YOLOv4 由 Alexey Bochkovskiy、Chien-Yao Wang 与 Hong-Yuan Mark Liao 于 2020 年提出。和 YOLOv1 重新定义检测任务、YOLOv3 把多尺度检测做成熟不同,YOLOv4 更像一次非常明确的系统整合:它并没有试图推翻既有的 one-stage detector 主线,而是把当时已经被证明有效的 backbone、neck、训练技巧、损失函数和后处理经验重新组织到了一起,目标只有一个——在普通 GPU 上把速度与精度一起推到更高的位置。
从今天回看,YOLOv4 的历史地位并不只是“又一个经典版本”。它真正重要的地方在于:它把“模型结构设计”和“训练配方设计”第一次如此系统地并列起来。Bag of Freebies 负责在不增加推理成本的前提下挖掘训练收益,Bag of Specials 则负责用少量额外计算换取关键精度提升。也正因为这套方法论足够完整,YOLOv4 才成为很多人理解现代 anchor-based 检测器工程峰值时绕不开的一站。

问题背景与方法动机
到了 YOLOv4 所在的时间点,实时检测器面对的核心问题已经不再是“单阶段检测能不能做”,而是另一件更现实的事:怎样在不依赖超大规模算力和复杂部署条件的前提下,把速度、精度与训练可用性同时做上去。
YOLOv3 已经解决了很多早期版本的问题,但仍然有几个非常具体的短板:
- 结构升级仍偏分散:更强的 backbone、necks 和后处理策略已经出现,但缺少一次足够系统的整合;
- 训练收益没有被方法论化:很多增强、正则化和调度技巧有效,却没有被组织成可复用的配方;
- 小目标与密集场景仍然吃力:即便有多尺度预测,复杂背景下的召回与定位仍有提升空间;
- 定位质量仍有优化空间:单纯依赖 IoU 一类回归信号,对中心距离和宽高比建模仍然不够直接;
- 工程门槛依然偏高:高精度检测器往往意味着更重的计算和更苛刻的训练条件。
YOLOv4 的核心判断可以概括成一句话:真正成熟的实时检测器,不该只靠一个新模块取胜,而应该把结构设计、训练配方和后处理经验一起系统化。
下面这张表可以快速定位 YOLOv4 相对 YOLOv3 的变化方向:
| 维度 | YOLOv3 | YOLOv4 |
|---|---|---|
| 主要目标 | 把多尺度检测做成熟 | 把速度、精度、训练技巧做系统整合 |
| Backbone | Darknet-53 | CSPDarknet53 |
| Neck | FPN 风格上采样与拼接 | SPP + PAN 组合,特征融合更完整 |
| 训练策略 | 有增强,但不够体系化 | BoF 成体系整理训练收益 |
| 回归损失 | 传统框回归主线 | CIoU Loss 强化定位质量 |
| 方法论 | 结构升级为主 | 结构 + 训练 + 后处理共同设计 |
YOLOv4 的整体思路
如果把 YOLOv4 的方法论压缩成一句话,那么可以写成:它不是发明全新的检测范式,而是把当时最有效的一批思路整理成一个真正能落地的实时检测系统。
YOLOv4 的整体结构仍然可以概括为三个层次:
- Backbone:用 CSPDarknet53 提升特征提取能力与梯度流效率;
- Neck:用 SPP 扩大感受野,再用 PAN 加强跨层特征融合;
- Head:延续 YOLOv3 的多尺度 anchor-based 检测头,并优化训练与推理细节。
但真正让 YOLOv4 与前代拉开距离的,并不是这三段式结构本身,而是它给这套结构加上了两份“方法包”:
