YOLOv2 由 Joseph Redmon 与 Ali Farhadi 于 2016 年提出,论文标题中的 Better、Faster、Stronger 几乎可以直接看作这篇工作的结构提纲。与 YOLOv1 那种“重新定义检测问题”的开创性不同,YOLOv2 更像一次非常明确的系统升级:它不再试图证明 one-stage detector 这条路线是否成立,而是集中回答另一个更实际的问题——既然统一回归已经被证明可行,怎样才能把这条路线真正做得更准、更快,也更像一个成熟的检测系统。
从今天回看,YOLOv2 的价值不只是一次版本迭代,而在于它第一次系统性地补齐了 YOLOv1 暴露出的关键短板:用 anchor 改善边界框建模,用聚类让先验框贴近数据分布,用多尺度训练提升输入分辨率适应性,用更轻更强的 backbone 继续压缩推理成本,并最终把检测能力扩展到 YOLO9000 的大类别体系。很多后来 one-stage detector 中被视为标准配置的设计,在 YOLOv2 这里都已经出现了清晰原型。

问题背景与方法动机
YOLOv1 的历史意义很大,但它也暴露出几个非常具体的问题:
- 定位方式偏粗:直接回归边界框,在训练初期不够稳定;
- 召回率偏低:候选框表达能力有限,容易漏掉目标;
- 小目标不友好:特征图分辨率较低,细节信息损失明显;
- 输入尺度适应性弱:训练和推理阶段的分辨率切换比较生硬;
- 类别扩展能力有限:检测器高度依赖带框标注数据,难以快速扩到大量类别。
YOLOv2 的关键判断是:YOLOv1 的问题并不意味着 one-stage 路线不成立,而是说明第一代实现还不够成熟。因此它没有推翻 YOLOv1,而是围绕框表示、网络结构、训练策略和类别体系做系统升级。
下面这张表可以快速理解 YOLOv2 相比 YOLOv1 的改动重心:
| 维度 | YOLOv1 | YOLOv2 |
|---|---|---|
| 边界框建模 | 直接回归 | Anchor boxes + 偏移预测 |
| 先验框设计 | 无 | K-means 聚类生成 |
| 中心点预测 | 无显式约束 | Sigmoid 约束在当前 cell 内 |
| 骨干网络 | 较重的分类骨干 | 更轻的 Darknet-19 |
| 尺度适应 | 相对固定 | 多尺度训练 |
| 小目标支持 | 较弱 | Passthrough 融合浅层特征 |
| 类别扩展 | 常规检测类别 | WordTree + 联合训练到 9000+ 类 |
YOLOv2 的整体思路
YOLOv2 的改进通常被概括为三个关键词:Better、Faster、Stronger。这三个词并不是宣传口号,而是对论文结构的直接概括。
- Better:提升检测精度与召回率,核心包括 BN、高分辨率分类器、anchor、维度聚类、直接位置预测、Passthrough;
