在农业虫害检测场景中,直接套用通用目标检测器往往并不理想。问题通常不在于基线模型“不够大”,而在于任务本身具有非常鲜明的特征:目标尺寸小、背景干扰多、尺度变化大,而且数据规模通常有限。在这种前提下,盲目增加模型容量未必会稳定提升效果,反而可能带来更强的过拟合风险和更高的部署成本。
更有效的路线,往往是在成熟基线之上做定向增强。这篇文章讨论的思路,正是以 YOLOv5s 为基础,不推翻原有检测框架,而是围绕特征提取、边界框回归和多尺度上下文建模三个环节做补强,让模型更适合处理复杂背景下的细粒度虫害目标。

问题背景与动机
YOLOv5s 本身已经是一个速度、精度与部署友好性之间相对均衡的轻量级检测器。但在叶片虫害识别中,它仍然会遇到三个典型问题。
第一,背景复杂,细粒度病灶容易被淹没。虫害区域通常只占据图像的一小部分,真正有判别意义的往往只是局部孔洞、潜叶轨迹或纹理破坏,而图像中同时还存在泥土、杂草、叶脉反光和复杂光照等大量无关信息。普通卷积会把这些背景一并编码进特征图,导致关键病灶的响应不够突出。
第二,小目标和尺度变化使边界框回归更难。对于小虫斑或细微损伤,预测框只要稍微偏移,IoU 就会出现明显波动。如果损失函数在不同 IoU 区间上的梯度分配不够合理,模型就很难持续把框“修准”。
第三,虫害识别不仅要看局部,还要看上下文。很多时候,一个斑点究竟是病灶、虫咬痕迹,还是普通纹理波动,并不能只靠局部区域判断,还要结合整片叶子的纹理结构、叶缘状态和周围区域关系。这意味着模型不仅要看清细节,还需要足够大的感受野。
因此,这类任务中最有价值的优化通常不是“把模型做大”,而是让检测器在原有轻量框架上做到三件事:看得更准、理解得更全、框得更稳。
核心思路:围绕 YOLOv5 的三处关键能力补强
从整体设计看,这套改进没有推翻 YOLOv5 的主干流程,而是沿着三条主线做增强:
- 在特征提取阶段加入 CBAM,抑制背景噪声,提升对病灶区域的关注能力;
- 在回归目标中引入 Alpha-IoU,改善边界框回归的梯度分配;
- 在高层特征建模中加入 ASPP,扩大感受野并增强多尺度上下文表达。
这三项改动分别对应 YOLOv5 检测流程中的三个层面:
| 优化模块 | 主要作用位置 | 直接面向的问题 | 主要收益 |
|---|---|---|---|
| CBAM | 特征提取阶段 | 背景杂、病灶小、局部纹理弱 | 提高特征选择性 |
| ASPP | 高层特征融合阶段 | 需要同时看局部与整体 | 增强多尺度上下文 |
| Alpha-IoU | 边界框回归目标 | 小目标框敏感、尺度变化大 | 提升定位精细度 |
如果用一句话概括,这三项改动分别负责:先把特征变干净,再把语义看完整,最后把定位学精细。

关键组件与机制详解
SE:只做通道重标定的轻量注意力
如果把注意力机制看成一个逐步增强的家族,那么最适合作为起点的是 SE(Squeeze-and-Excitation)。它的思想最直接:先把每个通道压缩成一个全局描述,再学习每个通道应该被放大还是压低。换句话说,SE 只回答一个问题——哪些通道更重要。
设输入特征为 ,SE 先通过全局平均池化完成 squeeze:
然后通过两层全连接或等价的 1 \times 1 卷积完成 excitation,得到通道权重:
最后再把权重重新乘回原始特征图,实现通道重标定。
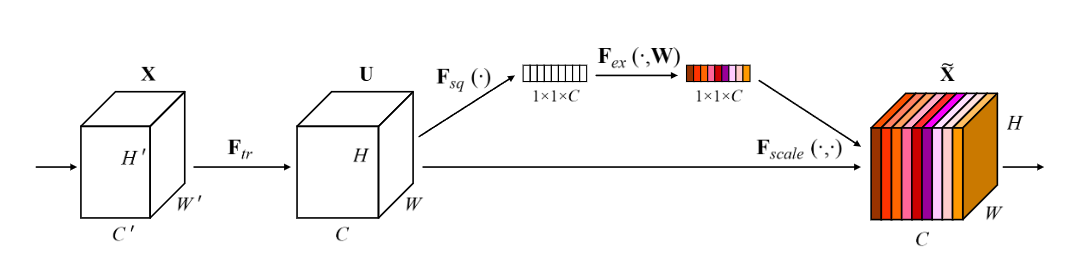
SE 的优点是结构非常轻,几乎不改变主干网络的基本拓扑;但它的局限也很明确:它只能回答“哪些通道重要”,却不能回答“图像中的哪些位置重要”。因此,它适合作为理解注意力机制的第一步,也适合作为轻量 backbone 的增强模块。
