YOLOv3 由 Joseph Redmon 与 Ali Farhadi 于 2018 年提出,论文标题里的 Incremental Improvement 往往会让人误以为它只是一次常规迭代,但如果把它放回 YOLO 系列的发展脉络里看,这一版的意义其实比“增量改进”更大。和 YOLOv1 重新定义检测任务、YOLOv2 系统补齐 anchor-based 检测框架不同,YOLOv3 更像一次非常明确的结构升级:它不再试图回答 one-stage detector 是否成立,而是集中解决另一个更实际的问题——当统一预测已经被证明可行之后,怎样进一步把多尺度目标检测、小目标召回和速度-精度平衡做得更成熟。
从后来的视角回看,YOLOv3 最重要的价值,不只是 mAP 的继续提升,而在于它把很多今天看来已经非常自然的设计第一次以相对完整的方式组织到了一起:更深的残差骨干网络、更明确的三尺度检测头、上采样与跨层拼接形成的特征融合、以及从 softmax 转向独立 logistic 分类。这让 YOLO 系列第一次真正站到了“快且足够强”的位置上,也让它从一个强调实时性的检测器,进一步走向一个更成熟的多尺度检测系统。

问题背景与方法动机
YOLOv2 已经显著改善了 YOLOv1 的很多短板,但它仍然存在几个非常具体的问题:
- 小目标检测仍然偏弱:单一主检测尺度很难同时兼顾大目标和小目标;
- 深层特征语义强、浅层细节不足以直接用于检测:对密集场景和远距离目标不够友好;
- 分类建模仍偏向单标签互斥:softmax 假设在一些真实类别关系中并不理想;
- 骨干网络表达能力还有提升空间:需要更深但仍可高效推理的 backbone。
YOLOv3 的关键判断是:实时检测器的下一步,不只是继续调框,而是要同时升级特征表达、检测头组织方式和类别预测方式。因此它的改进重心集中在三件事上:更强的 backbone、更合理的多尺度检测,以及更贴近检测任务本身的预测头设计。
下面这张表可以快速定位 YOLOv3 相对 YOLOv2 的变化方向:
| 维度 | YOLOv2 | YOLOv3 |
|---|---|---|
| 骨干网络 | Darknet-19 | Darknet-53 + 残差连接 |
| 检测尺度 | 主要单尺度 | 三尺度预测 |
| 特征融合 | Passthrough | 上采样 + 跨层拼接 |
