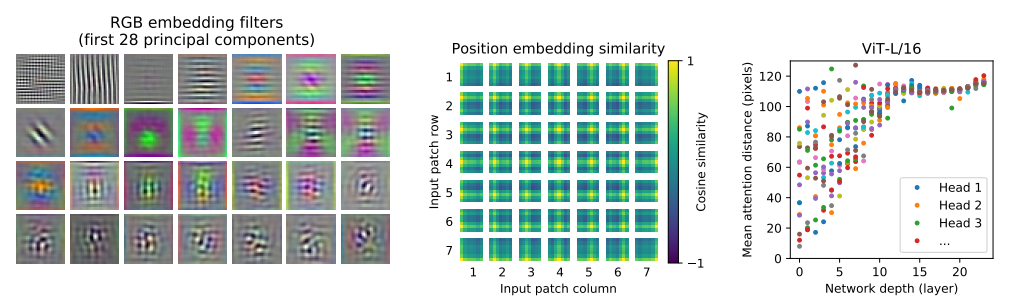
上图展示了三个关键发现:
- 线性投影滤波器(左):类似 CNN 低层的 Gabor 滤波器,说明模型学到了基础视觉特征
- 位置编码相似度(中):相邻位置的编码更相似,呈现明显的 2D 空间结构
- 注意力距离(右):浅层注意力头关注局部特征(短距离),深层捕捉全局信息(长距离),类似 CNN 的层次特征提取
消融实验要点
| 实验项目 | 结论 |
|---|---|
| 位置编码 | 1D、2D 和相对位置编码效果接近,1D 已能隐式学到 2D 信息 |
| Patch 大小 | 较小 Patch(如 )效果更好,但计算开销更大 |
| 注意力机制 | 浅层关注局部,深层关注全局,无需显式局部性偏置 |
总结
ViT 证明了纯 Transformer 架构在视觉任务中的可行性:当预训练数据充足时,无需卷积操作即可取得卓越的图像分类性能,同时保持更高的计算效率和更强的可扩展性。这一工作为视觉领域的预训练-微调范式开辟了新的方向。
代码实战
完整的 ViT 代码实现(CIFAR-10 图像分类),包含源代码实现与 nn.TransformerEncoder 简洁实现两种方式的对比:
![]()
本节展示 ViT 的 PyTorch 实现,包含源代码实现(逐组件手写)和简洁实现(使用 PyTorch 内置模块)两种方式,均在 CIFAR-10 子集上训练验证。
Patch Embedding
将输入图像切分为不重叠的 Patch,通过线性投影映射到 维空间:
class PatchEmbeddingScratch(nn.Module):
"""将图像切分为 Patch 并线性投影"""
def __init__(self, img_size, patch_size, in_channels, d_model):
super().__init__()
self.patch_size = patch_size
self.num_patches = (img_size // patch_size) ** 2
patch_dim = patch_size * patch_size * in_channels
self.proj = nn.Linear(patch_dim, d_model)
def forward(self, x):
B, C, H, W = x.shape
p = self.patch_size
x = x.reshape(B, C, H // p, p, W // p, p)
x = x.permute(0, 2, 4, 3, 5, 1)
x = x.reshape(B, self.num_patches, -1)
x = self.proj(x)
return x多头自注意力
class MultiHeadAttention(nn.Module):
"""多头自注意力(手写实现)"""
def __init__(self, d_model, num_heads, dropout=0.0):
super().__init__()
self.num_heads = num_heads
self.head_dim = d_model // num_heads
self.scale = self.head_dim ** -0.5
self.qkv = nn.Linear(d_model, d_model * 3)
self.proj = nn.Linear(d_model, d_model)
self.attn_drop = nn.Dropout(dropout)
self.proj_drop = nn.Dropout(dropout)
def forward(self, x):
B, N, D = x.shape
h = self.num_heads
qkv = self.qkv(x).reshape(B, N, 3, h, self.head_dim)
qkv = qkv.permute(2, 0, 3, 1, 4)
q, k, v = qkv.unbind(0)
attn = (q @ k.transpose(-2, -1)) * self.scale
attn = attn.softmax(dim=-1)
attn = self.attn_drop(attn)
out = (attn @ v).transpose(1, 2).reshape(B, N, D)
out = self.proj_drop(self.proj(out))
return outTransformer Encoder Block(Pre-LN)
ViT 使用 Pre-LN 变体,LayerNorm 在子层之前:
class TransformerBlock(nn.Module):
"""Transformer Encoder Block(Pre-LN 变体)"""
def __init__(self, d_model, num_heads, d_ff, dropout=0.1):
super().__init__()
self.norm1 = nn.LayerNorm(d_model)
self.attn = MultiHeadAttention(d_model, num_heads, dropout)
self.norm2 = nn.LayerNorm(d_model)
self.mlp = nn.Sequential(
nn.Linear(d_model, d_ff),
nn.GELU(),
nn.Dropout(dropout),
nn.Linear(d_ff, d_model),
nn.Dropout(dropout),
)
def forward(self, x):
x = self.attn(self.norm1(x)) + x
x = self.mlp(self.norm2(x)) + x
return x完整 ViT 模型
组装所有组件:Patch Embedding、CLS Token、Position Embedding、Transformer Encoder、分类头。
class ViTScratch(nn.Module):
