YOLOv5 由 Ultralytics 在 2020 年开源发布。它和 YOLOv1、YOLOv2、YOLOv3 这类以论文为核心载体的版本不太一样:YOLOv5 更像一个围绕实际训练、推理、部署流程持续演化的工程化实现,而不只是一次单点结构创新。也正因为这一点,它在很多讨论里总会伴随一个有点特殊的问题——它到底算不算“正统版本”的一次方法突破,还是一次把已有设计真正做得更可用的系统整合。
如果把它放回目标检测的发展脉络里看,YOLOv5 最重要的价值,其实不在于它重新发明了某个全新的检测范式,而在于它把实时检测器这条已经被证明有效的主线,用更统一、更工程化的方式重新组织了起来:PyTorch 训练链路、更容易落地的模型缩放、围绕小目标与泛化能力优化的数据增强、对 backbone / neck / head 的更稳定实现,以及围绕导出部署建立起来的完整工具链。这让它不只是“一个模型”,而更像一套可以直接进入项目流程的检测框架。
从后来的视角回看,YOLOv5 的影响力也不只是“很多人用过它”这么简单。真正关键的是,它让 YOLO 系列第一次在更大范围内摆脱了“模型结构图”的单一理解,转而被更多人当成一套可训练、可调参、可导出、可部署的完整工作流来使用。也正因为这一步做得足够彻底,YOLOv5 才会在工业界和开源社区里同时拥有远超它“是否有正式论文”这一问题本身的存在感。

问题背景与方法动机
到了 YOLOv4 所在的时间点,实时检测器已经不再需要回答“one-stage detector 能不能做”这个问题。真正更现实的问题变成了另一件事:怎样把已经有效的检测结构,做成一个更容易训练、更容易调参、更容易部署、也更容易被工程团队接住的系统。
从这个角度看,YOLOv5 想解决的并不是单一结构瓶颈,而是整条落地链路上的摩擦:
- 训练实现门槛偏高:很多模型结构能跑通,但训练、增强、超参数调整并不友好;
- 部署场景越来越碎片化:不只是服务器推理,还要考虑 ONNX、TensorRT、TFLite、CoreML 等导出路径;
- 不同算力设备需要不同规模模型:一个固定容量的模型不再足够;
- 小目标、复杂场景与数据有限时的泛化:需要更成熟的数据增强和训练策略来支撑;
- 研究代码与工程代码之间的断层:很多设计在论文里成立,但在实际项目里未必足够顺手。
因此,YOLOv5 的关键判断可以概括成一句话:实时检测器下一步的竞争,不只是再追一点结构指标,而是把模型本体、训练策略和部署能力一起做成可复用的工程系统。
下面这张表可以快速定位 YOLOv5 相对 YOLOv4 一类方案更强调的方向:
| 维度 | YOLOv4 一类代表思路 | YOLOv5 更强调的方向 |
|---|---|---|
| 主要载体 | 论文 + Darknet 语境 | PyTorch 工程实现 |
| 核心关注点 | 结构技巧堆叠与精度/速度平衡 | 训练、推理、部署全链路可用性 |
| 模型组织 | 固定主模型为主 | n/s/m/l/x 与 6 系列多尺度版本 |
| 训练增强 | 丰富增强策略 | Mosaic、AutoAnchor、多尺度训练等工程化集成 |
| 部署 | 需要额外适配 | 导出链路更完整 |
| 实际影响 | 推动实时检测精度上探 | 推动 YOLO 成为更通用的工业工作流 |
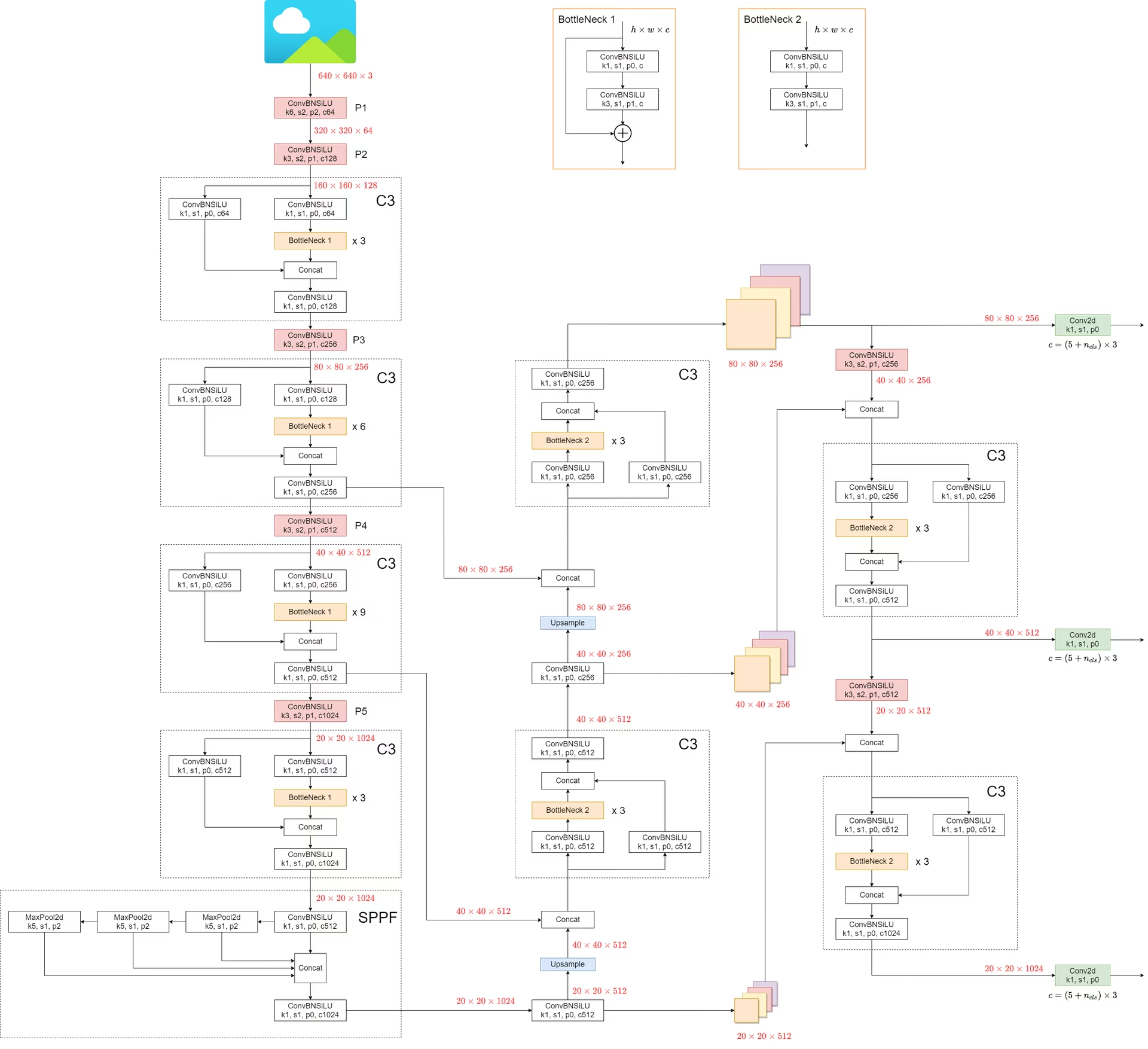
YOLOv5 的整体结构:先看数据怎么流动
如果只记一句话,我更建议把 YOLOv5 记成下面这条主线:输入图像先在 backbone 里逐步下采样并提取语义特征,再在 neck 里做跨尺度融合,最后由 detect head 在多个尺度上同时输出边界框、置信度和类别预测。
把这条路径压缩成结构图,可以写成:
Input
→ Stem(早期是 Focus,后期更多用 6×6 Conv)