| 类别预测 | softmax / 层次化扩展语境 | 独立 logistic 分类 |
| 输出组织 | anchor-based | anchor-based,多尺度 head 更成熟 |
| 小目标支持 | 有改善但仍有限 | 明显增强 |
YOLOv3 的整体思路
如果把 YOLOv3 的核心变化压缩成一句话,那么可以写成:它让检测头真正建立在多层级特征之上,而不是只依赖单一高语义特征图。
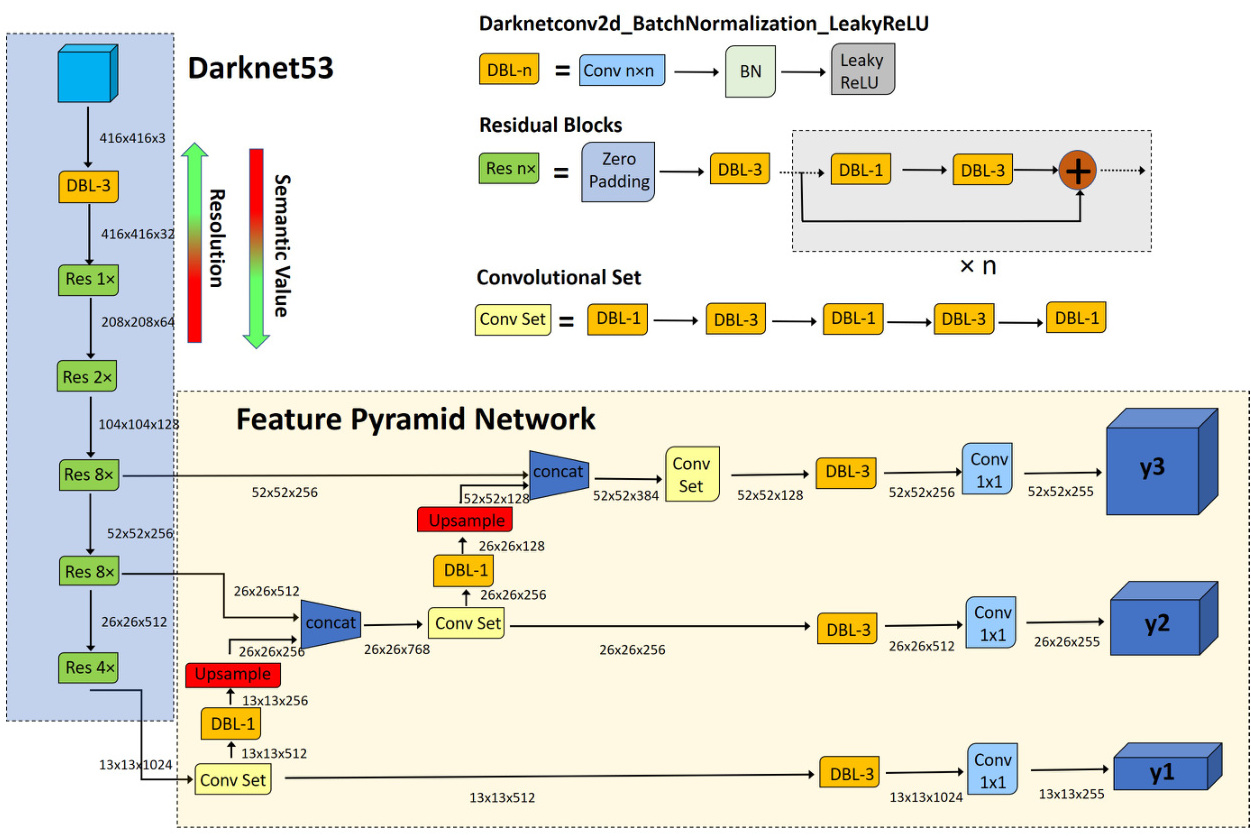
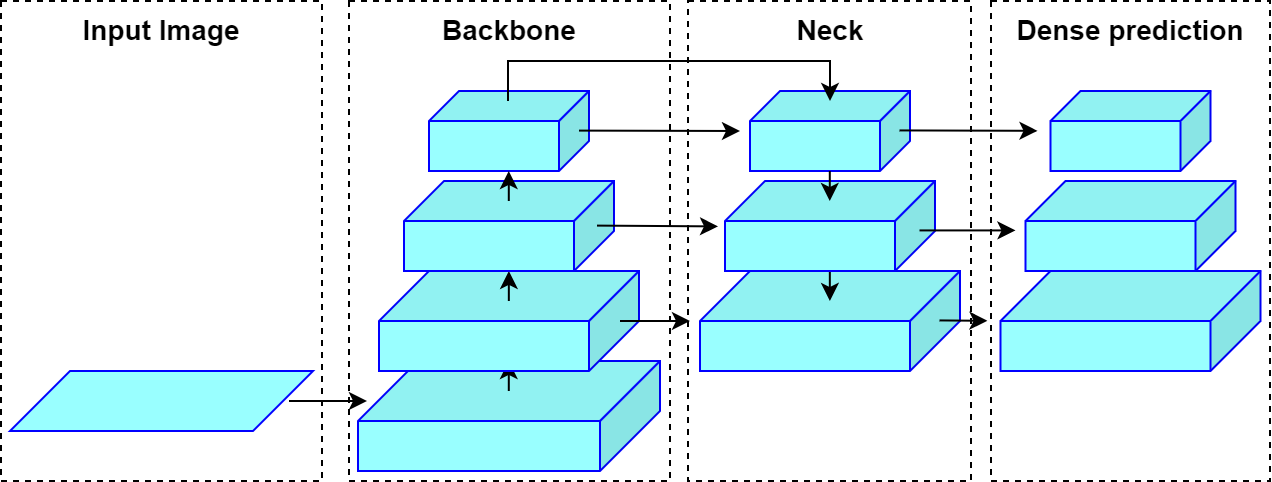
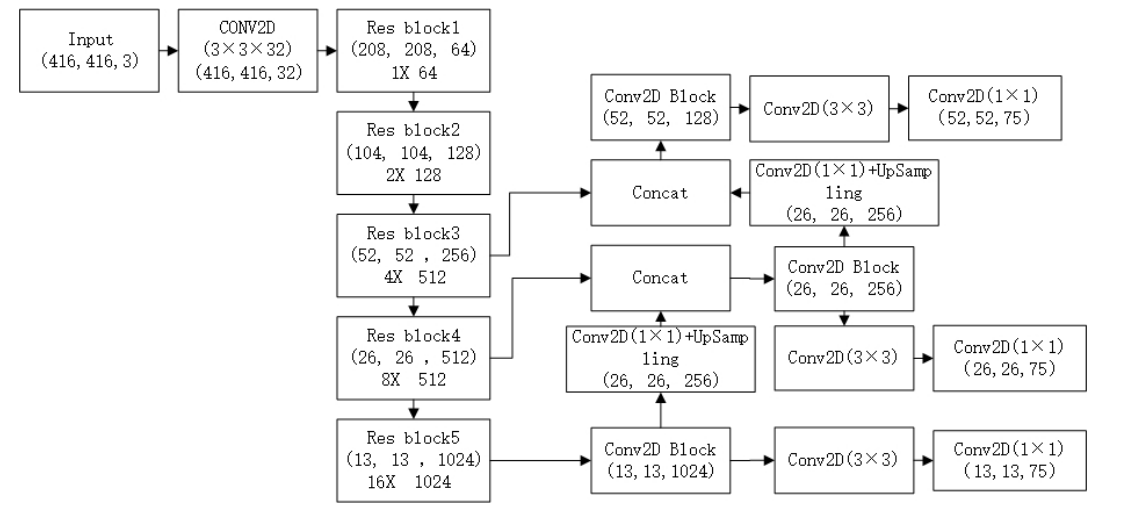
YOLOv3 的整体结构可以概括为三部分:
- Backbone:用 Darknet-53 提取更强的分层特征;
- Neck-like 融合过程:通过上采样与跨层拼接,把深层语义传到更高分辨率特征;
- Head:在 13×13、26×26、52×52 三个尺度上分别做检测。
如果用今天更常见的检测器术语来解释,这三部分各自解决的问题也很清楚:
| 模块 | 它负责什么 | 在 YOLOv3 里对应什么 |
|---|---|---|
| Backbone | 从输入图像中提取越来越抽象的视觉特征 | Darknet-53 |
| Neck | 融合不同层级的特征,让语义和细节重新结合 | 上采样 + Concat 的多尺度融合路径 |
| Head | 把融合后的特征变成检测结果 | 三个尺度上的检测输出层 |
可以把它们理解成一条流水线:
- Backbone 解决“看到了什么”:从原始图像中提取边缘、纹理、部件到语义目标等分层表示;
- Neck 解决“该把哪些信息拼在一起”:把深层语义和浅层细节重新组织,让不同尺度的目标都能有合适的特征输入;
- Head 解决“最终怎么报出答案”:在每个尺度上输出框的位置、目标置信度和类别分数。
需要注意的是,YOLOv3 论文原文并没有像后来的很多模型那样非常明确地单独命名“Neck”,但从现代目标检测的视角看,它的上采样与跨层拼接部分已经在承担 Neck 的功能。
这种设计背后的直觉非常直接:
- 大目标更依赖高层语义和大感受野;
- 小目标更依赖高分辨率特征和局部细节;
- 如果所有目标都只在一个尺度上预测,模型天然会顾此失彼。