- Bag of Freebies:尽量只在训练阶段生效、几乎不增加推理成本的技巧;
- Bag of Specials:在推理阶段增加少量开销,但能换来显著收益的模块与策略。

为什么 BoF 与 BoS 重要
YOLOv4 最值得记住的,不只是“它用了哪些模块”,而是它清楚地区分了两类优化来源:
- 一类收益来自训练阶段怎么喂数据、怎么调损失、怎么稳定优化;
- 另一类收益来自网络本体怎么组织特征、怎么扩大感受野、怎么做更好的融合。
这一区分很重要,因为它改变了人们理解检测器优化的方式。模型性能不再只被理解为“换了哪个 block”,而是被理解为结构设计、训练配方与推理策略的联合作用结果。
一张图看 YOLOv4 的主干结构
下面这张结构图可以帮助快速建立整体感知:输入先经过 CSPDarknet53 提取特征,再通过 SPP 与 PAN 强化多尺度表示,最后在三个尺度上输出检测结果。
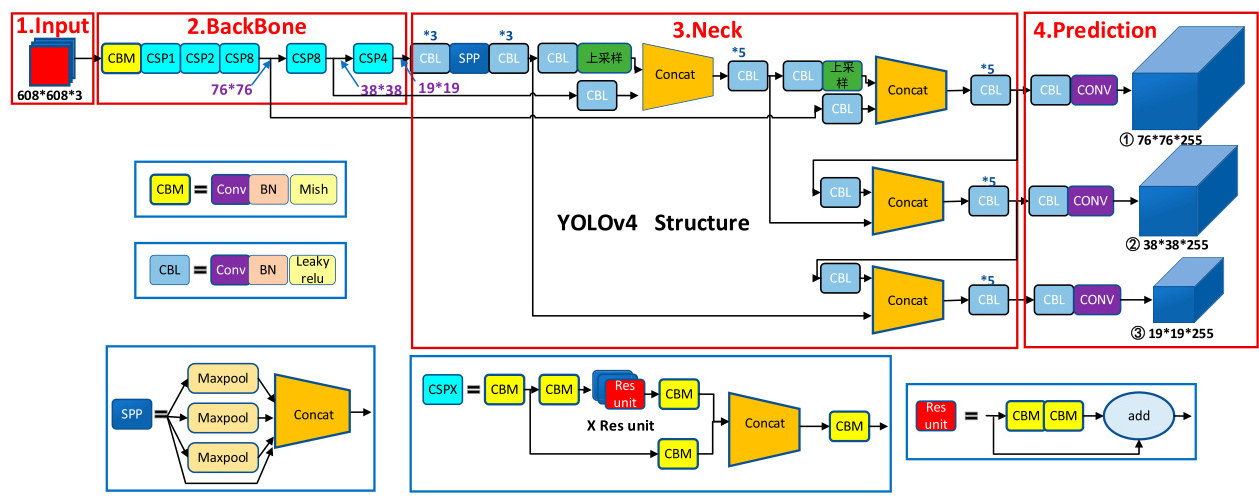
一张图看 YOLOv4 从 Backbone 到 Head 的完整链路
如果想把原文里分散讲解的 backbone、SPP、PANet 和三尺度 head 放到一张图里统一理解,下面这张总览图会更直观。它把 CSPDarknet53 → SPP → PANet → Yolo Head 的信息流完整串了起来,也能帮助理解为什么 YOLOv4 的性能提升不是某一个模块单独带来的,而是整条特征链共同重构后的结果。

引用:https://blog.csdn.net/qq_43360533/article/details/108174808
Backbone 与 Neck:YOLOv4 怎样把特征表达做得更强
先从整体结构看:Backbone 与 Neck 分别负责什么
YOLOv4 的 backbone 和 neck 并不是两段孤立结构,而是一条连续的特征加工链:
- Backbone 负责把原始图像逐步压缩成更高语义、更强表达的分层特征;
- Neck 负责把这些不同层级的特征重新组织起来,让检测头同时拿到足够强的语义信息和足够细的定位细节。
如果只从功能上理解,backbone 更像“先把图像读懂”,neck 更像“再把读懂的结果重新分发给不同尺度的检测任务”。YOLOv4 真正的升级点,就在于它把这两段链路中的多个基础模块都重新整理了一遍,而不是只替换某一个大模块。
CSPDarknet53:更强 backbone,不靠纯堆深获胜
YOLOv4 使用 CSPDarknet53 作为骨干网络。它并不是简单把 YOLOv3 的 Darknet-53 再加深一层,而是引入 CSPNet 的思路,把部分梯度流拆分开来,让一部分特征经过更重的残差路径,另一部分则保留为更直接的信息通路,最后再进行融合。
这件事的核心收益有三点:
- 减少重复计算:不是所有通道都必须走完全相同的重路径;
- 改善梯度传播:分支化的信息流让深层网络更容易优化;
- 提高特征复用效率:浅层与深层表示可以更自然地在后续阶段汇合。
如果从工程视角理解,CSPDarknet53 的意义并不是“又一个更复杂的 backbone”,而是它试图在表达能力、计算量和可训练性之间找一个更平衡的点。YOLOv4 追求的不是单纯更深,而是更值得把计算预算花进去。
CBM:YOLOv4 backbone 里最基础的积木