→ CSPDarknet Backbone(Conv + C3 + Downsample)
→ SPPF(扩大感受野)
→ PAN-FPN Neck(Upsample + Concat + C3 + Downsample)
→ Detect Head(P3 / P4 / P5 三尺度预测)这个顺序很重要,因为它对应了 YOLOv5 每一部分真正负责的任务:
- Backbone 解决“从图像里抽什么特征”;
- Neck 解决“不同尺度的特征怎样交换信息”;
- Head 解决“怎样把特征变成检测框与类别分数”。
也就是说,YOLOv5 的结构并不是把模块胡乱堆在一起,而是按“特征提取 → 特征融合 → 预测解码”这个非常清晰的流水线来组织的。
从代码视角看,YOLOv5 在拼什么
如果把源码里的模块装配逻辑简化成伪代码,大致可以写成这样:
x = stem(x)
feat3, feat4, feat5 = backbone(x)
feat5 = sppf(feat5)
p4 = c3(torch.cat([upsample(feat5), feat4], dim=1))
p3 = c3(torch.cat([upsample(p4), feat3], dim=1))
n4 = c3(torch.cat([downsample(p3), p4], dim=1))
n5 = c3(torch.cat([downsample(n4), feat5], dim=1))
pred_small, pred_medium, pred_large = detect([p3, n4, n5])这段伪代码已经把 YOLOv5 最核心的结构关系暴露出来了:
backbone(x)输出多层特征图;sppf(feat5)在最高层语义特征上扩大感受野;upsample + concat把高层语义送回高分辨率特征;downsample + concat再把浅层细节反向送回低分辨率特征;detect([...])在三个尺度上同时做预测。
所以理解 YOLOv5,最有效的方法不是死记每个模块名字,而是先抓住它的特征流:先抽象,再融合,最后分别在小中大目标尺度上解码。
Backbone:CSPDarknet 到底在做什么
YOLOv5 的 backbone 延续了 CSPDarknet 主线。它不是单纯把卷积层堆得更深,而是试图在表达能力、计算量、显存占用和梯度传播之间取得更均衡的结果。
Backbone 的基本组成
如果从结构上拆开,YOLOv5 的 backbone 基本可以看成四类模块反复组合:
- Stem:把原始图像变成第一层可用特征;
- Stride-2 Conv:逐步下采样,让感受野变大;
- C3:做主干特征提取与残差式信息流组织;
- SPPF:在 backbone 末端做多尺度上下文聚合。
它的工作节奏其实很规律:每下一次采样,空间分辨率减半,通道语义更强;每经过一组 C3,网络就会在当前尺度上进一步提炼特征。
C3 模块为什么是 backbone 的核心
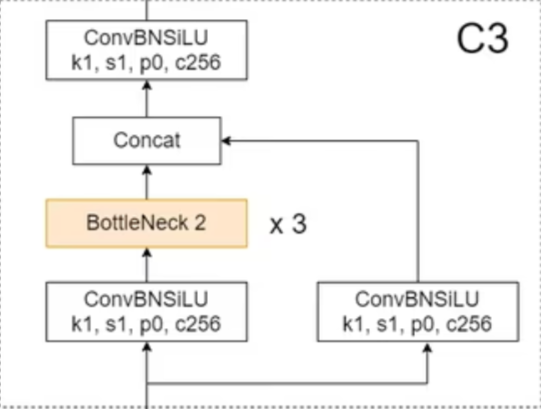
YOLOv5 里最值得真正看懂的模块,不是名字最显眼的 Focus,而是 C3。因为 backbone 大部分特征建模能力,都是靠它来完成的。
C3 的关键思想,是把输入特征拆成两路:
- 一路进入多个
Bottleneck,走更“重”的变换路径; - 一路保留为旁路,走更“轻”的直连路径;
- 最后把两路结果
concat后再卷积融合。
为了让后面的 Bottleneck、C3 和 Focus 代码更自洽,可以先看 YOLOv5 里最常见的基础卷积模块 Conv。它本质上就是 Conv2d + BatchNorm2d + 激活函数 的组合封装:
class Conv(nn.Module):
def __init__(self, c1, c2, k=1, s=1, p=None, g=1, act=True):