因此,YOLOv3 的方法论升级重点,不再是“要不要用 anchor”这种单点问题,而是如何把不同尺度的特征真正组织成一个分工明确的检测系统。
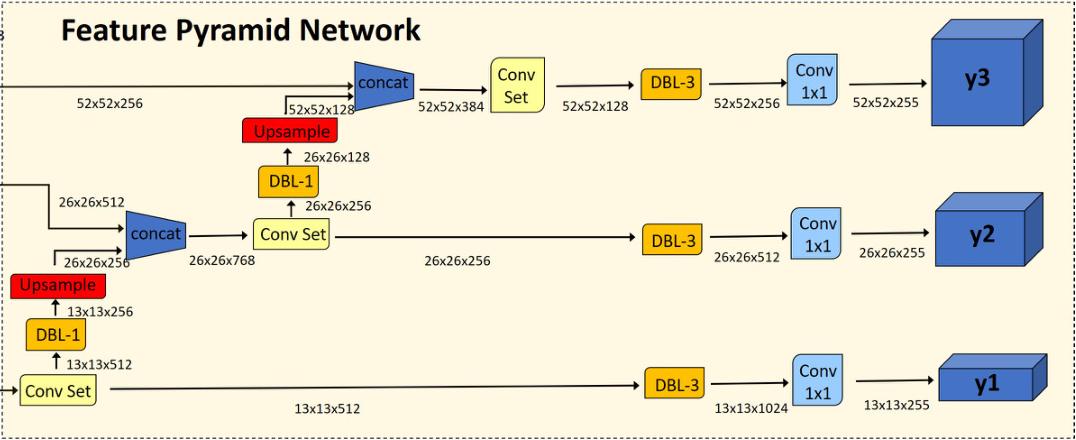
多尺度预测:YOLOv3 最关键的结构升级
三个检测头分别负责不同尺度目标
YOLOv3 最具代表性的改动,就是把检测输出扩展为三个尺度。对于常见的 输入,三个检测特征图通常对应:
- :更适合大目标;
- :更适合中等目标;
- :更适合小目标。
如果把这个过程写得更具体一些,可以把它理解成一条逐级向上“回传语义”的路径:模型先从 这一类深层语义特征出发,先生成最粗尺度的检测分支;然后把这层特征上采样到 ,与 backbone 中对应的 特征图做 concat,再通过卷积进一步融合;接着再把融合后的特征继续上采样到 ,与 backbone 里的 特征 concat,再做一次卷积融合,最终得到更适合小目标检测的高分辨率特征。
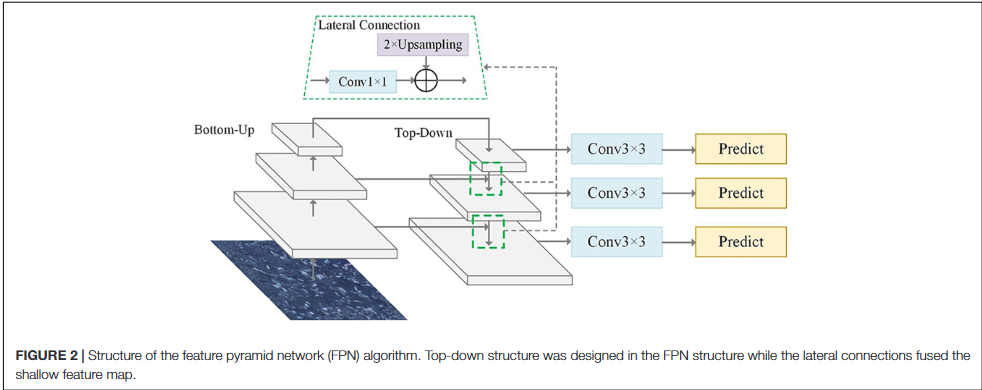
这其实就是非常典型的 neck / FPN 工作方式:把深层的强语义信息往高分辨率层传,让高分辨率特征不只保留细节,也拥有更强的目标语义表达能力。也正因为如此,YOLOv3 的三尺度结构并不是简单“多接几个输出头”,而是先通过 neck 式的特征融合,把不同层级的特征组织好,再分别交给不同尺度的检测头。
这件事之所以重要,是因为它直接改变了模型分配表示能力的方式。YOLOv2 的检测更多建立在较粗的特征图上,小目标在下采样过程中容易丢失细节;YOLOv3 则通过额外的高分辨率检测头,让小目标第一次真正拥有更合适的预测空间。
上采样与跨层拼接如何起作用
YOLOv3 的多尺度预测并不是简单地在三个特征图上各接一个分类器,而是通过上采样把更深层的语义信息传回更高分辨率特征图,再与浅层特征拼接。
这种设计与 FPN 的思想高度相近:深层负责语义,浅层负责细节,检测头同时利用两者。具体来说,较深层输出先做 卷积调整通道,再进行 2 倍上采样,把特征图的空间尺寸从 放大到 ,然后与 backbone 中对应分辨率的浅层特征在通道维上 concat,之后再经过若干卷积生成新的检测分支;再重复一次同样过程,就能继续得到更高分辨率的 检测特征。
如果把这条路径写成更直观的流程,就是:
其中可以把 理解为最深层、语义最强但分辨率最低的特征; 与 则保留了更多中层和浅层的空间细节。YOLOv3 使用的上采样本身并不复杂,通常就是最近邻插值(nearest neighbor upsampling),也就是把每个位置的值复制到更大的网格中。它的重点不在“插值算法有多高级”,而在于先把深层语义拉回高分辨率,再和浅层细节直接拼起来。
这样做之后,三个尺度的检测特征就形成了明确分工:
- :来自最深层特征,分辨率最低,语义最强,主要负责大目标;
- :融合了深层语义和中层细节,主要负责中等目标;
- :进一步融合到高分辨率层,最适合小目标。
从历史视角看,这一步很关键,因为它意味着 YOLO 系列不再只依赖单一路径的最终特征,而是开始明确拥抱“跨层特征融合”这条主线。
为什么这一步对小目标尤其重要
小目标往往有两个问题:
- 在连续下采样后,空间信息容易丢失;
- 即使语义足够强,定位所需的细粒度边界也可能已经模糊。
三尺度预测的意义就在于:把语义信息往高分辨率层传,同时保留更多局部细节。这让 YOLOv3 在 COCO 这类目标尺度差异很大的数据集上,比前代更有现实竞争力。
Darknet-53:更深但仍然高效的骨干网络
YOLOv3 使用 Darknet-53 作为 backbone。与 YOLOv2 的 Darknet-19 相比,它最核心的变化有两点:
- 网络更深:特征提取能力更强;
- 引入残差连接:使深网络更容易优化。
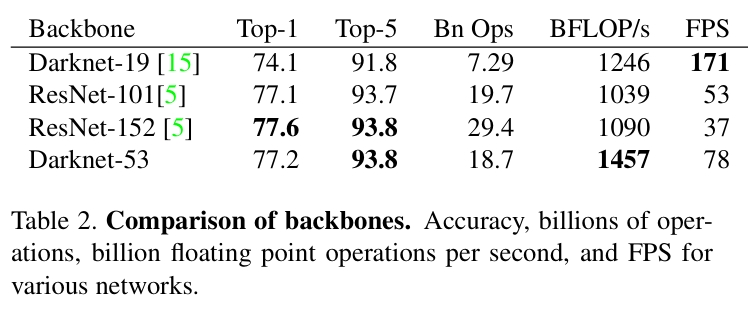
如果只看表面,“更深”并不新鲜;真正关键的是它没有单纯把层数堆上去,而是借助残差结构让网络在可训练性和效率之间取得平衡。YOLOv3 需要的是一个既能提供更强特征表达、又不会把实时性彻底拖垮的 backbone,Darknet-53 正是在这个位置上成立的。
从结构上看,Darknet-53 延续了大量 与 卷积组合的思路,并在多个阶段引入 residual block。它既吸收了 ResNet 一类深层网络的经验,又保持了 YOLO 系列一贯强调的推理效率。
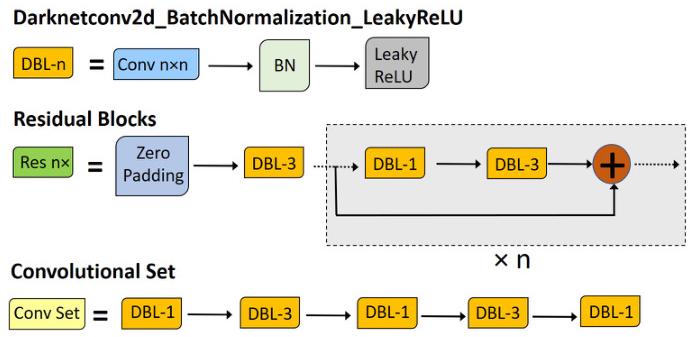
残差块为什么重要
残差块的核心形式可以写成:
这并不只是一个“结构技巧”,而是在优化上给深网络提供了一条更稳定的路径:如果某些层暂时学不到特别有价值的新变换,网络至少可以较容易地保留原始信息。对于需要堆叠较多卷积层的检测 backbone 来说,这能显著缓解训练难度。