"""Vision Transformer 源代码实现"""
def __init__(self, img_size, patch_size, in_channels, d_model,
num_heads, num_layers, d_ff, num_classes, dropout=0.1):
super().__init__()
self.patch_embed = PatchEmbeddingScratch(
img_size, patch_size, in_channels, d_model
)
num_patches = self.patch_embed.num_patches
self.cls_token = nn.Parameter(torch.zeros(1, 1, d_model))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, d_model))
self.pos_drop = nn.Dropout(dropout)
self.blocks = nn.ModuleList([
TransformerBlock(d_model, num_heads, d_ff, dropout)
for _ in range(num_layers)
])
self.norm = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, num_classes)
nn.init.trunc_normal_(self.cls_token, std=0.02)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x)
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1)
x = self.pos_drop(x + self.pos_embed)
for block in self.blocks:
x = block(x)
cls_out = self.norm(x[:, 0])
logits = self.head(cls_out)
return logits简洁实现
使用 nn.Conv2d 实现 Patch Embedding,nn.TransformerEncoder 封装 Encoder 层:
class ViTConcise(nn.Module):
"""Vision Transformer 简洁实现"""
def __init__(self, img_size, patch_size, in_channels, d_model,
num_heads, num_layers, d_ff, num_classes, dropout=0.1):
super().__init__()
num_patches = (img_size // patch_size) ** 2
self.patch_embed = nn.Conv2d(
in_channels, d_model,
kernel_size=patch_size, stride=patch_size
)
self.cls_token = nn.Parameter(torch.zeros(1, 1, d_model))
self.pos_embed = nn.Parameter(torch.zeros(1, num_patches + 1, d_model))
self.pos_drop = nn.Dropout(dropout)
encoder_layer = nn.TransformerEncoderLayer(
d_model=d_model, nhead=num_heads, dim_feedforward=d_ff,
dropout=dropout, activation='gelu', batch_first=True,
norm_first=True
)
self.encoder = nn.TransformerEncoder(
encoder_layer, num_layers=num_layers
)
self.norm = nn.LayerNorm(d_model)
self.head = nn.Linear(d_model, num_classes)
nn.init.trunc_normal_(self.cls_token, std=0.02)
nn.init.trunc_normal_(self.pos_embed, std=0.02)
def forward(self, x):
B = x.shape[0]
x = self.patch_embed(x).flatten(2).transpose(1, 2)
cls = self.cls_token.expand(B, -1, -1)
x = torch.cat([cls, x], dim=1)
x = self.pos_drop(x + self.pos_embed)
x = self.encoder(x)
cls_out = self.norm(x[:, 0])
logits = self.head(cls_out)
return logits两种实现架构等价(参数量均为 142,026),在 CIFAR-10 子集上训练 50 个 epoch 后测试准确率约 50%。准确率较低是因为使用了极小的模型(,4 层)和少量数据(5000 样本),仅用于演示 ViT 的工作原理。
预训练模型微调
使用 ImageNet 预训练的 ViT-B/16(86M 参数),冻结主干网络仅训练分类头(7,690 参数),在 CIFAR-10 上 3 个 epoch 即可达到 87% 测试准确率,充分体现了预训练-微调范式的价值。
参考文献
- Dosovitskiy, A., et al. (2020). An Image is Worth 16x16 Words: Transformers for Image Recognition at Scale. ICLR 2021.
- 李沐. ViT 论文逐段精读. Bilibili.