super().__init__()
padding = k // 2 if p is None else p
self.conv = nn.Conv2d(c1, c2, k, s, padding, groups=g, bias=False)
self.bn = nn.BatchNorm2d(c2)
self.act = nn.SiLU() if act else nn.Identity()
def forward(self, x):
return self.act(self.bn(self.conv(x)))这个 Conv 虽然看起来简单,但它在 YOLOv5 里几乎无处不在,因为它统一了三个动作:
- 用卷积做通道变换或空间混合;
- 用
BatchNorm稳定训练; - 用
SiLU增强非线性表达。
也正因为这个基础块足够统一,后面的 Bottleneck、C3、SPPF 前后卷积,甚至早期 Focus 模块里的卷积部分,都可以复用同一种写法。
先看 C3 里被反复堆叠的 Bottleneck。它本质上是一个“1×1 调整通道 + 3×3 做空间混合 + shortcut 残差相加”的小单元:
class Bottleneck(nn.Module):
def __init__(self, c1, c2, shortcut=True, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c_, c2, 3, 1)
self.add = shortcut and c1 == c2
def forward(self, x):
y = self.cv2(self.cv1(x))
return x + y if self.add else y这段 Bottleneck 可以先这样理解:
cv1先用1×1卷积做通道压缩或调整;cv2再用3×3卷积完成主要的空间特征提取;self.add控制是否保留 shortcut;- 如果输入输出通道一致,就把变换后的结果与原输入直接相加。
也就是说,Bottleneck 负责的是在不过度增加计算成本的前提下,完成一轮有效的局部特征变换;而 C3 做的事情,则是把这类变换放进 CSP 分流框架里,变成更大的主干模块。
对应到代码,可以看成下面这个结构:
class C3(nn.Module):
def __init__(self, c1, c2, n=1, e=0.5):
super().__init__()
c_ = int(c2 * e)
self.cv1 = Conv(c1, c_, 1, 1)
self.cv2 = Conv(c1, c_, 1, 1)
self.m = nn.Sequential(*(Bottleneck(c_, c_) for _ in range(n)))
self.cv3 = Conv(2 * c_, c2, 1)
def forward(self, x):
return self.cv3(torch.cat((self.m(self.cv1(x)), self.cv2(x)), 1))这段代码特别适合用来理解 C3 的结构本质:
cv1(x)是进入主分支的那一路;self.m(...)表示这一支上会串联若干个 Bottleneck;cv2(x)是相对更轻的旁路分支;torch.cat(..., 1)把两路特征按通道维拼接;cv3(...)再把拼接后的结果压回目标通道数。
因此,C3 的价值不是“比残差块多一点花样”,而是它把 CSP 的分流思想具体落成了一个可复用模块:一部分通道做充分变换,一部分通道保留更直接的信息流,最后再统一融合。这样既保留了特征表达能力,又避免所有通道都走高成本路径。
下采样层在 backbone 里负责什么
很多文章提 backbone 时只会说“有几层卷积”,但真正需要理解的是 stride-2 卷积的作用。它不是简单把特征图变小,而是在做两件事:
- 压缩空间分辨率,让后续计算成本可控;
- 扩大感受野,让网络逐步看到更大范围的上下文。
所以 backbone 的层级不是随意变深,而是在不断把“高分辨率细节”转换成“低分辨率但更强语义”的表示。后面 neck 要做的,其实就是把这两种信息重新接回来。
Focus 与 SPPF:两个最能体现工程取向的模块
如果说 C3 体现的是 YOLOv5 对 backbone 主线的整理,那么 Focus 与 SPPF 更像是它“写给工程实践看”的两个模块:一个关注前端输入怎么更紧凑地下采样,一个关注高层语义特征怎么更便宜地扩大感受野。
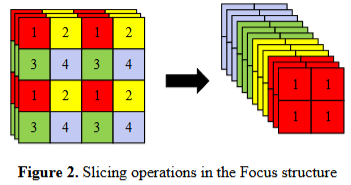
Focus:先把空间切片,再送进卷积
YOLOv5 早期版本里的 Focus 很有代表性。它会先对输入图像做切片,把原来分布在空间维的信息重排到通道维,再接卷积层。
可以用一个简化版本理解它:
class Focus(nn.Module):
def __init__(self, c1, c2):
super().__init__()
self.conv = Conv(c1 * 4, c2, 3, 1)
def forward(self, x):
patches = torch.cat(
[x[..., ::2, ::2], x[..., 1::2, ::2], x[..., ::2, 1::2], x[..., 1::2, 1::2]],
dim=1,
)
return self.conv(patches)这段代码的关键点只有一个:它不是直接用 stride=2 卷积做下采样,而是先把相邻像素块重新排布到通道维,再让卷积去处理。于是你可以把它理解成“带信息重排的下采样 stem”。
这种做法的直观收益是:
- 更早压缩空间分辨率;
- 尽量保留局部邻域信息;
- 让后续 backbone 计算更紧凑。
不过官方后续也明确把 Focus 替换成了更高效的 6×6 Conv2d。这恰好说明 YOLOv5 的判断标准非常务实:模块不是因为有名才保留,而是因为在实际实现里更快、更稳、更好维护才保留。[Ultralytics, 2026, Architecture Description]
SPPF:用串行池化近似更大的池化核
SPPF 是另一个非常典型的工程化设计。它的目标没有变,仍然是聚合多尺度上下文、扩大感受野;它变化的地方,是实现方式更省。
官方文档里可以把它概括成下面这个形式:
class SPPF(nn.Module):
def __init__(self):
super().__init__()
self.maxpool = nn.MaxPool2d(5, 1, padding=2)
def forward(self, x):
y1 = self.maxpool(x)
y2 = self.maxpool(y1)
y3 = self.maxpool(y2)
return torch.cat([x, y1, y2, y3], dim=1)这段实现的妙处在于:不用并行放三个不同核大小的池化层,而是重复使用同一个 5×5 MaxPool,依次得到近似更大感受野的特征。所以它保留了 SPP 那种多尺度上下文聚合能力,同时减少了实现和推理上的额外开销。
这也是为什么官方会专门给出 SPP 与 SPPF 的速度比较代码:重点不是说 SPP 不好,而是说在 YOLOv5 这类实时检测系统里,功能接近时,更快的实现往往就是更好的实现。[Ultralytics, 2026, Architecture Description]
Neck 与 Head:多尺度信息到底怎样流到预测层
只理解 backbone 还不够,因为检测任务最终不是分类。YOLOv5 必须把“高层语义”和“低层定位”一起送到预测层,所以 neck 和 head 才是真正把检测闭环补完整的部分。