预测头设计:从单标签假设走向独立分类
YOLOv3 的另一个重要变化,是类别预测不再沿用强互斥假设下的 softmax,而改为对每个类别使用独立 logistic 分类,并以二元交叉熵进行训练。
这背后的逻辑很清楚:检测任务中的类别关系并不总是严格互斥。例如“person”和更细粒度的人类相关标签,在语义上可能存在层次或交叠。如果强行要求所有类别在一个 softmax 下竞争,建模并不总是自然。
因此,YOLOv3 把类别预测拆成多个独立二分类问题。这样做的收益主要有两点:
- 更贴近真实标签关系;
- 让检测头的类别建模更加直接。
与此同时,YOLOv3 仍然保留 anchor-based 检测框架。每个尺度分配 3 个 anchor,三个尺度合计 9 个 anchor,分别覆盖不同目标尺寸分布。
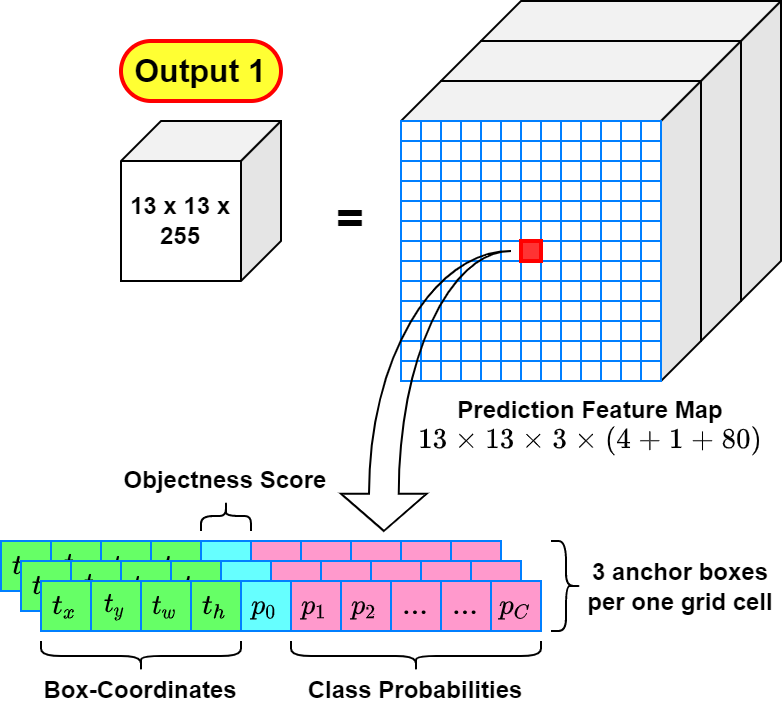
输出张量与锚框分配
对于 COCO 的 80 类设定,YOLOv3 每个 anchor 需要预测:
- 4 个边界框参数;
- 1 个 objectness;
- 80 个类别分数。
因此单个 anchor 的输出维度为:
每个空间位置有 3 个 anchor,所以单尺度输出通道数为:
这也是为什么 YOLOv3 的三个检测层通常都对应 的输出结构。
如果把三个尺度的输出分别记为 ,那么它们本质上都是同一种张量,只是空间分辨率不同:
对每一个尺度来说,网络都会在每个 grid cell 上为 3 个 anchor 分别输出一组预测,因此可以把它继续 reshape 成:
其中 是类别数。接下来,得到最终输出并不是把 直接拼在一起就结束了,而是还要经历一条完整的后处理链路:
- 按 anchor 拆分预测:从每个尺度的张量里取出 、objectness 和各类别分数;
- 解码成真实框:结合当前 grid 位置与 anchor 尺寸,把偏移量还原成输入图像上的边界框;
- 计算类别置信度:通常把 objectness 与类别概率相乘,得到每个类别对应的最终 score;
- 汇总三尺度候选框:把 解码得到的所有候选框放到一起;
- 做置信度阈值筛选与 NMS:删除低分框,并去掉大量重叠的冗余预测;
- 得到最终检测结果:输出剩余框的类别、分数和坐标。
换句话说, 是三个不同尺度上的“原始预测张量”,而真正用户看到的最终结果,是三个尺度全部解码后再统一筛选得到的一组检测框。