- Faster:用更轻量的 Darknet-19 作为 backbone,在保持精度的同时降低计算成本;
- Stronger:通过 WordTree 和分类/检测联合训练,把检测器扩展到更大的类别空间,形成 YOLO9000。
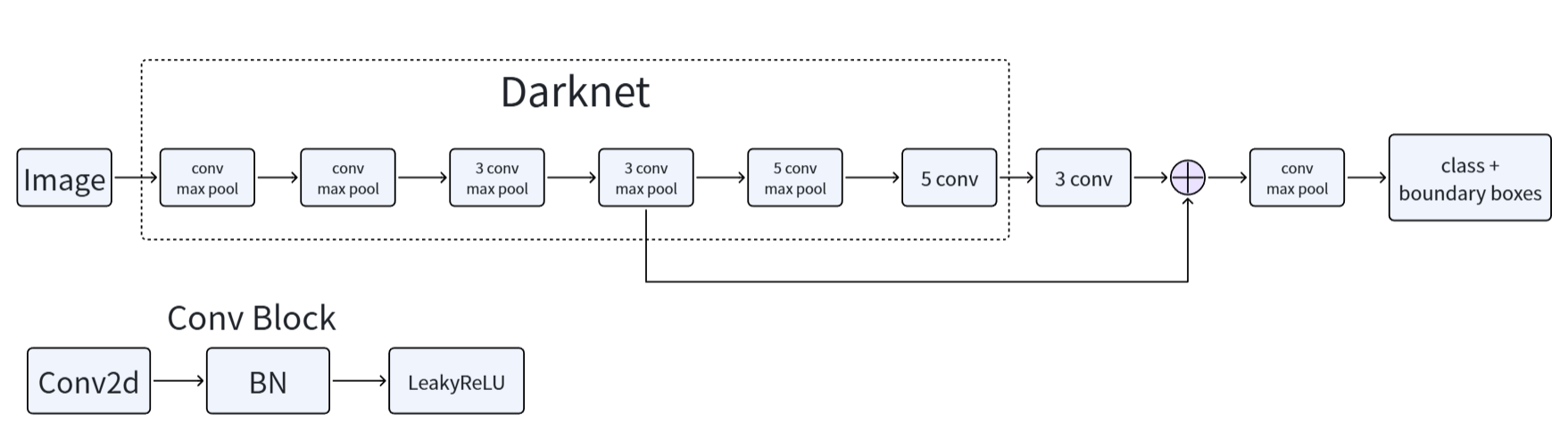
这张图可以把 YOLOv2 的主体拆成三部分来看:前半段是 Darknet 主干网络,负责逐步下采样并提取语义特征;中间的跨层连接是 Passthrough,把较浅层的高分辨率特征重排后送到后面的检测分支;最后的检测头则同时输出类别与边界框。也就是说,YOLOv2 并不是“只有一个 backbone”,而是把主干特征、跨层融合和最终预测头明确串成了一条端到端检测路径。
如果把 YOLOv1 到 YOLOv2 看成一次方法论升级,那么它本质上做了两件事:
- 把边界框预测从“直接回归”改造成“基于先验框的稳定优化问题”;
- 把检测器从单一数据集上的模型,推进成一个可联合分类数据继续扩张的体系。
Better:检测效果为什么变好了
批量归一化带来的训练稳定性
YOLOv2 在每个卷积层后都加入了 Batch Normalization。这个改动看起来普通,但非常关键,因为它直接改善了训练稳定性,并降低了对 Dropout 的依赖。
BN 的核心形式可以写成:
再通过可学习参数恢复表达能力:
直观理解就是:先把中间层激活分布拉回一个更稳定的范围,再允许网络自己学会应该放大或平移到哪里。对于目标检测这种训练目标本就比较复杂的任务,这能明显减轻优化难度。

高分辨率分类器:先适应高分辨率,再做检测
YOLOv1 在分类阶段使用较低分辨率输入,而检测阶段直接切到更高分辨率,这会带来比较明显的分布跳变。YOLOv2 的做法更自然:先把分类网络在更高分辨率上继续微调,再迁移到检测任务。
这个改动背后的逻辑很简单:不要让模型在切换任务时,同时还要适应完全不同的输入尺度。先把“看高清图”这件事学会,再去学检测,优化过程会更平滑。
引入 Anchor Boxes:先把几个容易混淆的概念分开
在这一部分里,最容易混淆的其实不是公式,而是 bounding box、anchor box、prior box、proposal 和 RPN。它们彼此相关,但含义、生成方式和所在阶段并不一样。
| 概念 | 它是什么 | 是否预先定义 | 是否由网络筛选/生成 | 是否更接近真实目标 | 是否最终输出 | 在 YOLOv2 / Faster R-CNN 中的位置 |
|---|---|---|---|---|---|---|
| Bounding box | 描述目标位置与大小的矩形框;可以指真实标注框,也可以指模型预测框 | 真实框是,预测框否 | 预测框是 | 预测框通常是 | 预测框是 | YOLOv2 和 Faster R-CNN 最终都要输出它 |