一个最小可读实现可以写成:
class SEModule(nn.Module):
def __init__(self, channels, reduction=16):
super().__init__()
hidden = max(channels // reduction, 1)
self.pool = nn.AdaptiveAvgPool2d(1)
self.fc = nn.Sequential(
nn.Conv2d(channels, hidden, kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(hidden, channels, kernel_size=1, bias=False),
nn.Sigmoid(),
)
def forward(self, x):
weight = self.fc(self.pool(x))
return x * weight从代码上看,SE 最短,也最容易理解,因为它完全聚焦在通道重标定上。也正因如此,它很适合用来表达一个非常清晰的设计目标:用极小的额外开销,让网络学会在通道维上重新分配注意力。
CBAM:从通道筛选进一步走到空间筛选
理解了 SE 之后,如果希望更快进入本文真正用到的注意力模块,那么最自然的下一步就是 CBAM。它的关键推进在于:不仅判断哪些通道重要,还显式判断图像中的哪些位置重要。也就是说,CBAM 把注意力建模从“通道重标定”进一步扩展成了“通道筛选 + 空间筛选”的两阶段过程。
对于叶片虫害图像,真正有判别意义的区域通常只占很小一部分。如果网络对所有位置、所有通道一视同仁,那么大量背景模式也会被当作重要特征编码进去。CBAM 的价值,就在于给特征流增加一个轻量级的“筛选器”:先判断哪些通道重要,再判断哪些空间位置重要。
设输入特征图为 ,CBAM 首先在空间维度上做全局平均池化和全局最大池化,再通过共享的 MLP 生成通道注意力权重:
进一步写开,可以表示为:
其中, 和 分别表示全局平均池化与最大池化结果, 是共享的 MLP 参数, 是 Sigmoid 激活函数。得到通道权重后,再将其与原始特征逐通道相乘:
下面这张图同时展示了 CBAM 的两个核心支路:上半部分是通道注意力,下半部分是空间注意力。可以把它理解成一个非常直观的两阶段过程:先根据全局池化结果学习“哪些通道更重要”,再根据通道聚合后的二维响应学习“哪些空间位置更重要”。
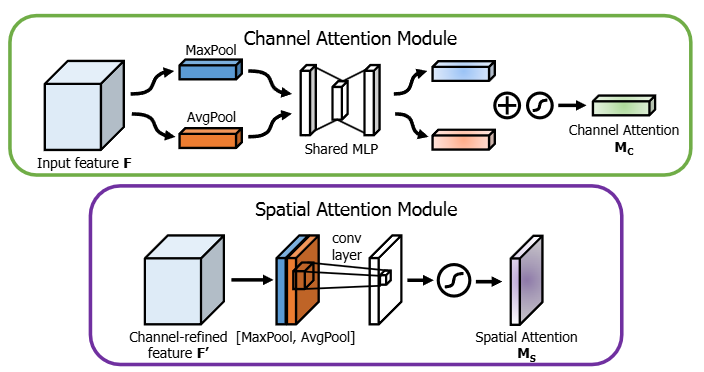
如果把上面的公式翻成更容易上手的 PyTorch 代码,通道注意力分支可以写成下面这样:
import torch
import torch.nn as nn
class ChannelAttention(nn.Module):
def __init__(self, channels, reduction=16):
super().__init__()
hidden = max(channels // reduction, 1)
self.avg_pool = nn.AdaptiveAvgPool2d(1)
self.max_pool = nn.AdaptiveMaxPool2d(1)
self.mlp = nn.Sequential(
nn.Conv2d(channels, hidden, kernel_size=1, bias=False),
nn.ReLU(inplace=True),
nn.Conv2d(hidden, channels, kernel_size=1, bias=False),