Neck:先上采样融合,再下采样回流
YOLOv5 的 neck 沿用了 FPN + PAN 组合思路,但理解它最好的方式不是背名字,而是直接看信息怎么流:
- 自顶向下:把高层语义特征上采样,和浅层高分辨率特征拼接;
- 自底向上:再把融合后的浅层特征逐级下采样,反向送回更深层;
- C3 整合:每次
concat之后,都通过 C3 重新整理拼接后的特征。
把这个过程写成代码,比结构图更容易看懂:
p4 = c3(torch.cat([upsample(feat5), feat4], dim=1))
p3 = c3(torch.cat([upsample(p4), feat3], dim=1))
n4 = c3(torch.cat([downsample(p3), p4], dim=1))
n5 = c3(torch.cat([downsample(n4), feat5], dim=1))这里每一步都对应一个非常明确的目的:
upsample(...):把高层语义送到更高分辨率层;torch.cat([...], dim=1):把不同来源的特征沿通道维拼接;c3(...):重新融合拼接后的语义与定位信息;downsample(...):把浅层细节再反向带回更深层。
所以 neck 的本质并不是“多接几条线”,而是让深层知道更多细节,让浅层带上更多语义。这对小目标检测尤其重要,因为小目标最怕的就是:分辨率不够时细节丢了,语义不够时又认不出来。
Head:为什么仍然是三尺度预测
YOLOv5 的 detect head 并没有故意追求特别新奇的设计,而是继续沿用 anchor-based、多尺度输出这条已经被证明有效的路线。通常它会在三层特征图上分别预测:
- P3:负责更小目标;
- P4:负责中等目标;
- P5:负责更大目标。
如果输入尺寸是常见的 640×640,那么这三层通常可以粗略对应成:
80×80网格,stride≈8;40×40网格,stride≈16;20×20网格,stride≈32。
这背后的意思非常直接:越高分辨率的特征图,越适合看小目标;越低分辨率但语义更强的特征图,越适合看大目标。所以三尺度预测并不是历史包袱,而是 one-stage detector 在精度和效率之间非常关键的平衡点。
如果写成接口形式,可以理解成:
pred_small, pred_medium, pred_large = detect([p3, n4, n5])Detect 头的输出张量到底长什么样
真正理解 head,关键不是只知道“它会输出框”,而是知道它在每个网格位置到底预测了什么。
按照 Ultralytics 的实现思路,每个尺度的卷积输出先会被整理成类似这样的形状:
x = self.m[i](x)
bs, _, ny, nx = x.shape
x = x.view(bs, self.na, self.no, ny, nx).permute(0, 1, 3, 4, 2).contiguous()这里最重要的几个维度是:
na:每个尺度上的 anchor 数量,YOLOv5 常见配置是每层3个;ny, nx:当前特征图的网格高宽;no:每个 anchor 预测的输出维度,通常是nc + 5。
其中这个 5 指的是:
x, y:框中心;w, h:框宽高;obj:目标置信度。
如果是 COCO 这类 80 类数据集,那么 no = 85。也就是说,每个网格位置上的每个 anchor,都会输出一整组“位置 + 置信度 + 类别”的预测向量。
这时如果从张量视角去看 YOLOv5 的 head,本质上就是:在三张不同分辨率的特征图上,对每个网格、每个 anchor 同时做一个小型回归 + 分类任务。
Grid、Anchor 和 Stride 是怎么把预测变成真实框的
head 的原始输出并不是最终可以直接画在图上的边界框。它还需要结合 grid、anchor 和 stride 做一次解码。