| Anchor box | 放在特征图每个位置上的参考框模板;本质是按预设尺度与长宽比在各位置平铺出来的参考框 | 是 | 否 | 不一定 | 否 | YOLOv2 检测头与 Faster R-CNN 的 RPN 都可把它作为回归起点 |
| Prior box | 与 anchor box 本质相近,都是预定义参考框;prior box 这个叫法在 SSD 中更常见 | 是 | 否 | 不一定 | 否 | 在 YOLOv2 语境里基本可以近似理解为 anchor box |
| Proposal / region proposal | 模型认为“这里可能有目标”的候选区域,是从大量参考框出发经打分、回归和筛选后留下的框 | 否 | 是 | 是,通常比 anchor 更接近目标 | 否,通常还是中间结果 | Faster R-CNN 有明确 proposal 阶段;YOLOv2 通常没有独立 proposal 阶段 |
| RPN | Region Proposal Network,两阶段检测器里专门生成 proposals 的网络模块 | 不适用 | 它本身负责生成 | 生成的 proposal 会更接近目标 | 否 | 属于 Faster R-CNN 这类 two-stage 方法,YOLOv2 不使用它 |
把关系压缩成一句话就是:真实 bounding box 提供监督,anchor box / prior box 提供起点,网络学习偏移量与置信度后得到更接近目标的框;在 Faster R-CNN 里这些中间结果会形成 proposal,而在 YOLOv2 里通常直接朝最终预测 bounding box 输出。
如果按顺序理解,两类方法都可以从“先有参考框,再由网络预测偏移与分数”开始,但中间过程并不一样:
- Faster R-CNN:特征图 → anchor → RPN 预测前景分数和偏移 → proposal → 二阶段分类与精修 → 最终框;
- YOLOv2:特征图 → anchor / prior → 直接预测偏移、置信度、类别 → 解码 + NMS → 最终框。
从实现细节上说,anchor-based 检测器通常会让每个 anchor 都输出一个框偏移和一个分数;这些预测在解码后会产生大量彼此重叠的框,因此还需要经过阈值筛选与 NMS 去掉重复结果,最后才得到更干净的候选框或最终检测框。
这里还需要顺手区分一个非常容易混淆的概念:confidence 和 IoU 不是一回事。
| 概念 | 它回答的问题 | 来源 | 主要用途 |
|---|---|---|---|
| Confidence / 置信度 | “这个框里有没有目标,且预测值有多可信?” | 模型输出分数 | 用于阈值筛选、排序、NMS 前保留高分框 |
| IoU | “这个框和另一个框到底重叠得有多好?” | 两个框几何关系的计算结果 | 用于 anchor 匹配、聚类距离、评估定位质量、NMS 去重 |