)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_weight = self.mlp(self.avg_pool(x))
max_weight = self.mlp(self.max_pool(x))
weight = self.sigmoid(avg_weight + max_weight)
return x * weight这段代码和前面的数学表达是一一对应的:AdaptiveAvgPool2d(1) 与 AdaptiveMaxPool2d(1) 对应全局池化,self.mlp 对应共享感知机,sigmoid(avg_weight + max_weight) 对应公式中的 。最后返回的 x * weight,就是把学到的通道权重重新乘回原始特征图。
完整的 CBAM 还会在通道注意力之后,再接一个 空间注意力 模块,去判断“图像中的哪些位置更重要”。空间注意力的思路与通道注意力不同:它不是沿通道维生成一个 的权重,而是沿通道维先做聚合,再在空间维生成一张 的注意力图。
对应的最小实现可以写成下面这样:
class SpatialAttention(nn.Module):
def __init__(self, kernel_size=7):
super().__init__()
padding = kernel_size // 2
self.conv = nn.Conv2d(2, 1, kernel_size=kernel_size, padding=padding, bias=False)
self.sigmoid = nn.Sigmoid()
def forward(self, x):
avg_map = torch.mean(x, dim=1, keepdim=True)
max_map, _ = torch.max(x, dim=1, keepdim=True)
spatial_descriptor = torch.cat([avg_map, max_map], dim=1)
weight = self.sigmoid(self.conv(spatial_descriptor))
return x * weight这段代码的逻辑可以直接按张量形状理解:输入 x 的形状通常是 [B, C, H, W],先在通道维分别做平均池化和最大池化,得到两张 [B, 1, H, W] 的二维响应图;再把它们拼接成 [B, 2, H, W],交给一个卷积层去学习空间位置之间的相关性;最后通过 Sigmoid 得到一张 [B, 1, H, W] 的空间权重图,并重新乘回原始特征。
如果把通道注意力和空间注意力串起来,一个简化版的 CBAM 可以写成:
class CBAM(nn.Module):
def __init__(self, channels, reduction=16, kernel_size=7):
super().__init__()
self.channel_attention = ChannelAttention(channels, reduction)
self.spatial_attention = SpatialAttention(kernel_size)
def forward(self, x):
x = self.channel_attention(x)
x = self.spatial_attention(x)
return x再从整体数据流看,CBAM 并不是把两个模块并联堆在一起,而是把 通道注意力模块 和 空间注意力模块 串联起来:输入特征先经过通道重标定,再经过空间重标定,最终得到 refined feature。这也是它区别于只做单支路注意力方法的关键。