换一种更直观的方式看,YOLOv3 的推理流程其实像三条支路最后汇总到一个总出口:
输入图像
↓
Backbone (Darknet-53)
↓
多层特征
├─→ y1 (13×13, 大目标)
├─→ Upsample + Concat ─→ y2 (26×26, 中目标)
└─→ Upsample + Concat ─→ y3 (52×52, 小目标)
y1 ── decode ──┐
y2 ── decode ──┼─→ merge all boxes ─→ score filter ─→ NMS ─→ 最终输出
y3 ── decode ──┘这张“流程图”里最容易混淆的是 decode、merge 和 NMS 三步:
- decode:把每个尺度上的原始张量预测,还原成真正的候选框坐标与类别分数;
- merge:把三个尺度产生的候选框放进同一个候选集合里统一比较;
- NMS:如果多个框指向的是同一个目标,只保留分数最高、最可信的那个,去掉重复框。
所以,y1 / y2 / y3 的关系不是“谁覆盖谁”,而是“各自负责不同尺度目标,然后把答案交到同一个裁判席”。真正的最终输出,不属于某一个单独的尺度,而是三个尺度共同生成候选框后再统一筛选的结果。
边界框仍然围绕 anchor 预测偏移量,其核心形式与 YOLOv2 延续一致:
其中 是 grid cell 左上角位置, 是 anchor 先验尺寸。这种参数化方式的关键好处在于:网络学习的是相对局部修正,而不是无约束地从零生成整个边界框。
把这一步和三尺度输出连起来看,最终推理过程可以写成:
这里:
- 分别表示三个尺度解码后的候选框集合;
- 表示把所有尺度候选框合并后的全集;
- 则是经过阈值筛选和非极大值抑制后保留下来的最终输出。
因此,YOLOv3 的“多尺度输出”并不是三个彼此独立的最终答案,而更像三个不同观察粒度下生成的候选框池:大目标更多来自 ,中目标更多来自 ,小目标更多来自 ,最后再统一竞争、统一去重,形成一组最终检测结果。

从配置角度理解 YOLOv3
如果从工程实现角度看,YOLOv3 的结构其实非常适合通过配置文件理解。下面这个简化片段就能看出它的主线:先得到更深的 backbone 特征,再逐步上采样并与中浅层特征拼接,最后送入 Detect 头。
# darknet53 backbone
backbone:
- [-1, 1, Conv, [32, 3, 1]]
