YOLOv8 由 Ultralytics 在 2023 年发布。和 YOLOv5 一样,它并不是以正式论文作为主要载体进入社区视野的版本,而更像一次直接发生在工程框架内部的主线升级:它不再只是在既有检测器上继续补训练技巧或部署能力,而是开始把 YOLO 推向一个更统一的多任务视觉框架。
如果把它放回目标检测的发展脉络里看,YOLOv8 最重要的价值,其实也不只是“精度更高、速度更快”这么简单。真正关键的是,它把前几代已经逐步成形的几条主线继续往前推了一步:backbone 和 neck 进一步轻量整理,检测头从 anchor-based 走向 anchor-free,分类与回归更明确地解耦,标签分配和边界框回归方式继续更新,同时分类、检测、分割、姿态等任务开始在同一套 Ultralytics 工作流里被更统一地组织起来。这让 YOLOv8 不只是 YOLOv5 的后继版本,也更像 Ultralytics 生态从“检测工作流”迈向“通用视觉任务入口”的关键节点。
从后来的视角回看,YOLOv8 的影响力也不只是“它是 YOLOv5 的下一代”这么简单。真正关键的是,它把 YOLO 在工程侧已经积累起来的易用性,进一步和更现代的检测设计、多任务能力以及统一接口绑定在了一起。也正因为如此,很多人第一次接触 Ultralytics 新一代视觉模型时,真正上手的起点并不是更早的 YOLOv5,而是 YOLOv8。

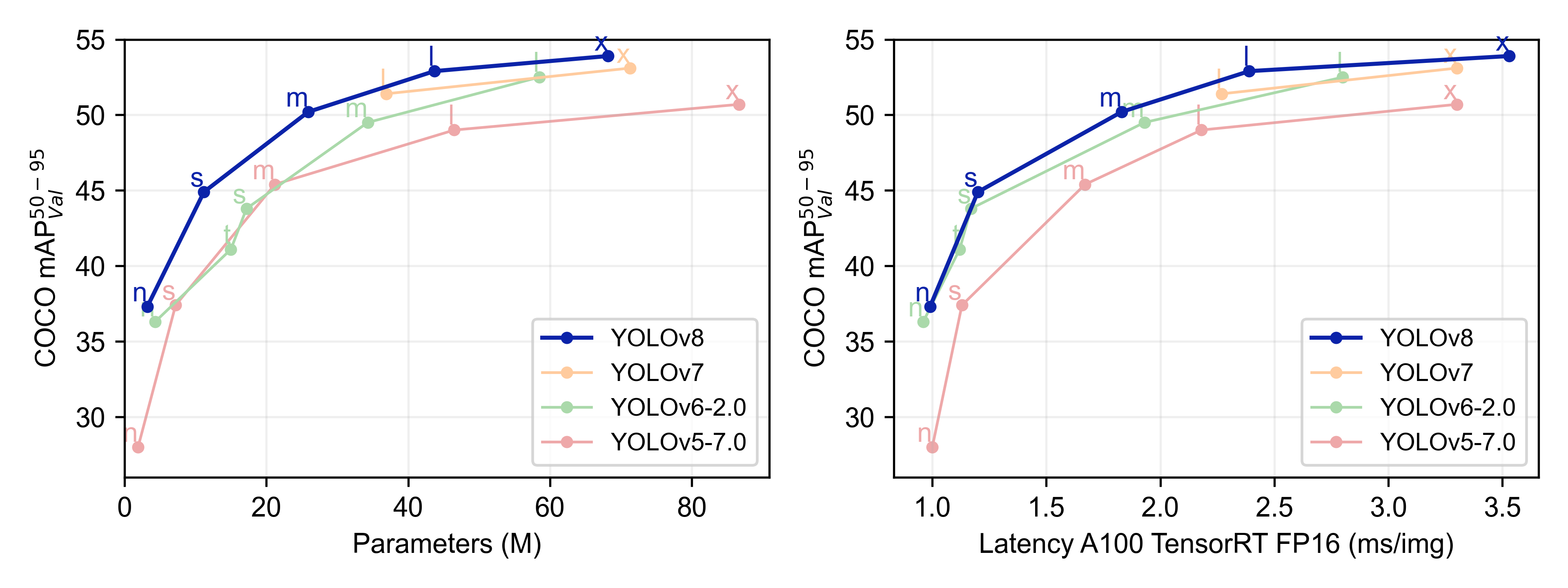
问题背景与方法动机
到了 YOLOv8 所在的时间点,实时检测器面对的现实问题已经和 YOLOv3、YOLOv5 时期不完全一样了。社区已经不再怀疑 one-stage detector 能不能做好,PyTorch 工程工作流也已经普及,真正更现实的问题开始集中到另外几个方向:
- anchor 机制的历史负担仍然存在:锚框设计、匹配策略和超参数适配依旧会增加训练复杂度;
- 分类与回归共享同一头部并不总是高效:两类任务关注的特征并不完全相同;