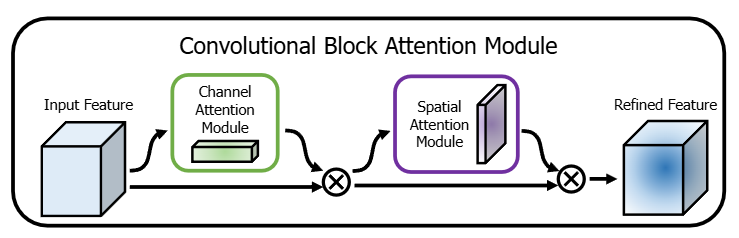
从 YOLOv5 的角度看,这类改动不是简单多加一个层,而是改变了前端特征流的分配方式。原来是“卷积后直接往后传”,现在变成“卷积后先做显著性筛选,再传递给后续 neck 和 head”。这对小目标尤其重要,因为小目标最容易被复杂背景淹没,而注意力机制正好提升了它们的特征信噪比。
CA:在通道注意力里保留方向位置信息
如果把 CBAM 看成“显式把空间筛选也纳入进来”,那么 CA(Coordinate Attention)可以看成另一条路线:它并不直接生成一张完整的二维空间注意力图,而是先对通道注意力做改造,沿高度方向和宽度方向分别做聚合,把位置信息以更轻量的方式带回注意力建模中。
传统的 SE 会把整张特征图压成全局描述向量,因此位置信息几乎全部丢失;CA 则会分别生成两条方向感知的描述:
其中, 保留了高度坐标, 保留了宽度坐标。随后,两条方向特征会先融合,再拆分成沿高和沿宽的两张注意力图,最后分别乘回原特征图。
这种设计的好处是,CA 兼顾了两件事:
- 像通道注意力一样轻量,因为它仍然以通道重标定为主;
- 比 SE 更保留位置感,因为它没有把空间信息一次性完全压扁。
对于虫害检测这类任务,CA 的吸引力在于:病灶往往不是随机分布在整张图中,而是依附在叶片边缘、叶脉附近或局部纹理异常区域。CA 通过把横向和纵向信息拆开建模,更容易保留“病灶大致在哪里”的线索。
一个简化版实现可以写成:
class CoordinateAttention(nn.Module):
def __init__(self, channels, reduction=32):
super().__init__()
hidden = max(channels // reduction, 8)
self.conv1 = nn.Conv2d(channels, hidden, kernel_size=1, bias=False)
self.bn1 = nn.BatchNorm2d(hidden)
self.act = nn.ReLU(inplace=True)
self.conv_h = nn.Conv2d(hidden, channels, kernel_size=1, bias=False)
self.conv_w = nn.Conv2d(hidden, channels, kernel_size=1, bias=False)
def forward(self, x):
identity = x
b, c, h, w = x.shape
x_h = torch.mean(x, dim=3, keepdim=True)
x_w = torch.mean(x, dim=2, keepdim=True).permute(0, 1, 3, 2)
y = torch.cat([x_h, x_w], dim=2)
y = self.act(self.bn1(self.conv1(y)))
a_h, a_w = torch.split(y, [h, w], dim=2)
a_w = a_w.permute(0, 1, 3, 2)
a_h = torch.sigmoid(self.conv_h(a_h))
a_w = torch.sigmoid(self.conv_w(a_w))
return identity * a_h * a_w如果说 SE 是“只看通道重要性”,CBAM 是“通道筛选 + 空间筛选”,那么 CA 可以理解为“带方向感的通道注意力”。它没有像 CBAM 那样显式生成完整二维显著图,但能用更轻量的方式把位置信息重新引入注意力建模中。