- [-1, 1, Conv, [64, 3, 2]]
- [-1, 1, Bottleneck, [64]]
- [-1, 1, Conv, [128, 3, 2]]
- [-1, 2, Bottleneck, [128]]
- [-1, 1, Conv, [256, 3, 2]]
- [-1, 8, Bottleneck, [256]]
- [-1, 1, Conv, [512, 3, 2]]
- [-1, 8, Bottleneck, [512]]
- [-1, 1, Conv, [1024, 3, 2]]
- [-1, 4, Bottleneck, [1024]]
# multi-scale head
head:
- [-1, 1, Conv, [512, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 8], 1, Concat, [1]]
- [-1, 1, Conv, [256, 1, 1]]
- [-1, 1, nn.Upsample, [None, 2, 'nearest']]
- [[-1, 6], 1, Concat, [1]]
- [[27, 22, 15], 1, Detect, [nc]]这段配置本身就说明了 YOLOv3 的核心不只是“更深”,而是更深的特征提取 + 更明确的多尺度组织方式。
YOLOv3 的优势、局限与历史位置
优势
| 优势 | 说明 |
|---|---|
| 小目标检测更强 | 三尺度检测头显著改善了高分辨率目标预测能力 |
| 特征表达更强 | Darknet-53 比 Darknet-19 有更强的 backbone 表达能力 |
| 结构更成熟 | 上采样 + concat 让特征融合思路更清晰 |
| 类别建模更灵活 | 独立 logistic 分类更贴近检测任务实际 |
| 速度与精度平衡出色 | 在实时检测器中保持了很强竞争力 |
局限
| 局限 | 根源 |
|---|---|
| anchor 机制仍有超参数负担 | anchor 尺寸、匹配策略仍会影响性能 |
| 多尺度融合仍较朴素 | 还没有后续 PAN、CSP 等更丰富的路径设计 |
| 定位与标签分配仍不够先进 | 与后来的 anchor-free 或更强匹配策略相比还有差距 |
| 长尾类别与极端密集场景仍有限制 | one-stage 检测在复杂分布下依然会遇到召回和区分难题 |