- 模型不再只做检测:分割、姿态、分类、旋转框等任务开始要求统一入口;
- 工程可用性不只是“能训练”:用户希望同一套 CLI / Python API 覆盖训练、验证、推理和导出;
- 速度-精度权衡需要继续向前推进:尤其是在边缘设备和产品部署语境下,模型规模组织必须更清晰。
因此,YOLOv8 想解决的问题,已经不只是“再设计一个更强 detector”。它更像在回答这样一个问题:如果 Ultralytics 已经把 YOLO 做成了一套成熟工作流,那么下一步怎样把这套工作流和更现代的检测设计、多任务支持进一步统一起来。
下面这张表可以快速定位 YOLOv8 相对 YOLOv5 更强调的方向:
| 维度 | YOLOv5 | YOLOv8 更强调的方向 |
|---|---|---|
| 检测头范式 | anchor-based,多尺度检测头 | anchor-free,分类/回归解耦 |
| 主体模块 | CSP/C3 + SPPF | C2f + SPPF,结构进一步整理 |
| 标签分配 | 以 anchor 体系为中心的匹配逻辑 | 更强调任务对齐的动态分配 |
| 回归方式 | 传统框回归主线 | DFL + IoU 组合进一步强化定位 |
| 任务范围 | 以检测为主,工程能力很强 | 检测、分割、姿态、分类等统一入口 |
| 产品形态 | 成熟检测工作流 | 更统一的视觉任务框架 |
YOLOv8 的整体思路
如果把 YOLOv8 的核心变化压缩成一句话,那么可以写成:它并没有离开 YOLOv5 已经建立起来的工程语境,而是把这套语境继续推进到更现代的检测设计和更统一的任务接口上。
YOLOv8 的整体结构仍然可以概括为三部分:
- Backbone:以 CSPDarknet 变体为基础,引入 C2f 等结构整理特征提取路径;
- Neck:继续沿用 PAN/FPN 式多尺度融合,但对中间连接做了更轻量化调整;
- Head:采用 anchor-free 的解耦检测头,将分类与回归分开建模。