在 YOLOv4 的 backbone 语境里,最基础的模块之一是 CBM,也就是 Conv + BatchNorm + Mish。它本质上是一个卷积块,但它的重要性不只是“常见基础层”这么简单,而是它决定了特征在进入更复杂结构之前,如何被线性变换、归一化和非线性激活。
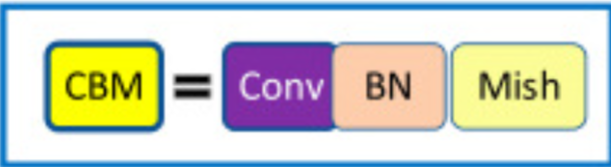
从作用上看,CBM 负责三件事:
- Conv:提取局部空间特征并调整通道数;
- BatchNorm:稳定训练分布,减轻深层训练不稳定;
- Mish:提供更平滑的非线性表达。
源笔记之所以专门把它单列出来,是因为 YOLOv4 的 backbone 并不是由抽象概念构成的,而是由这种层层堆叠的基础块真实搭起来的。无论是 CSP 分支、残差路径还是更深层的 stage,底层都离不开这类卷积块。
Mish:为什么 YOLOv4 在 backbone 中换掉常规激活函数
YOLOv4 在很多 backbone 基础块中采用 Mish 激活,而不是更常见的 ReLU 或 Leaky ReLU。Mish 可以写为:
它被看重,主要不是因为“形式更新”,而是因为它具备三个在深层特征提取中很有价值的性质:
- 非单调:对小负值不会像 ReLU 那样直接截断;
- 平滑:导数变化更连续,有助于梯度传播;
- 自正则化倾向:在一定程度上能缓解训练中过度剧烈的激活波动。
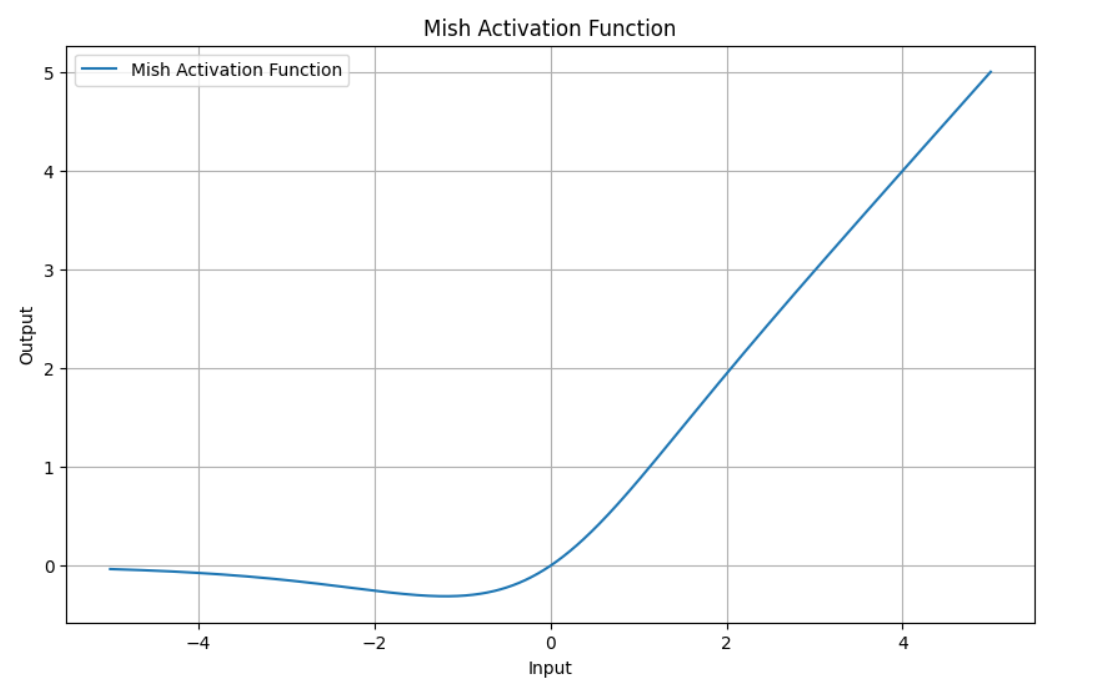
这也是为什么原始资料会把 Mish 视作 YOLOv4 backbone 优化的一部分:它不是单独提高某个模块精度,而是在网络很多层里持续影响特征表达的细腻程度。
ResUnit:深层表达为什么还能保持可训练
YOLOv4 backbone 中另一个关键基础模块是残差单元,也就是常说的 ResUnit。它的核心思想并不复杂:让一条分支学习新的变换,另一条分支保留原始信息,最后做相加。
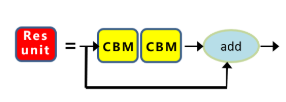
这样做的意义在于:
- 网络不必每一层都“重新发明”完整特征;
- 如果某层暂时学不到特别有价值的新映射,至少还能把已有信息稳定传下去;
- 深层堆叠时,梯度传播路径更顺畅,不容易出现优化困难。
在 YOLOv4 的语境里,ResUnit 并不是为了追求 ResNet 式叙事本身,而是为 CSPDarknet53 这种更深、更复杂的主干提供一个能稳定训练的骨架。
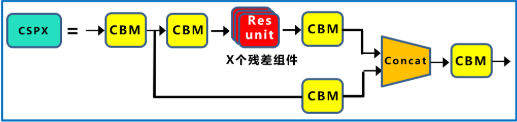
CSP 模块到底怎么工作
如果把 YOLOv4 backbone 的关键结构再往下拆,最值得单独理解的就是 CSP 模块本身。它的典型流程可以概括为:
- 输入特征先经过卷积做通道调整与下采样;
- 特征被分成两路;
- 一路进入若干残差块,学习更复杂的高层变换;
- 另一路保留为更直接的信息通道;
- 两路在末端 concat,再经过卷积融合。
这个设计的关键,不只是“有两条分支”,而是它让网络在同一个 stage 里同时保留了两种不同性质的表示:
- 一种更偏直接传递;
- 一种更偏深度变换。
原文里强调的“减少梯度冗余”和“增强跨阶段连接”,本质上说的就是这件事:不是所有特征都要被重复加工,网络应该学会把计算预算集中花在真正值得深加工的那一部分信息上。
从 stage 视角理解 CSPDarknet53
如果把 backbone 看成由多个 stage 组成,那么 CSPDarknet53 的主线可以理解为:
- 先用卷积和下采样逐步降低空间分辨率;