历史位置
YOLOv3 最重要的意义,在于它把 YOLO 系列真正推进到了“成熟实时检测器”的阶段。YOLOv1 证明了统一预测可行,YOLOv2 让这条路线变得更稳,而 YOLOv3 则进一步说明:one-stage detector 不只可以快,还可以在多尺度目标检测上做得足够实用。
很多后来被广泛讨论的主线——更强 backbone、特征金字塔、多尺度 head、跨层融合——在 YOLOv3 这里都已经形成了相当清晰的组合形态。它未必是这一时期绝对精度最高的模型,但它非常像一个关键分水岭:从这一版开始,YOLO 不再只是“快”的代名词,而逐渐成为“快且足够强”的代表。也正因为这一步完成得足够扎实,后续版本才得以继续沿着 backbone、neck 和 detection head 三条主线不断细化演进。
总结
YOLOv3 并没有改变 YOLO 的基本路线,但它通过一组彼此配合的结构升级,把这条路线真正推进到了多尺度检测的成熟阶段。
如果把它的核心贡献概括成三点,可以写成:
- 用三尺度预测真正提升了多尺度目标检测能力;
- 用 Darknet-53 提供了更深、更稳的特征表达基础;
- 用更直接的分类头设计,让检测预测更贴近真实任务需求。
YOLOv3 的历史地位,更多来自它把 YOLO 从“强调实时性的检测器”进一步推进成“结构完整、性能均衡的实时检测系统”。它不是这段时期唯一强的模型,却让很多后来被反复采用的 detector design choices,第一次在 one-stage 语境里被组合得足够清楚。也正因为这一版把 backbone、feature fusion 和 detection head 的关系理顺了,后续 YOLO 系列才会沿着这条主线继续快速演进。
参考资料
- Redmon, J., & Farhadi, A. (2018). YOLOv3: An Incremental Improvement.
- pjreddie/darknet.
- datawhalechina/yolo-master.
- Lin, T.-Y., Dollar, P., Girshick, R., He, K., Hariharan, B., & Belongie, S. (2017). Feature Pyramid Networks for Object Detection.