这意味着 YOLOv8 的重点,不是把前代全部推翻,而是把系统调到另一个更符合当时趋势的位置:
- backbone 更强调梯度流和特征复用效率;
- neck 更强调用更少的额外连接保持多尺度融合能力;
- head 则明确转向 anchor-free 与 decoupled design;
- 框架层面进一步把多任务能力统一到同一套接口里。
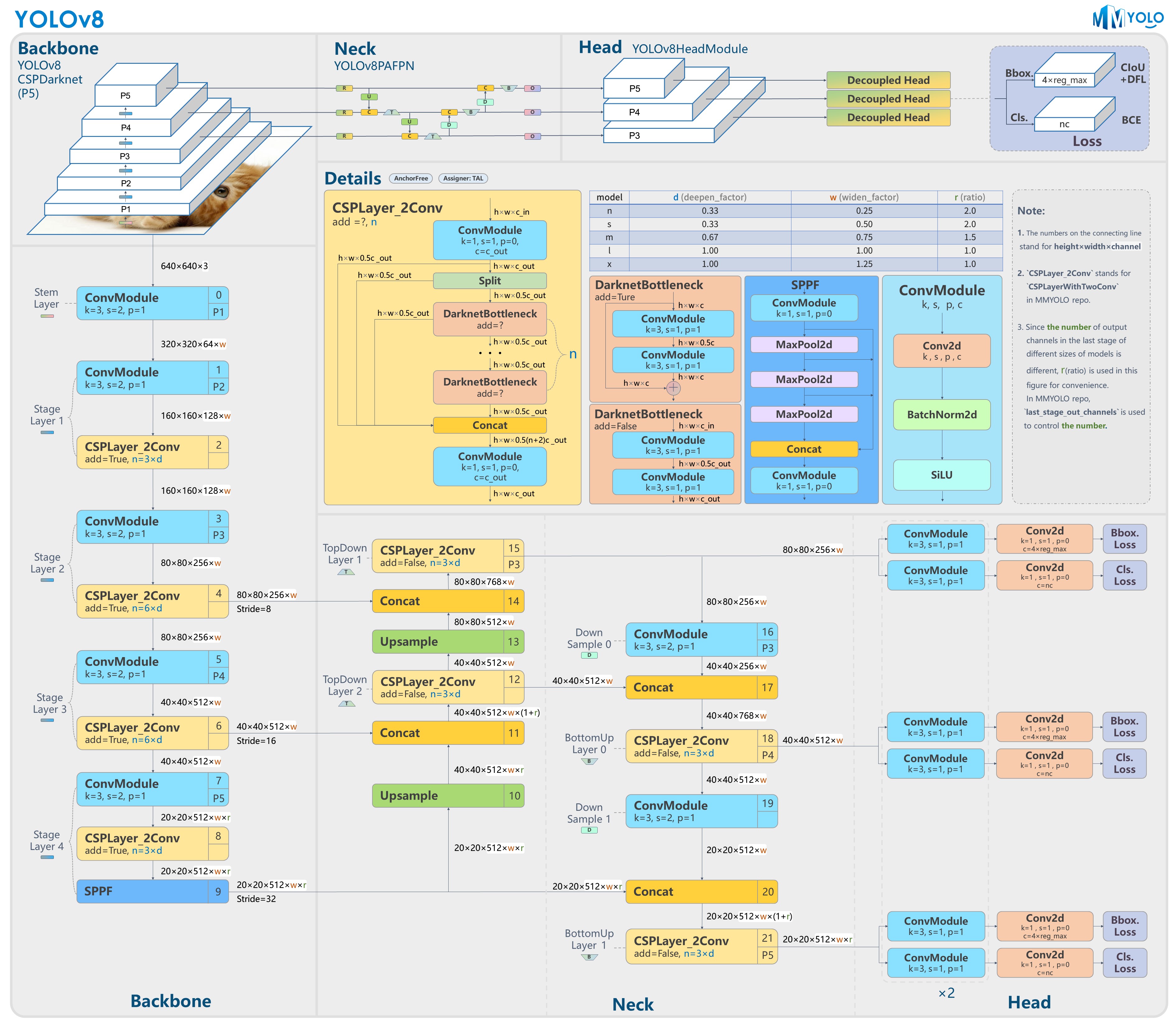
因此,YOLOv8 的方法论升级重点,已经不只是“检测器怎么继续调优”,而是怎样让检测结构升级与统一任务框架一起发生。
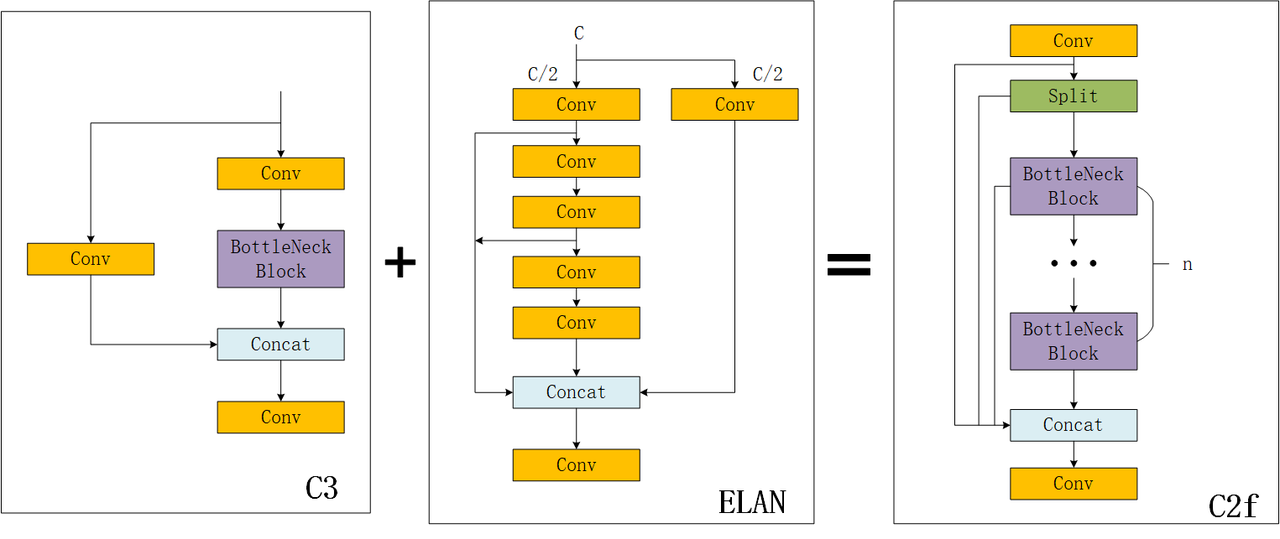
Backbone:C2f 为什么成为 YOLOv8 的代表模块
YOLOv8 backbone 最常被提到的变化,就是把 YOLOv5 里非常有代表性的 C3 主线,进一步整理成了 C2f。它的核心目标并不是让结构看起来更新,而是在保持表达能力的同时,进一步增强梯度流、提高特征复用效率,并把整体模块做得更轻便。
C2f 相对 C3 想解决什么
如果从直觉上理解,C2f 可以看作是在 CSP 风格主线上的继续整理。YOLOv5 的 C3 已经在“旁路信息流 + 重路径变换”之间做了平衡,而 YOLOv8 的 C2f 则进一步强调:
- 中间特征不要过早丢弃;
- 更多保留分支间的信息汇聚;
- 让梯度传播路径更丰富;
- 用相对克制的结构复杂度换来更好的训练与表达平衡。
这背后的核心判断很务实:如果实时检测器还想继续提高效果,不一定非要把模块做得更重,更可能是要把已有信息流组织得更高效。
为什么这类变化很符合 YOLOv8 的位置
YOLOv8 并不是一个从零开始定义新骨干网络的版本。它更像是在 YOLOv5 工程体系已经成熟之后,对主干与 neck 的内部结构做一次更系统的“现代化整理”。
这种整理的重要性在于:
- 不需要牺牲实时性去换取更深更重的网络;
- 可以把结构升级集中在真正影响训练与表达的部位;