可以把它们记成:confidence 更像‘主观打分’,IoU 更像‘客观重叠度量’。前者来自网络预测,后者来自框与框之间的几何计算。比如在 NMS 里,通常会先看 confidence 保留高分框,再用 IoU 判断两个框是否重叠过多;而在训练或评估时,IoU 则常被用来判断预测框是否足够接近真实框。
YOLOv2 最重要的结构性变化,就是引入 anchor boxes。它不再像 YOLOv1 那样直接输出最终框坐标,而是改为相对于先验框预测偏移量。这使得模型不必从零学习各种尺度和纵横比的边界框,而是在已有模板附近做调整。
这里还要把一个容易误解的点说清楚:anchor 不是像 proposal 那样由网络先“看图再算出来”的中间结果,而是先按规则构造好的参考框。 更准确地说,它的构建方式是“预设 + 平铺”:先定义一组尺度与长宽比模板,再在特征图每个位置以该点为中心放置这些模板框。若特征图大小为 、每个位置放 个 anchor,那么总 anchor 数量就是 。
从几何上看,如果已知某组模板的尺度 与宽高比 ,则可以把对应参考框宽高写成:
这也是为什么在同一个位置上,可以同时放一个近似正方形框、一个偏宽框和一个偏高框:它们共享中心点,但宽高模板不同。Faster R-CNN 常用手工设定的 scale + ratio 组合来生成这些 anchor;YOLOv2 则更强调先用 K-means 从数据里得到一组更贴近真实框分布的典型尺寸,然后再把这些预定义尺寸平铺到各个网格位置上使用。换句话说,网络真正学习的不是“先发明一个框”,而是“给已经放好的参考框打分,并预测它该往哪里偏移”。
这一步带来两个直接收益:
- 召回率提高:候选框覆盖能力更强;
- 优化更容易:网络学习的是“修正量”,而不是完全无约束的绝对坐标。
进一步说,YOLOv2 和 RPN 系方法虽然都用了 anchor,但流程并不一样:RPN 先基于 anchor 生成 proposals,再交给第二阶段分类与精修;YOLOv2 则直接在检测头上完成分类与框回归,一次前向传播就输出最终结果。这也是 one-stage 与 two-stage 在推理路径上的关键区别。
同时,YOLOv2 去掉了 YOLOv1 尾部的全连接预测,改成全卷积检测头。这不只是实现细节变化,而是让模型从结构上更适合密集预测,也为后续多尺度训练创造了条件。
维度聚类:让先验框来自数据,而不是手工猜
有了 anchor 之后,新的问题变成:先验框大小该怎么选?YOLOv2 的答案是,不靠经验拍脑袋,而是直接对训练集中的真实框做 K-means 聚类。
论文使用的距离不是普通欧式距离,而是:
这样做的原因很明确:目标检测真正关心的是重叠程度,而不是宽和高在数值上的直线距离。如果直接用欧式距离,大框会天然主导聚类结果;改成 IoU 距离后,聚类中心会更符合检测任务本身的目标。
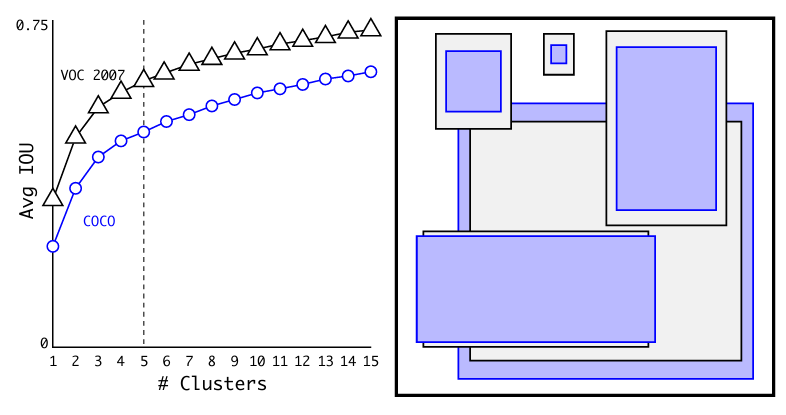