为了更直观看清这三类机制的差别,可以把它们压缩成下面这张对比表:
| 机制 | 核心思想 | 是否显式建模空间位置 | 计算开销 | 更适合的场景 |
|---|---|---|---|---|
| SE | 先全局池化,再学习通道权重 | 否 | 最低 | 只需要轻量通道重标定的 backbone 增强 |
| CBAM | 先做通道注意力,再做空间注意力 | 是 | 中等 | 背景复杂、目标局部且显著区域需要被突出 |
| CA | 分别沿高度与宽度聚合,再生成方向感知注意力 | 部分保留 | 低到中等 | 既希望轻量,又希望保留一定位置感的移动端或检测任务 |
如果按本文的讲解顺序去理解,也可以记成:SE 先建立“通道重标定”这个基本直觉;CBAM 进一步把空间筛选显式加进来;CA 则展示了另一种更轻量的折中方案,在不完全走向二维空间注意力的前提下,把方向位置信息重新带回来。
下面这张结构对照图把三者并排放在一起:左侧是 SE,中间是 CBAM,右侧是 CA。对照着看会更容易理解它们的差别:SE 只有通道重标定,CBAM 在通道之后再加空间筛选,而 CA 则把位置信息以方向感知的方式重新引回通道注意力里。
Alpha-IoU:从 IoU 到 CIoU,再到 Alpha-IoU
边界框回归损失可以简化理解为三步:IoU 看重叠,CIoU 补几何约束,Alpha-IoU 强化高质量预测框的精修。
最基础的是 IoU:
它只衡量预测框和真实框的重叠程度;一旦两者没有重叠,优化信号就会明显变弱。
因此,检测任务里更常见的是 CIoU。它在 IoU 之外继续考虑中心点距离和长宽比一致性,也就是不只问“重不重合”,还问“中心靠不靠近、形状像不像”。
在此基础上,Alpha-IoU 进一步在 IoU 项上做幂次重加权:
这里不必把重点放在每一项的记号上,更重要的是理解它想解决什么:当预测框已经比较接近正确答案时,仍然继续推动模型做更细的修正。这对小目标尤其重要,因为小目标框只要轻微偏移,IoU 波动就会很明显。
可以把三者的差别压缩成三句话:
- IoU:先看两个框有没有重叠;
- CIoU:再把中心距离和形状差异一起考虑进去;
- Alpha-IoU:让已经接近正确的框继续被认真修边。
从工程角度看,Alpha-IoU 的价值在于:几乎不增加部署成本,却能改变训练时的梯度分配,让定位学得更细。
虫害识别的一个难点在于,局部病灶往往需要结合整片叶子的上下文来判断。单看一个小斑点,有时很难区分它是虫咬痕迹、病斑,还是普通纹理变化。因此,模型不能只依赖局部卷积视野,还需要在不显著增加参数量的情况下拥有更大的感受野。
ASPP 的基础是空洞卷积。和普通卷积相比,二者最核心的区别在于:
- 普通卷积会连续采样相邻像素。比如
3 × 3卷积,就是紧挨着取一个3 × 3邻域; - 空洞卷积会在卷积核元素之间插入间隔。比如膨胀率
e = 2的3 × 3空洞卷积,实际覆盖范围会像5 × 5,但参数量仍然是3 × 3。
所以可以把它直观理解成:普通卷积是“密着看局部”,空洞卷积是“隔着看更大范围”。后者不会增加卷积核参数个数,却能让单层卷积直接看到更大的上下文。
下面这张图把两者放在一起对比:左侧是普通 3 × 3 卷积,右侧是膨胀率为 2 的空洞卷积。可以直观看到,卷积核参数个数没有变,但右侧单次操作覆盖到的输入范围更大。
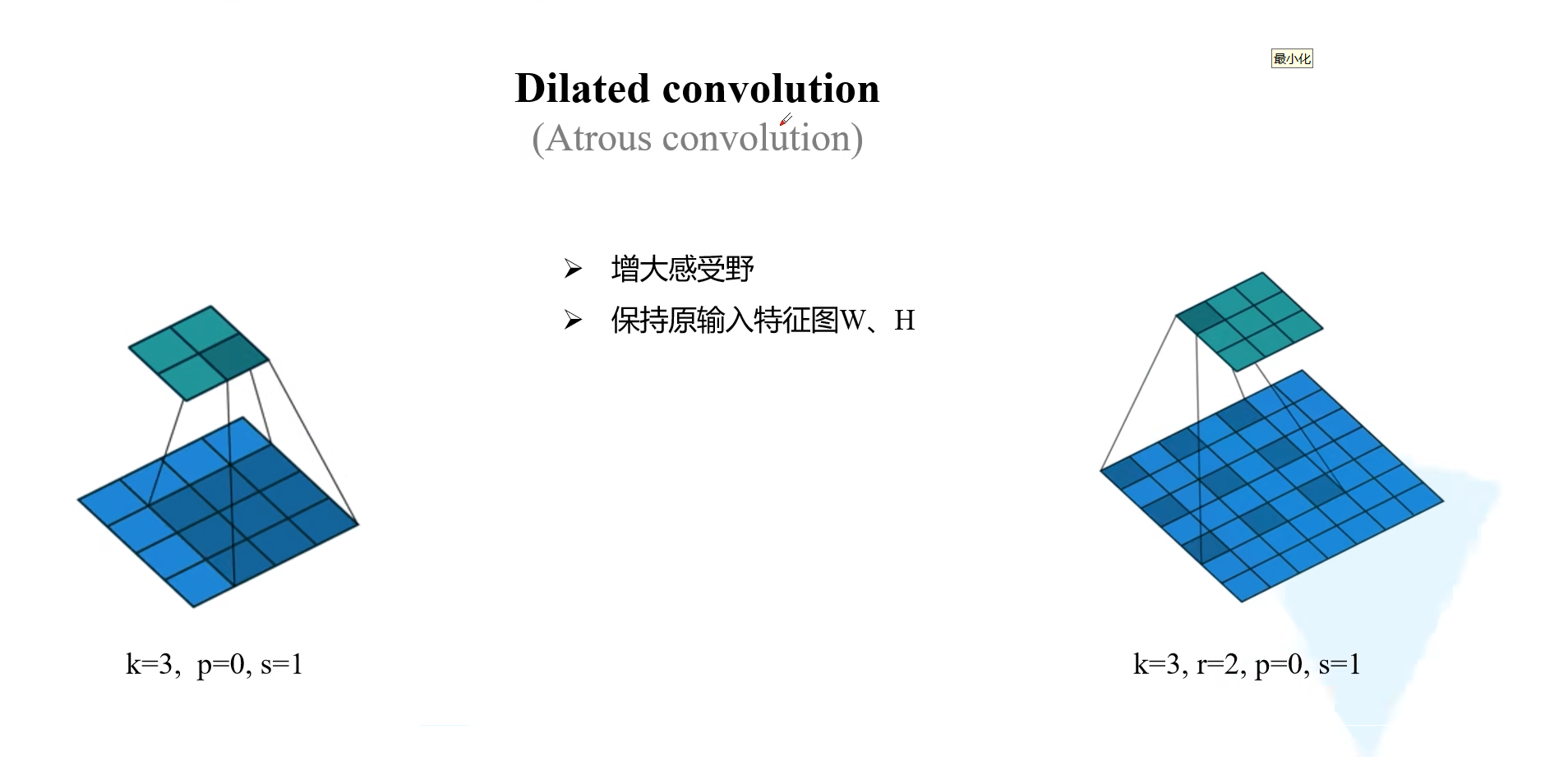
其感受野可以写成:
其中, 是卷积核尺寸, 是膨胀率。膨胀率越大,卷积一次能覆盖的空间范围就越大。
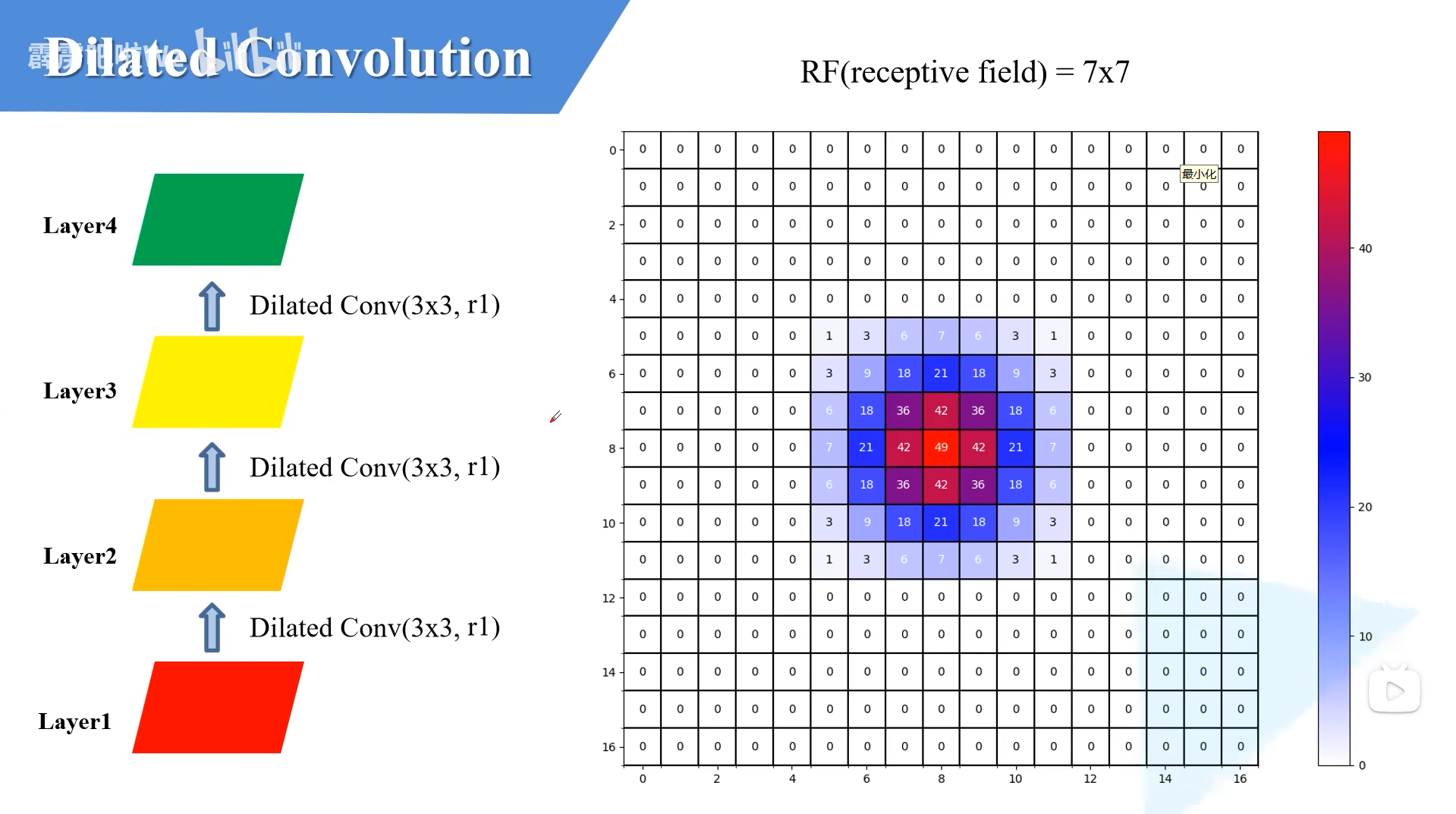
如果把多层卷积堆叠起来看,区别会更明显。