- 再在不同 stage 中堆叠 CSP 结构和残差单元;
- 让特征图在空间尺度缩小的同时,通道表达不断增强;
- 最终为 neck 提供多个层级的特征输出。
因此,CSPDarknet53 并不只是“一个更强的 backbone 名字”,而是一套有明确分工的层级化特征提取系统。浅层保留细节,中层开始积累语义,高层则承担更强的全局表达,这些输出后面都会被 neck 重新利用。
SPP:先扩大感受野,再谈多尺度融合
YOLOv4 在 backbone 输出后加入 SPP(Spatial Pyramid Pooling)模块。它通过多个不同尺度的最大池化分支并行提取上下文,再在通道维度上拼接,从而让后续特征同时看到更大范围的空间信息。
这一步的关键不在于“固定长度向量”这一早期叙事,而在于两个更贴近检测的收益:
- 扩大有效感受野:高层特征能更好地整合局部目标与周围上下文;
- 补充多尺度上下文:不同池化窗口捕捉到的区域范围不同,有助于后续检测头兼顾大目标与复杂背景。
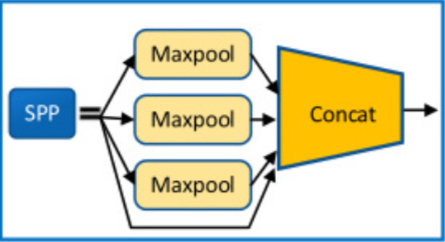
更具体一点说,SPP 在 YOLOv4 里通常不是只做单一池化,而是并行使用多个池化核,例如 、、,让同一层高层特征同时看到不同尺度的邻域信息。这样做的直觉非常直接:对于检测来说,目标是否存在,往往不仅由目标内部纹理决定,也由它周围上下文共同决定。
这一点可以用一个简化的实现片段来理解:
class SPP(nn.Module):
def __init__(self, pool_sizes=(5, 9, 13)):
super().__init__()
self.pools = nn.ModuleList(
nn.MaxPool2d(kernel_size=size, stride=1, padding=size // 2)
for size in pool_sizes
)
def forward(self, x):
features = [x]
for pool in self.pools:
features.append(pool(x))
return torch.cat(features, dim=1)这段代码最值得注意的地方,不是写法本身,而是它反映出的设计意图:YOLOv4 希望在不彻底改变主干网络的前提下,把高层特征的上下文表达再往前推一步。
Neck 为什么不只是“特征拼起来”这么简单
在 YOLOv4 里,neck 的任务不是简单把 backbone 输出拿来直接接检测头,而是把不同尺度、不同语义层次的特征重新组织成更适合检测的表示。
这件事之所以必要,是因为 backbone 输出的特征天然带有分工:
- 高层特征语义更强,但空间分辨率更低;
- 低层特征定位细节更多,但语义抽象程度不足。
如果不经过 neck,这两类特征很难同时被检测头充分利用。YOLOv4 的 neck 就是在解决这个矛盾:让高层语义下得来,让低层细节传得上去。
PAN:把高层语义和低层定位真正接起来
如果说 SPP 主要负责“让特征看得更远”,那么 PAN(Path Aggregation Network)负责的就是“让不同层级的特征更充分地交流”。
YOLOv4 在 neck 中使用 PAN 风格的双向特征融合:
- 自顶向下路径把更高层的语义信息传回高分辨率特征;
- 自底向上路径再把浅层细节反馈回更深层表示;
- 各层之间通过 concat 做拼接,而不是更受限的简单相加。