从方法论上看,这一步非常重要,因为它代表 YOLO 系列开始把“模型超参数”改造成“数据驱动的设计结果”。
直接位置预测:为什么要限制中心点偏移
仅仅引入 anchor 还不够。若中心点偏移完全不受约束,训练初期预测框很容易大幅漂移,导致优化不稳定。YOLOv2 对中心点预测使用了 Sigmoid 约束,使预测中心落在当前 grid cell 内。
如果记 cell 左上角偏移为 ,网络原始输出为 ,则中心坐标形式为:
宽高则通过 anchor 尺寸进行指数缩放:
其中 是 anchor box 的宽高, 才是最终解码后的预测 bounding box。也就是说,网络真正学习的是“让参考框往哪里平移、放大和缩小”。
这里最核心的不是公式本身,而是这个约束背后的优化思想:把预测空间限制在更合理的范围内,让网络先学会稳定地在局部修正,再逐步提升定位质量。
Passthrough:把浅层细节重新接回来
YOLOv2 仍然面临 one-stage 检测器的老问题:深层特征语义强,但分辨率低;浅层特征分辨率高,但语义弱。为了解决小目标信息不足的问题,YOLOv2 引入了 Passthrough 层,把较浅层的高分辨率特征通过 space-to-depth 方式重排后,与深层特征拼接。
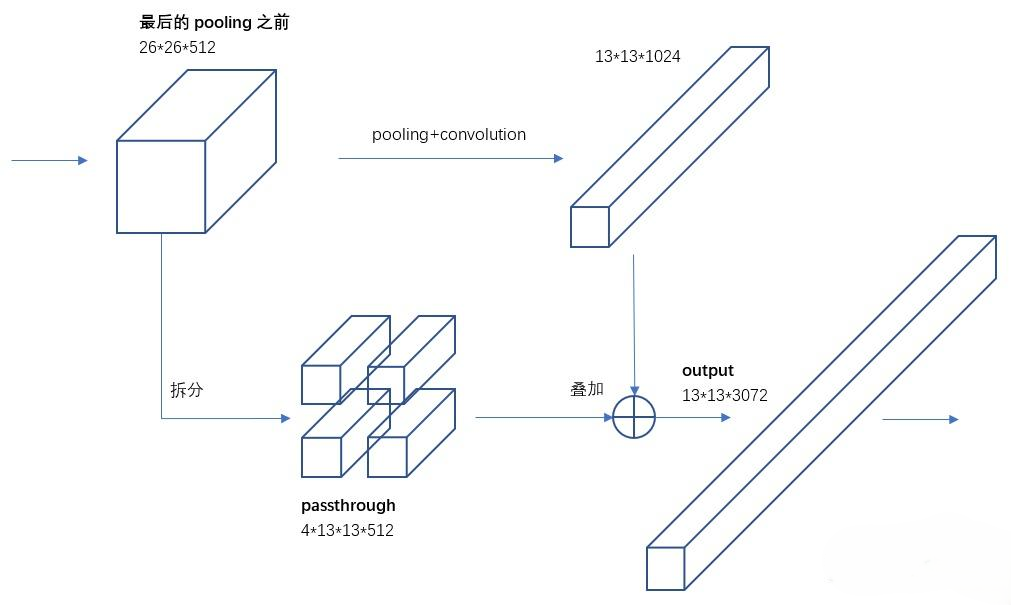
这一步的核心价值是:让最终检测头同时看到更强语义和更细局部信息。从后来的 FPN、PAN 等结构回看,YOLOv2 这里已经很清楚地体现出“跨层特征融合”这条思路。
Faster:为什么它还能更快
YOLOv2 并不是靠堆大模型换精度。相反,它的另一个重要方向是把 backbone 做得更高效。
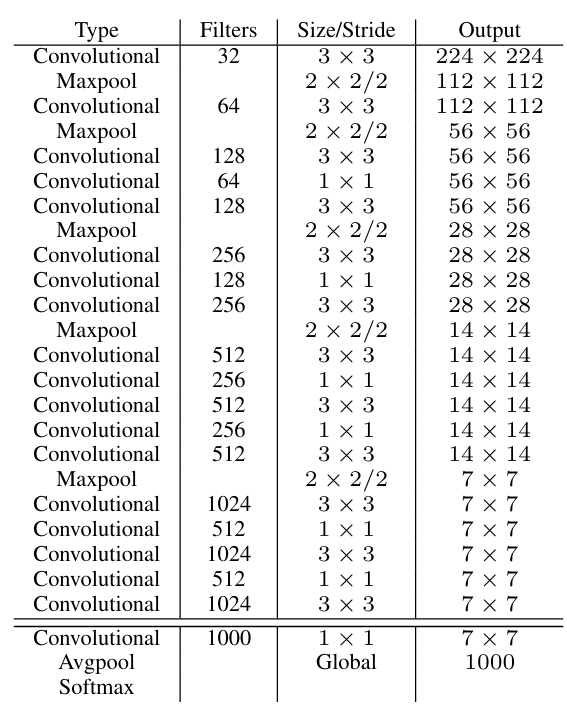
Darknet-19 的角色
YOLOv2 使用 Darknet-19 作为主干网络。它的设计思路很直接:
- 使用大量 卷积提取空间特征;
- 通过 卷积做通道压缩;
- 整体层数与计算量都比传统大骨干更轻;
- 全程配合 BN,使训练和推理都更加干净直接。

如果按空间分辨率看,Darknet-19 大致沿着 224 → 112 → 56 → 28 → 14 → 7 逐步下采样,并在各个 stage 内交替使用 1 × 1 与 3 × 3 卷积:前者负责压缩通道、控制计算量,后者负责提取空间模式。这样设计的结果不是单纯“层数更多”,而是在保持 backbone 足够轻的同时,仍然能给检测头提供可用的高层语义特征。
YOLOv2 的速度优势,本质上来自两个来源:
- 单阶段检测本身减少了复杂流水线开销;
- Darknet-19 让特征提取阶段的 FLOPs 和参数量都保持在可控范围。
也就是说,YOLOv2 的“快”不是某一个 trick 带来的,而是检测头、特征提取和训练策略共同压缩了系统成本。
多尺度训练:一个模型适应多种输入尺寸