先看最基础的情况:连续堆叠普通 3 × 3 卷积(也就是膨胀率 r = 1),感受野会逐层扩大,但扩张速度相对平缓。下面这张图里,四层之后的感受野是 7 × 7。
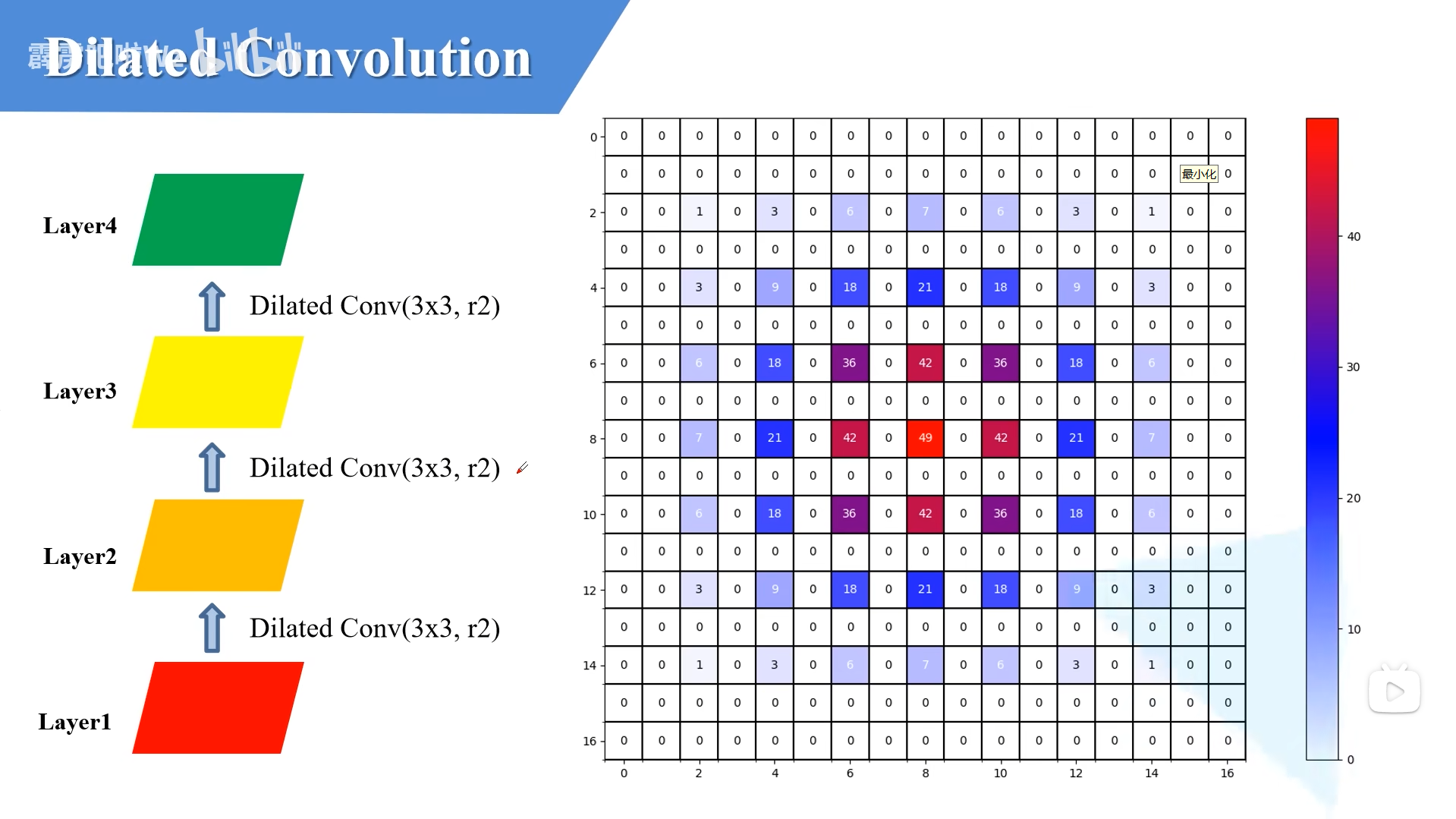
如果把每一层都换成固定膨胀率 r = 2 的空洞卷积,感受野会更快变大,四层后可以扩展到 13 × 13。但你也能从图里看出一个问题:响应分布变得更稀疏,中间会出现“隔点采样”的效果。
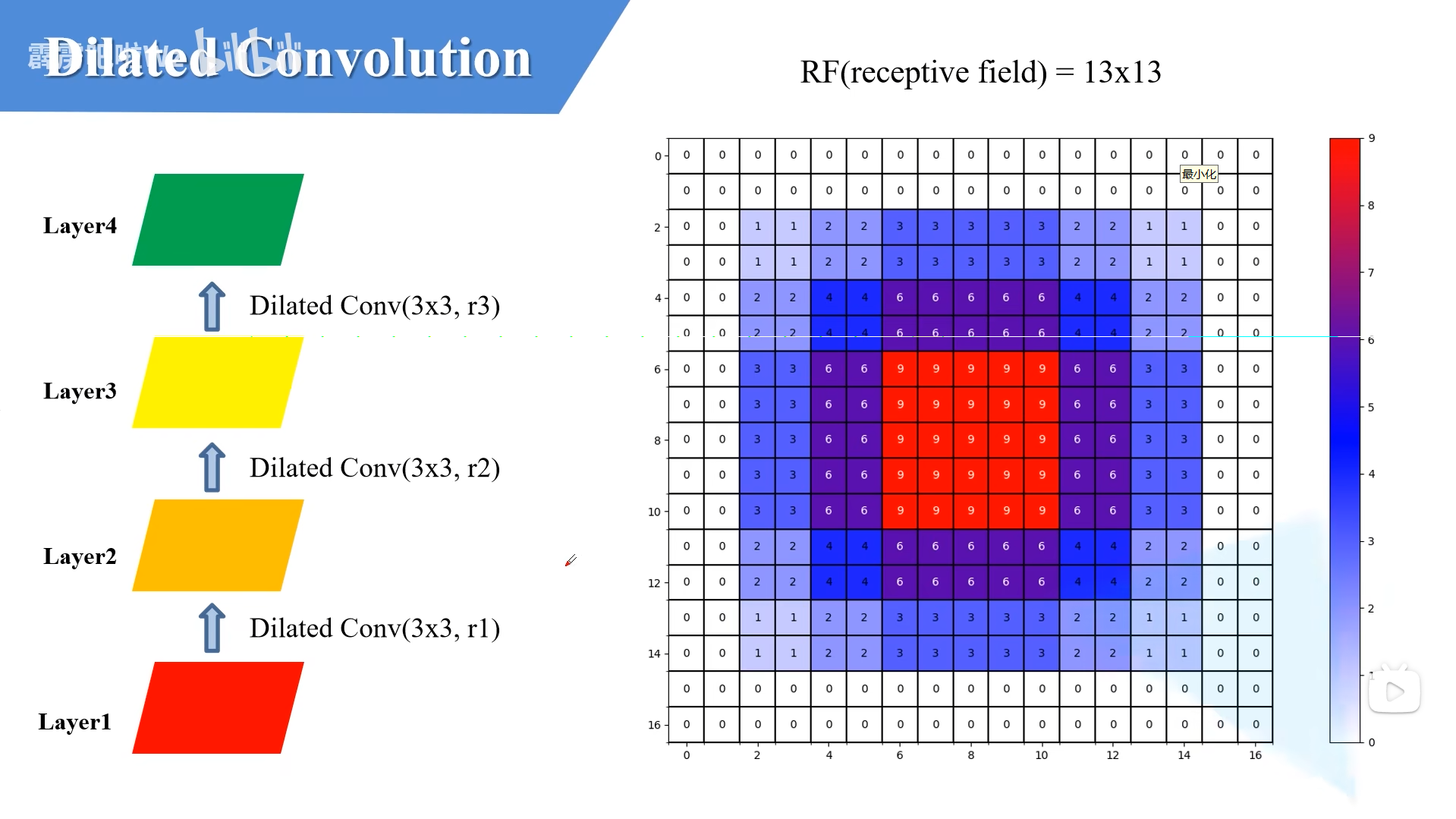
因此,更常见的做法不是所有层都用同一个空洞率,而是像下面这样逐层增大,例如 r = 1 → 2 → 3。这样既能把感受野扩到 13 × 13,又能让覆盖更均匀,减少只在稀疏网格上取样的问题。
ASPP 的关键不在于只用一个空洞率,而在于并行使用多个不同膨胀率的分支:较小膨胀率更偏向局部细节,较大膨胀率更偏向大范围上下文。这样融合之后,模型就能同时看到“病灶本身长什么样”和“它在整片叶子里处在什么位置”。
这里也可以顺手和 YOLOv5 原本常见的 SPPF 区分一下。两者都在做“扩大感受野”,但方式并不一样:
- SPPF(Spatial Pyramid Pooling - Fast) 的核心是多次最大池化。它更像是在固定卷积特征之上快速聚合更大范围的上下文,计算便宜、实现直接,也是 YOLOv5 原生结构里常见的高效模块。
- ASPP(Atrous Spatial Pyramid Pooling) 的核心是并行空洞卷积。它不是只做池化聚合,而是让多个不同膨胀率的卷积分支同时去看不同尺度的上下文,因此对“既要局部细节,又要远距离语义”的场景通常更有表达力。
如果用一句话概括:SPPF 更偏向高效上下文汇聚,ASPP 更偏向多尺度空洞卷积建模。前者更轻,后者通常更强,但计算和结构也更复杂。

这张结构图的大方向是对的:先做一次通道调整,然后走 1×1 conv、多条 3×3 空洞卷积分支,以及一条 pool → 1×1 conv → upsample 的全局上下文分支,最后把它们 concat 再融合。需要补充的一点是:图里中间三条都写成了 Conv3×3,但在真正的 ASPP 里,它们通常应该对应不同的 dilation rate,否则就失去了“空洞空间金字塔”的意义。
如果按照这张图去写成最小可读的 PyTorch 代码,可以写成下面这样:
class AtrousConv(nn.Module):
def __init__(self, in_channels, out_channels, dilation):
super().__init__()
self.block = nn.Sequential(
nn.Conv2d(
in_channels,
out_channels,
kernel_size=3,
padding=dilation,
dilation=dilation,
bias=False,
),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
return self.block(x)
class ASPP(nn.Module):
def __init__(self, in_channels, out_channels):
super().__init__()
self.stem = nn.Sequential(
nn.Conv2d(in_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
self.branch1 = nn.Conv2d(out_channels, out_channels, kernel_size=1, bias=False)