Ultralytics 的实现可以概括成下面这段:
xy, wh, conf = x.sigmoid().split((2, 2, self.nc + 1), dim=4)
xy = (xy * 2 + grid) * stride
wh = (wh * 2) ** 2 * anchor_grid
y = torch.cat((xy, wh, conf), dim=4)这里几项分别在做什么:
grid:告诉模型“你现在处在哪个网格单元”;stride:把特征图坐标映射回输入图像坐标;anchor_grid:提供当前尺度的先验框宽高;sigmoid():把网络输出压到更稳定的数值范围,再做后续变换。
可以这样直观理解:
xy先学的是相对当前网格的位置偏移;wh学的是相对 anchor 尺寸的缩放;- 再乘上
stride之后,预测框才回到输入图像的像素尺度上。
这也是 YOLOv5 仍然属于 anchor-based 检测器的关键原因:它不是直接从零生成框,而是从“网格位置 + 先验框”出发,去学习偏移和缩放。
为什么这种 head 设计在工程上仍然成立
从今天回看,YOLOv5 的 detect head 也许不是最“新”的头部设计,但它有一个非常现实的优点:结构稳定、实现成熟、和多尺度特征融合链路配合顺畅。
每个尺度上的检测头,本质上都在输出三类信息:
- 边界框位置;
- 目标置信度;
- 类别概率。
因此,YOLOv5 的 head 虽然看起来“变化不大”,但这恰恰反映了它的成熟:真正有用的部分,不一定是重新发明预测头,而是让 backbone、neck、anchor 和训练策略配合得更稳。换句话说,YOLOv5 的结构优化重点,并不在于把 head 彻底改写,而在于让整条检测流水线的每一段都更均衡。
如果只看网络结构,YOLOv5 的重要性还不算完全说清。它真正和很多前代拉开差异的地方,在于训练与数据层面的工程化组织。
Mosaic:提升小目标与场景多样性
YOLOv5 广为人知的一点,是把 Mosaic 增强真正做成了主线配置之一。它通过把 4 张图像拼接到同一训练样本中,同时改变目标尺度、上下文和布局关系。
这一步的意义非常直接:
- 增加同一张训练图中的目标多样性;
- 让小目标在训练中更频繁出现;
- 改善模型对复杂场景和不同尺度目标的泛化。
对实时检测器来说,这类增强不是锦上添花,而常常会直接决定模型在真实数据上的鲁棒性。
AutoAnchor:让 anchor 更贴近数据集
YOLOv5 保留了 anchor-based 检测框架,但它不满足于固定先验框直接开训,而是加入了 AutoAnchor 机制,在训练前检查并优化 anchor 与数据集分布的匹配程度。
这件事的重要性在于:anchor 设计从“手工经验参数”进一步变成了更自动化的数据适配环节。对于不同目标尺寸分布差异很大的数据集,这能显著降低一开始就用错先验框的风险。
多尺度训练、EMA 与混合精度
官方文档还把多尺度训练、EMA、warmup、cosine 学习率、混合精度、超参数进化等训练机制都系统纳入了工作流。这些内容单独看可能都不是 YOLOv5 独有,但把它们整合成默认可用、相互配合的一整套实践,本身就是 YOLOv5 的价值所在。
换句话说,YOLOv5 让很多团队第一次感受到:目标检测不只是“模型结构图”,更是一套从数据增强到训练稳定性再到部署导出的完整工程系统。
模型缩放与版本体系:从单一模型走向模型家族
YOLOv5 另一个非常关键的特征,是它不再把“一个模型”当成唯一交付形态,而是明确提供多个规模版本。
常见的 YOLOv5 家族包括:
n/s:更轻量,适合更紧张的延迟与算力预算;m:在速度与精度之间取中间平衡;l/x:在算力允许时追求更高精度;n6/s6/m6/l6/x6:面向更大输入分辨率场景。