YOLOv2 还引入了多尺度训练。训练过程中,输入尺寸会周期性变化,例如在若干个 32 倍数分辨率之间切换。因为整个检测器已经是全卷积结构,所以模型天然支持不同输入大小。
这带来的意义不是单纯“训练更复杂”,而是让模型在部署时拥有更灵活的速度-精度权衡:
- 小分辨率输入更快,适合实时场景;
- 大分辨率输入更准,适合更重视检测效果的场景。
这使 YOLOv2 从一个固定配置的检测器,变成了一个可以按需求切换工作点的系统。
与同期检测器的速度/精度位置
YOLOv2 的工程价值,在于它把“实时”与“可接受的精度”放到了一个更实用的平衡点上。它不是同期最极致的高精度模型,但在速度和精度的组合上很有竞争力。

如果说两阶段方法更像“尽量把每一步都做精”,那么 YOLOv2 更像“接受一定建模近似,但把整体系统做得足够快且足够好”。这也是它后来持续影响工业界实时检测路线的原因。
Stronger:YOLO9000 为什么能扩到 9000+ 类
联合训练的基本想法
传统检测器高度依赖带边界框标注的数据,而这类数据集的类别数通常不大。分类数据集则恰好相反:类别非常多,但没有框。YOLOv2 提出的 YOLO9000 试图把这两类监督信号结合起来。
思路是:
- 在检测数据上学习“哪里有物体”和“框该怎么回归”;
- 在分类数据上学习“更细粒度的类别语义”;
- 再通过统一类别体系把两者拼起来。
这样一来,模型即使没有见过某些类别的检测框标注,也可能借助分类数据对这些类别形成一定识别能力。
WordTree:把扁平分类改成层次化分类
为了统一 COCO、ImageNet 等不同来源的数据标签,论文构建了 WordTree。它基于 WordNet 的层级关系,把类别组织成树状结构,而不是扁平的单层 softmax 分类。
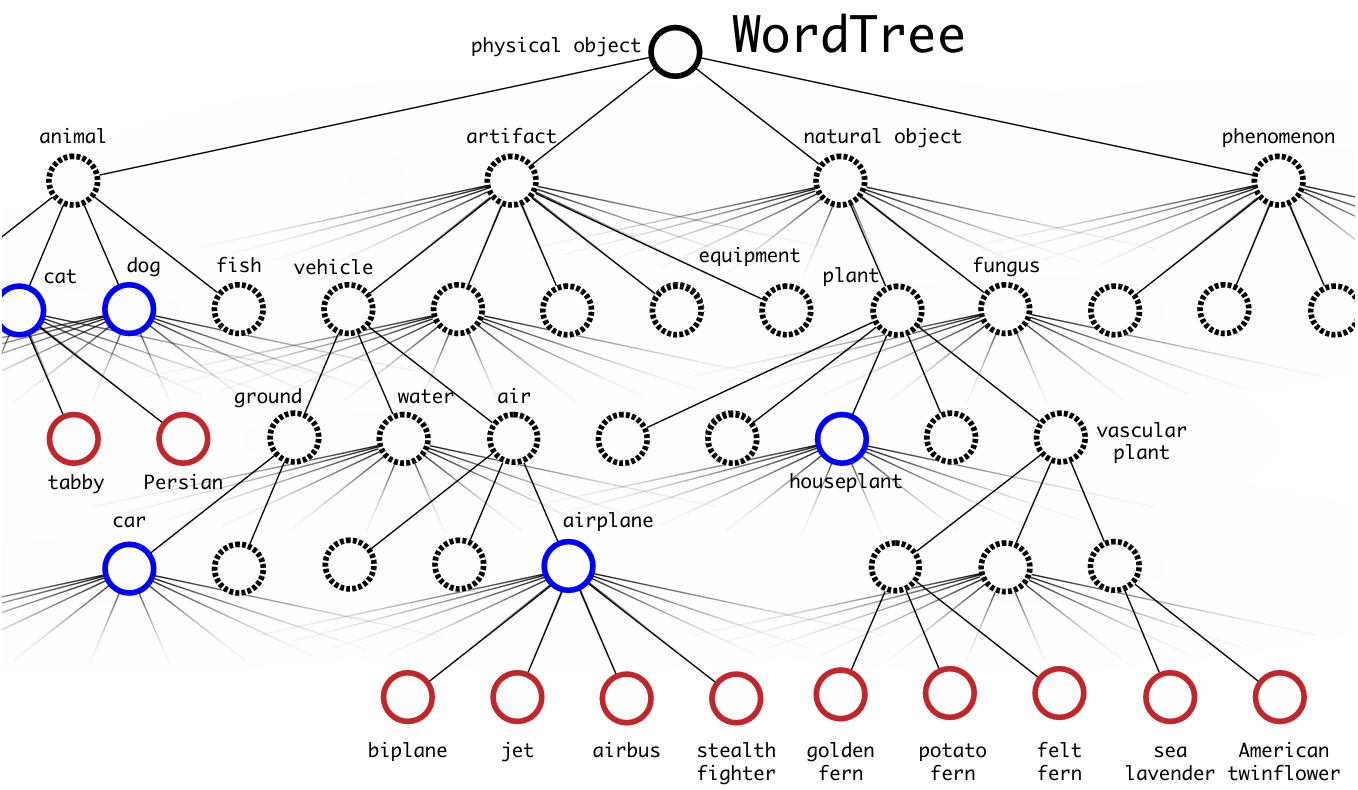
在这种表示里,模型预测的不是“一次性直接猜最终叶子类”,而是逐层预测条件概率。若某个类别路径为根节点 狗 猎犬 金毛猎犬,那么叶子类别概率可以写成路径上条件概率的连乘:
这种设计的意义在于:即使模型没把细粒度类别认得足够准,它也仍然可以在上层语义上给出合理判断。换句话说,预测错误不一定是完全错误,而可能只是“层级不够细”。这对大规模类别扩展非常重要。
训练目标与损失函数的变化
引入 anchor 之后,YOLOv2 的损失函数也和 YOLOv1 不再一样。它不再是单纯对固定数量框做直接坐标回归,而是围绕 anchor 匹配关系,分别优化:
- 位置误差:预测框相对 anchor 的偏移;
- 目标置信度:该 anchor 是否负责一个真实目标;
- 类别预测:在有目标条件下的类别概率。

从结构上看,YOLOv2 的损失设计比 YOLOv1 更接近后来主流 anchor-based detector 的训练方式。它最重要的改进不是某个系数调得更好,而是整个预测对象已经从“直接输出框”变成“围绕 anchor 做匹配和修正”。