这一步对检测尤其重要,因为目标检测天然同时依赖两类信息:
- 语义回答“这是什么”;
- 定位细节回答“它在哪里、边界大概长什么样”。
如果网络只能把语义往下传,或者只能把细节留在低层,检测头的工作点就会受限。PAN 的意义正是在于:它把这两类信息重新组织到一个更像“合作关系”的 neck 里。
YOLOv4 里的 PAN 与普通 FPN 有什么不同
如果只说“PAN 是双向特征金字塔”,理解还不够细。YOLOv4 里 PAN 的关键,不只是多了一条自底向上的路,而是它更强调通过 concat 保留更多原始特征,而不是过早把不同层信息压缩成单一路径。

这张图可以按四个层次来读。
第一,(a) 左半部分对应传统 FPN。它的主线是先从 backbone 的高层特征出发,再通过自顶向下路径,把更强的语义逐级传回较高分辨率的特征层,因此最终形成 到 这组特征金字塔。这个过程强调的是“把语义往下送”。
第二,(b) 右半部分对应 PAN。它不是把 FPN 推翻重来,而是在已有 系列特征之上,再增加一条自底向上的路径聚合,形成 到 。这条路径的意义在于:低层的定位细节、边缘和局部纹理,不再只停留在浅层,而是可以重新向上传递到更高层检测分支。
第三,图中的红色虚线表示传统 FPN 路径下,原始图像信息传到最小特征层的路线。它强调的是:如果只靠自顶向下金字塔,底层细节虽然被利用了,但信息到达最深检测语义层的路径仍然偏长,而且主要是“高层向低层单向补充”。
第四,绿色虚线表示引入 PAN 后,原始图像信息传到最小特征层的另一条更直接路径。这条路径说明 PAN 额外补上了“低层往高层回流”的能力,因此最底层细节能够更高效地进入高层特征表达中。
这也是为什么这张图对理解 YOLOv4 很关键:FPN 解决的是高层语义如何覆盖多尺度,PAN 进一步解决的是低层细节如何重新参与高层检测。换句话说,YOLOv4 的 neck 不只是让不同尺度都“有特征可用”,而是让不同尺度之间真正形成双向信息交换。
这意味着:
- 高层语义可以更完整地注入低层高分辨率特征;
- 低层定位细节也不会在一次融合后很快被抹平;
- 后面的检测头接到的不是单一来源特征,而是被反复重组后的复合表示。
引用:https://blog.csdn.net/qq_43360533/article/details/108174808
从原文笔记的角度看,这也是为什么 neck 部分会被反复强调:YOLOv4 的小目标检测改进,并不只是“加了个 head”,而是高低层特征在进入 head 之前已经被重新洗牌过一次。
从模块链路理解 YOLOv4 的 neck
如果按照信息流的顺序去看,YOLOv4 的 neck 大致可以理解为:
- backbone 高层特征先经过若干卷积做通道整理;
- 进入 SPP,补充大感受野上下文;
- 再通过上采样把高层语义传向更高分辨率分支;
- 与来自 backbone 中浅层的特征做 concat;
- 继续卷积整理;
- 再通过自底向上路径把融合后的信息传回更深层分支。
这条链路背后的本质目标,是让每个检测尺度拿到的都不是“某一层单独的输出”,而是融合过语义、细节和上下文的任务特征。
为什么说 YOLOv4 的 backbone 与 neck 是一起升级的
很多人会把 YOLOv4 理解成“更强 backbone + 更强 neck”,但更准确的说法应该是:YOLOv4 把 backbone 和 neck 之间的协作关系也一起升级了。
- backbone 不再只是更深,而是通过 CSP 更强调高效梯度流;