self.branch2 = AtrousConv(out_channels, out_channels, dilation=1)
self.branch3 = AtrousConv(out_channels, out_channels, dilation=3)
self.branch4 = AtrousConv(out_channels, out_channels, dilation=5)
self.global_pool = nn.Sequential(
nn.AdaptiveAvgPool2d(1),
nn.Conv2d(out_channels, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
self.project = nn.Sequential(
nn.Conv2d(out_channels * 5, out_channels, kernel_size=1, bias=False),
nn.BatchNorm2d(out_channels),
nn.ReLU(inplace=True),
)
def forward(self, x):
x = self.stem(x)
pooled = self.global_pool(x)
pooled = F.interpolate(pooled, size=x.shape[2:], mode='bilinear', align_corners=False)
features = [
self.branch1(x),
self.branch2(x),
self.branch3(x),
self.branch4(x),
pooled,
]
return self.project(torch.cat(features, dim=1))和前一版相比,这段代码更贴近图里的结构:最前面有一个 CBS 风格的预处理,后面是四条卷积分支加一条池化分支,最后 concat 后再做一次融合。代码里最关键的仍然是三条 3×3 支路的 dilation 必须不同,这样 ASPP 才是在真正做多尺度上下文建模。
从 YOLOv5 的角度看,ASPP 更像是对高层特征建模能力的补强。它不是单纯把模型做得更深,而是让模型“看得更广”。这意味着,即便基线仍然是一个轻量级检测器,它也能够在复杂背景下更好地整合局部细节与全局语义。
实现细节与工程理解
由于当前可用材料没有提供完整的网络配置文件或逐层插入表,下面的代码只作为概念级示意,用于帮助理解三类模块在 YOLOv5 流程中的作用位置,而不是对应某个可直接复现实验的精确实现。
下面这段伪代码压缩展示了“特征增强 + 上下文融合 + 框回归优化”的逻辑顺序:
features = backbone(image)
features = cbam(features)
context = aspp(features)
pred_boxes, pred_scores = detect(context)
loss = alpha_ciou(pred_boxes, gt_boxes)如果从检测流水线的角度去理解,它其实对应了三层不同的优化:
cbam(features)负责在特征提取之后,先压低背景噪声;aspp(features)负责在高层语义中并行聚合不同感受野的信息;alpha_ciou(...)负责在训练阶段让边界框回归更关注高质量预测框的细致修正。
因此,这三类改动并不是在同一个位置“重复发力”,而是作用在 YOLOv5 检测链路的不同环节:前端更关注特征选择,中层更关注上下文建模,后端更关注回归优化。
效果、适用边界与注意事项