YOLOv2 的优势、局限与历史位置
优势
| 优势 | 说明 |
|---|---|
| 召回率更高 | anchor + 聚类先验框显著提升候选框覆盖能力 |
| 训练更稳定 | BN 和直接位置预测降低训练初期发散风险 |
| 更灵活 | 多尺度训练让一个模型可适配多种输入分辨率 |
| 小目标更友好 | Passthrough 融合浅层高分辨率特征 |
| 可扩展性更强 | WordTree 和联合训练让检测类别空间大幅扩张 |
局限
| 局限 | 根源 |
|---|---|
| 对密集场景仍有限制 | 单阶段密集预测在复杂遮挡下仍较吃力 |
| anchor 机制带来超参数依赖 | 先验框数量、匹配方式都会影响效果 |
| 定位精度仍不如后续更成熟方案 | 边框回归和特征金字塔还不够完善 |
| YOLO9000 的长尾类别性能不均衡 | 只有分类监督而无检测框时,泛化能力仍有限 |
历史位置
YOLOv2 最重要的意义,不在于它单独引入了某一个新技巧,而在于它把 YOLO 从“一个有冲击力的新想法”推进成“一个可以持续演进的检测框架”。很多后来的改进方向——anchor 设计、特征融合、多尺度训练、大类别体系扩展——都能在这一版里找到原型。
从 YOLOv1 到 YOLOv2,可以看到检测任务的重心发生了进一步转移:
- YOLOv1 关注的是“能不能把检测统一成一次前向传播”;
- YOLOv2 关注的是“统一之后,怎样把这个系统真正做稳、做快、做强”;
- 后续版本则在这条路线下继续补齐更强的特征表达、更细的多尺度建模和更成熟的训练目标。
因此,YOLOv2 不只是一个“改进版”,更像是现代实时检测器开始进入工程化成熟阶段的关键节点。
总结
YOLOv2 并没有改变 YOLO 的基本路线,但它通过一系列看似分散、实则相互配合的改动,把这一条路线推到了新的阶段。
如果把它的核心贡献概括成三点,可以写成:
- 把边界框预测变得更稳定:anchor、聚类先验框和直接位置预测共同改善了定位学习;
- 把检测器做得更快更灵活:Darknet-19 与多尺度训练提升了实际部署价值;
- 把检测能力扩到更大类别空间:YOLO9000 证明分类数据和检测数据可以被统一利用。
YOLOv2 的历史地位,更多来自它把 YOLO 从“一个大胆的新思路”推进成“一个真正能够持续演化的系统框架”。它并不是这一时期精度最高的检测器,却把 one-stage detector 的工程潜力第一次系统释放了出来。也正因为这一步完成得足够扎实,后续 YOLO 系列才会沿着这条主线继续快速演进。
参考资料
- Redmon, J., & Farhadi, A. (2017). YOLO9000: Better, Faster, Stronger.
- pjreddie/darknet.
- datawhalechina/yolo-master.