- neck 不再只是把多尺度特征接起来,而是通过 SPP 与 PAN 更明确地组织上下文与跨层融合;
- 两者合起来,才让后面的检测头真正站在一个更好的工作点上。
也就是说,YOLOv4 的检测提升并不来自某个“神奇单模块”,而来自一整条特征链的重新设计。这也是原始资料里 backbone、neck 会被分别拆到每个模块层面去讲的根本原因。
检测头与预测方式:YOLOv4 保留了什么,又改进了什么
多尺度检测头仍然沿用 YOLOv3 主线
YOLOv4 并没有推翻 YOLOv3 已经成熟的多尺度预测框架。它仍然在三个尺度上输出检测结果,用来分别覆盖大目标、中目标和小目标。对常见输入尺度而言,三个特征图通常对应更粗到更细的三组预测分支。
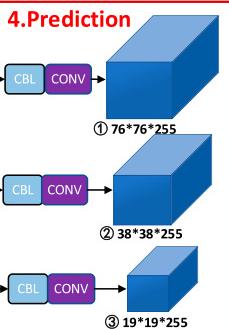
这张原图更适合从“head 的分工”去理解 YOLOv4:高分辨率分支更偏向小目标,低分辨率分支更偏向大目标,而中间尺度则承担中等尺寸目标的检测。也就是说,YOLOv4 的 head 不是一个单头统一输出,而是三个分工明确的检测分支。
这说明 YOLOv4 的态度非常务实:已经被证明有效的结构,不需要为“看起来更新”而推倒重来。真正值得优化的,是这些检测头前面的特征质量、训练方式和定位信号。
预测框参数仍然是局部偏移学习
YOLOv4 依旧沿用 anchor-based 的预测形式。网络学习的不是从零生成整个边界框,而是围绕网格位置与 anchor 先验去预测局部偏移。
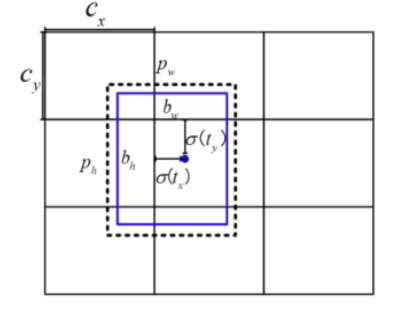
对于某个网格与 anchor,边界框通常可写为:
其中 表示当前网格左上角位置, 表示 anchor 先验尺寸。这种参数化方式的核心好处是:模型学习的是受约束的局部修正,而不是完全无先验的全局回归。
网格敏感度问题为什么要单独处理
YOLO 系列早期一个常见问题是 grid sensitivity:当目标中心接近网格边界时,坐标回归更容易出现不稳定。YOLOv4 在预测公式与训练细节上做了针对性修正,目的不是重新定义检测头,而是让已有头部在边界场景下更稳定。
从实际检测结果来看,head 最终输出的不只是框参数,还包括类别概率与 objectness 分数。下面这张原图可以帮助把“预测参数”与“最终检测结果”联系起来:

从这个角度看,YOLOv4 的很多改进都很“工程化”:它不一定每一步都足够戏剧性,但每一步都在减少实际系统里的摩擦点。
Bag of Freebies:为什么训练配方本身就是模型设计的一部分
Mosaic:YOLOv4 最具代表性的训练技巧
YOLOv4 最出圈的训练技巧之一就是 Mosaic。它把 4 张图像拼接成一张训练样本,同时保留四张图中的目标与背景。这样做会显著改变训练样本的统计结构,让模型在一次前向传播里接触到更多场景、更多目标尺度和更复杂的上下文组合。
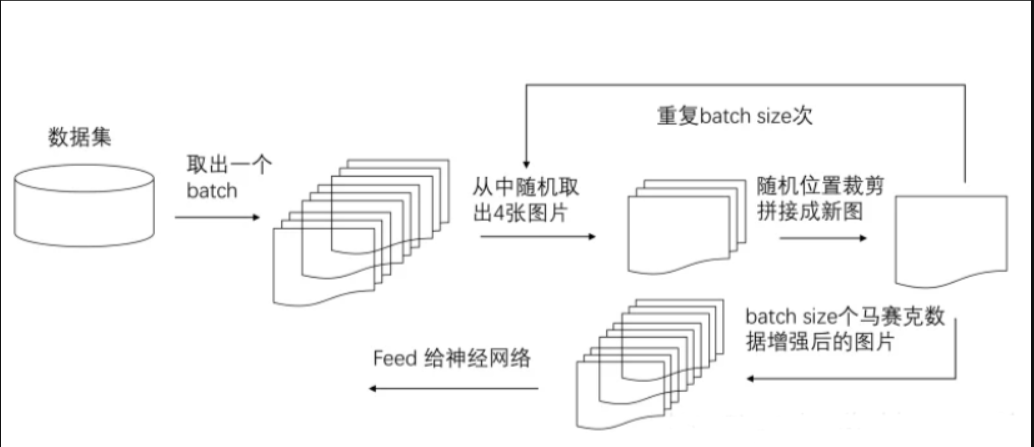
Mosaic 的收益主要体现在三点:
- 提升样本多样性:模型一次就能看到更多背景与布局组合;
- 改善小目标学习:拼接后的目标尺度分布更丰富,小目标更容易频繁出现;
- 减轻对大 batch 的依赖:在算力有限时也能让单次迭代看到更复杂的数据组合。
这一步很能体现 YOLOv4 的方法论:很多性能增益,并不一定要从更重的网络里挤出来,也可以从更聪明的数据组织方式里获得。
除了 Mosaic,BoF 还整理了哪些收益来源