在讨论这些改动是否有效之前,先要明确目标检测里最常用的几项指标。
- Precision(精确率,P):在所有被模型判定为目标的预测框里,有多少是真的对的。它反映的是“报出来的结果准不准”。
- Recall(召回率,R):在所有真实目标里,有多少被模型成功找到了。它反映的是“该找的目标有没有漏掉”。
- AP(Average Precision,平均准确率):可以理解为在不同置信度阈值下,综合 Precision–Recall 曲线后得到的单类别检测质量。
- mAP@0.5:对各类别 AP 取平均,并规定 IoU 阈值为
0.5。也就是只要预测框和真实框的重叠达到 50%,就算匹配成功。这个指标更能反映“能不能把目标大致找对”。 - mAP@0.5:0.95:在 IoU 阈值
0.5, 0.55, ..., 0.95上分别计算 AP 再取平均。因为它同时要求从“粗略对齐”到“严格贴合”都表现稳定,所以比mAP@0.5更严格,也更能反映定位精细度。
如果用一句话概括:Precision 看误检多不多,Recall 看漏检多不多,mAP 看整体检测质量,其中 mAP@0.5:0.95 对框的位置是否足够精确更敏感。
从设计逻辑上看,这套改进之所以合理,是因为它直接对应了虫害检测中的三类真实瓶颈:复杂背景、小目标边界敏感和局部细节需要上下文辅助判断。也正因如此,它比简单切换到一个更大、更通用的检测器更有针对性。
不过,这类方法也有清晰的适用边界。
首先,它更适合目标稀疏、背景复杂、数据规模有限的垂直场景。在这些任务中,模型往往不是缺少容量,而是缺少对任务关键结构的先验偏置。CBAM、ASPP 和 Alpha-IoU 这类改动,本质上就是把这些偏置显式注入进去。
其次,它并不意味着“只要加了注意力和 ASPP 就一定更好”。如果任务本身已经拥有非常大的训练数据、目标形态稳定、背景干扰较小,那么额外模块带来的收益可能就会缩小,甚至会让结构复杂度高于必要水平。
最后,如果把这些改动放回到整条网络结构里看,会更容易理解它们分别插在什么位置:CBAM 作用在前端特征提取阶段,ASPP 插入高层特征建模路径,检测头仍然沿多尺度分支输出预测。
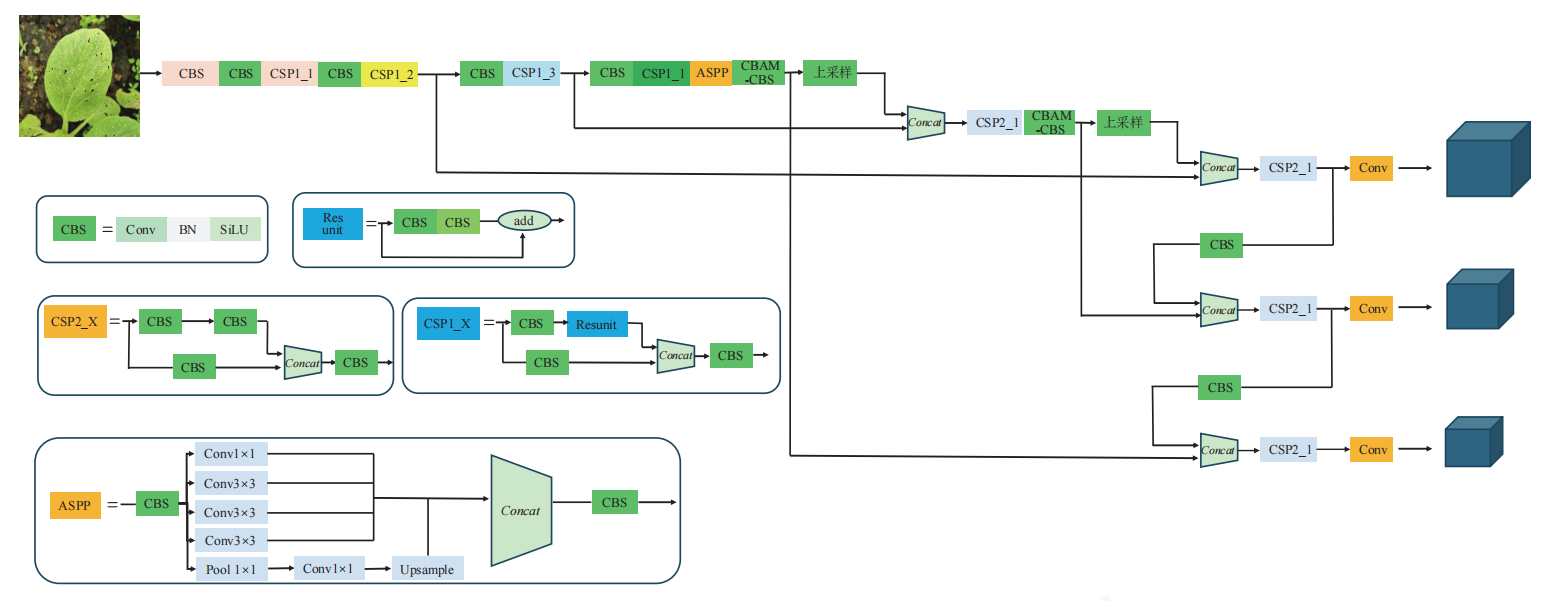
总结
从方法设计上看,这套基于 YOLOv5s 的优化并不是“重造一个新检测器”,而是在成熟框架之上做了三次极有针对性的增强:用 CBAM 提高特征选择性,用 ASPP 扩展上下文感知范围,用 Alpha-IoU 改善边界框回归质量。
这条路线的真正价值,不只在于使用了哪三个模块,而在于它体现了一种更适合垂直场景的模型优化思路:不要先问模型还能不能更大,而要先问当前任务最缺什么。对于小目标、复杂背景、数据有限的农业视觉任务来说,轻量基线配合模块级定向增强,往往比简单追逐更大、更通用的模型更值得借鉴。
参考资料
- Ultralytics YOLOv5 Architecture Description
- Ultralytics YOLOv5 Documentation
- CBAM: Convolutional Block Attention Module (ECCV 2018)
- Alpha-IoU: A Family of Power Intersection over Union Losses for Bounding Box Regression (NeurIPS 2021)
- Atrous Spatial Pyramid Pooling overview
- Dilated convolution 相关讲解视频(Bilibili)
F:\Yunshen Blog\YOLOPC.html中的本地可读整理材料