这种组织方式的价值很大,因为它把“速度-精度权衡”从事后手工裁剪,变成了一开始就纳入产品化设计的一部分。工程团队面对的就不再是“先训一个模型,再想办法压缩”,而是可以直接在模型家族里选择更合适的工作点。
从历史视角看,这一步意味着 YOLO 不再只是一个检测算法名称,而逐渐演化为一套可以按硬件条件、时延预算和精度需求灵活选型的产品化模型体系。
部署与生态:YOLOv5 为什么传播得更快
YOLOv5 能快速流行,一个很现实的原因是它在“最后一公里”上做得更完整。Ultralytics 仓库强调的不只是训练结果,还包括:
- 用 PyTorch Hub 快速加载模型;
- 导出到 ONNX、TensorRT、CoreML、TFLite 等格式;
- 支持图像、视频、摄像头、流媒体等多种推理输入;
- 支持单卡、多卡训练,以及更系统的训练/验证脚本。
这类能力看起来不像论文里最显眼的“创新点”,却往往决定了一个模型是否会被大量项目真正采用。因为对很多实际团队来说,真正困难的并不只是“训出一个不错的 checkpoint”,而是如何把这个 checkpoint 顺利接入现有系统。
从这个意义上说,YOLOv5 的影响力不仅来自检测性能,也来自它显著降低了把 YOLO 接到真实产品流程中的摩擦成本。
YOLOv5 的优势、局限与历史位置
优势
| 优势 | 说明 |
|---|---|
| 工程可用性强 | PyTorch 实现、训练脚本、推理脚本与导出链路更完整 |
| 模型家族清晰 | n/s/m/l/x 与更大输入版本便于按场景选型 |
| 训练策略成熟 | Mosaic、AutoAnchor、多尺度训练、EMA 等提高泛化与稳定性 |
| 结构组织均衡 | CSP/C3、SPPF、PAN/FPN 式融合让速度与效果保持较好平衡 |
| 部署生态完善 | 更容易连接 ONNX、TensorRT、TFLite、CoreML 等实际环境 |
局限
| 局限 | 根源 |
|---|---|
| 并非一次全新检测范式突破 | 更多是对已有 YOLO 主线的工程化整合与强化 |
| 仍然保留 anchor-based 负担 | anchor 匹配、先验框设计与标签分配仍有限制 |
| 版本语义容易被混淆 | 它的影响力很大,但并不对应一篇传统意义上的正式论文 |
| 后续架构仍会继续演化 | Focus 等设计本身也在后续实现中被替换,说明并非终局方案 |
历史位置
YOLOv5 最重要的意义,不在于它像 YOLOv1 那样重新定义了任务,也不在于它像 YOLOv3 那样明确完成了一次结构分水岭。它更像一个非常关键的工程节点:它让 YOLO 从“系列模型”进一步变成了“系列工作流”。
也就是说,YOLOv5 的影响力很大程度上并不是靠某一个模块名字支撑起来的,而是靠它把训练、增强、模型缩放、推理和导出这些本来分散的事情,组织成了一个更顺滑的整体。这也是为什么很多人第一次真正大规模上手 YOLO,不是从更早的论文版本开始,而是从 YOLOv5 开始。
如果说 YOLOv3 代表的是“成熟实时检测器”的到来,那么 YOLOv5 更像是成熟实时检测器开始真正进入大规模工程落地阶段。
总结
YOLOv5 并没有推翻 YOLO 的基本路线,但它把这条路线进一步做成了一套更完整、更可部署、更贴近工程现实的系统。
如果把它的核心贡献概括成三点,可以写成:
- 用更成熟的 PyTorch 实现和训练工作流,降低了实时检测器的落地门槛;
- 用 CSP/C3、SPPF、PAN/FPN 式特征融合,把已有检测主线整理得更均衡;
- 用模型缩放、数据增强和导出生态,把 YOLO 从单一模型推进成更完整的工程框架。
YOLOv5 的历史地位,更多来自它在“工程化”三个字上的完成度。它未必是 YOLO 系列里最具有论文式革命感的一版,却极大改变了很多人真正使用实时检测器的方式。也正因为它把训练、推理和部署之间的链路打通得更顺,后续版本才会进一步沿着更强结构、更灵活任务支持和更完善生态继续演进。