YOLOv4 的 BoF 不是单个技巧,而是一套组合拳。常被一起讨论的还有:
- SAT(Self-Adversarial Training):先让模型“攻击”输入,再让模型学会在扰动下保持识别能力;
- Label Smoothing:缓解分类过度自信,提高泛化;
- DropBlock:用结构化方式丢弃连续区域,抑制过拟合;
- CmBN:在小 batch 条件下改善归一化稳定性;
- Cosine Scheduler 与 Random Shapes:分别服务于更平滑的优化过程与更强的尺度鲁棒性。
这些技巧单独看并不都属于 YOLOv4 首创,但 YOLOv4 的重要性恰恰在于:它把这些经验整理成了一个能够被整体复用的训练配方。
定位与后处理:YOLOv4 为什么能把框回归做得更准
CIoU Loss:不只看重叠面积,还关心位置与形状
YOLOv4 在边界框回归上使用 CIoU Loss。相比只关注框重叠程度的损失,CIoU 同时考虑了三类信息:
- IoU:预测框与真实框的重叠程度;
- 中心点距离:预测框中心是否真的向真实目标靠近;
- 宽高比一致性:框的形状是否接近目标本身。
其典型形式可以写为:
其中 与 分别表示预测框与真实框的中心, 表示两者中心距离, 表示最小外接矩形对角线长度, 用于衡量宽高比一致性。
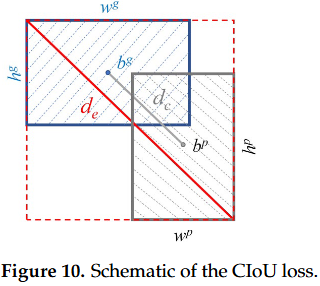
这一步非常关键,因为检测任务里的“框回归”并不是单纯把 IoU 拉高就够了。若两个框重叠不多但中心方向是对的,模型其实已经在往正确方向收敛;若中心距离不远但宽高比差得很大,定位质量也仍然不足。CIoU 的价值就在于:它把这些几何直觉更直接地编码进了训练目标。
DIoU-NMS:后处理也在追求更合理的几何判断
YOLOv4 在后处理上引入 DIoU-NMS。它的直觉和 CIoU 类似:当多个候选框彼此接近时,仅仅看重叠面积并不总是足够,中心点距离也能提供重要信息。
这对遮挡场景和密集目标尤其重要,因为普通 NMS 有时会把两个本来相邻但不同的目标误当成重复框。DIoU-NMS 的意义就在于:让“去重”这件事不只看 overlap,也看几何关系是否真的足够接近。
性能、优势、局限与历史位置
为什么 YOLOv4 会成为一个时代坐标
YOLOv4 最打动人的地方,不是某一项指标单独冲得有多高,而是它把实时检测器第一次带到了一个更均衡的工作点:
- backbone 更强,但没有把计算预算无限推高;
- neck 更完整,小目标与多尺度特征融合更扎实;
- 训练配方被系统化,普通硬件条件下也更容易训出有效模型;
- 回归与后处理都更关注几何质量,而不只是粗略给框。
可以把 YOLOv4 的主要优势概括为下表:
| 优势 | 说明 |
|---|---|
| 结构整合能力强 | CSPDarknet53、SPP 与 PAN 形成了较完整的特征提取与融合链路 |
| 训练收益体系化 | BoF 把很多过去分散的技巧整理成可复用配方 |
| 定位质量更好 | CIoU Loss 与 DIoU-NMS 让几何建模更细致 |
| 工程可达性高 | 在普通 GPU 上也能获得很强的速度—精度平衡 |
| 历史位置清晰 | 是经典 anchor-based 实时检测器的一次峰值整合 |
它的局限也同样清楚
不过,YOLOv4 并不是没有边界。它的局限主要来自它仍然站在当时那条主线上:
| 局限 | 根源 |
|---|---|
| 仍然依赖 anchor 机制 | 先验框设计、匹配逻辑和超参数仍会影响训练与迁移 |
| 结构逐步变重 | 虽然速度很强,但整套系统已经比早期 YOLO 明显更复杂 |
| 训练配方高度经验化 | 很多收益依赖组合调参,理解和复现成本并不低 |
| 后续范式开始转向 | anchor-free、解耦头与更统一的工程框架很快成为下一阶段重点 |
也正因为如此,YOLOv4 在历史中的位置非常有代表性:它更像是经典 anchor-based 检测器路线的一次集大成,而不是最终终点。后来的 YOLOv5、YOLOv8 并不是简单否定它,而是在不同方向上继续推进——前者更偏完整工程工作流,后者则进一步走向 anchor-free 与统一多任务框架。
一个简化配置片段,帮助快速把结构串起来
如果把 YOLOv4 的主线压缩成一个非常简化的配置骨架,它大致可以写成这样:
backbone:
- CSPDarknet53
neck:
- SPP(pool_sizes=[5, 9, 13])
- PAN(top_down=true, bottom_up=true)
head:
- Detect(scale=76x76, anchors=3)
- Detect(scale=38x38, anchors=3)
- Detect(scale=19x19, anchors=3)
training:
- Mosaic
- SAT
- DropBlock
- LabelSmoothing
- CmBN
- CIoU Loss
- DIoU-NMS这段骨架最能说明 YOLOv4 的气质:它不是靠某个模块孤军奋战,而是靠一套彼此配合的系统设计共同抬高性能。
总结
如果说 YOLOv3 代表的是多尺度实时检测走向成熟,那么 YOLOv4 代表的就是:实时检测器开始把结构升级、训练技巧和定位优化真正整合成一个工程体系。它最重要的贡献,不只是把指标继续往前推,而是让更多人意识到,模型性能的上限往往来自整条链路的共同优化,而不是单个模块的孤立创新。
从历史位置看,YOLOv4 是理解现代目标检测演化的一块关键拼图。它既总结了经典 anchor-based 检测器怎样被做强,也为后来的工程化工作流与新检测范式,留下了非常清晰的过渡路径。
参考资料
- Alexey Bochkovskiy, Chien-Yao Wang, Hong-Yuan Mark Liao. YOLOv4: Optimal Speed and Accuracy of Object Detection.
- Chien-Yao Wang, Alexey Bochkovskiy, Hong-Yuan Mark Liao. CSPNet: A New Backbone that Can Enhance Learning Capability of CNN.
- Tsung-Yi Lin et al. Feature Pyramid Networks for Object Detection.
- Shu Liu et al. Path Aggregation Network for Instance Segmentation.
- Zhaohui Zheng et al. Distance-IoU Loss: Faster and Better Learning for Bounding Box Regression.
- Joseph Redmon, Ali Farhadi. YOLOv3: An Incremental Improvement.