- 让不同规模模型在统一框架下更容易组织。
从这个角度看,C2f 的意义并不只是“YOLOv8 用了新模块”,而是它代表了 YOLOv8 继续沿着轻量、高效、可扩展这条路线细化主干结构的方式。
Neck:多尺度融合没有被放弃,而是继续做轻量整理
YOLOv8 的 neck 并没有背离 YOLOv3、YOLOv5 以来已经被验证有效的多尺度融合主线。它依然建立在 PAN/FPN 这类双向特征聚合思路之上,只是对其中一些连接方式做了进一步裁剪和整理。
为什么 YOLOv8 还在坚持 PAN/FPN 逻辑
原因其实很简单:多尺度检测仍然是实时检测器的基本问题。大目标、中目标、小目标所依赖的特征层次并不相同,只要模型还要同时覆盖不同尺度目标,就很难绕开跨层融合。
YOLOv8 延续这条主线,本质上说明了一件事:
- 高层特征依然负责更强语义;
- 浅层特征依然负责更细定位;
- 系统优化的重点不在于否定多尺度融合,而在于让它更顺、更轻、更适合新的 head 设计。
YOLOv8 在 neck 上的取舍
源稿里反复提到的一个细节,是 YOLOv8 去掉了上采样前的一部分卷积整理,让一些 backbone 输出更直接地参与后续融合。这类调整并不一定会在每个版本叙事里成为“最响亮的创新点”,但它很符合 YOLOv8 的风格:不是彻底换一条路线,而是在已经证明有效的主线上继续减轻冗余。
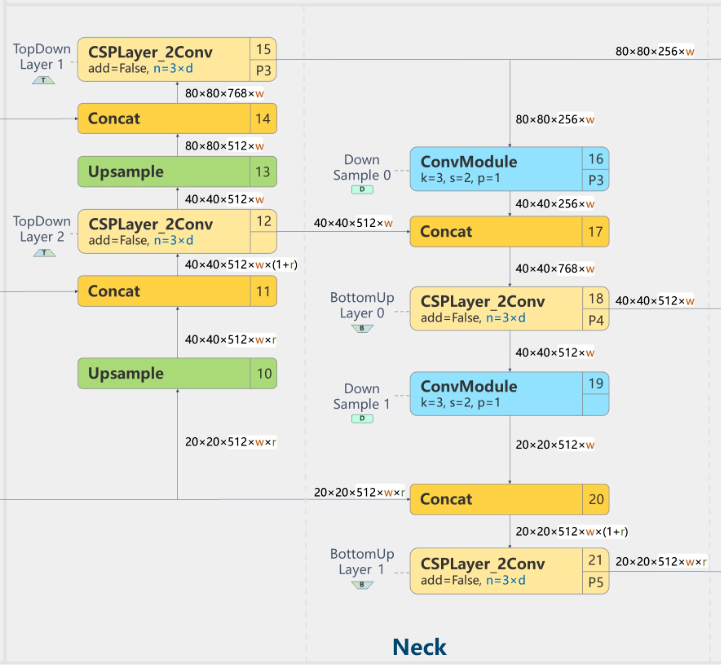
从系统层面看,这类改动的意义主要在于:
- 保留多尺度语义与细节聚合能力;
- 减少中间不必要的结构负担;
- 为新的解耦头与回归方式提供更合适的输入特征。
Head:YOLOv8 为什么转向 anchor-free 解耦检测头
YOLOv8 最关键的结构变化,不在 backbone,也不在 neck,而是在 head。它真正代表这一代方法升级的位置,是从 YOLOv5 的 anchor-based coupled head,转向 anchor-free 的 decoupled head。
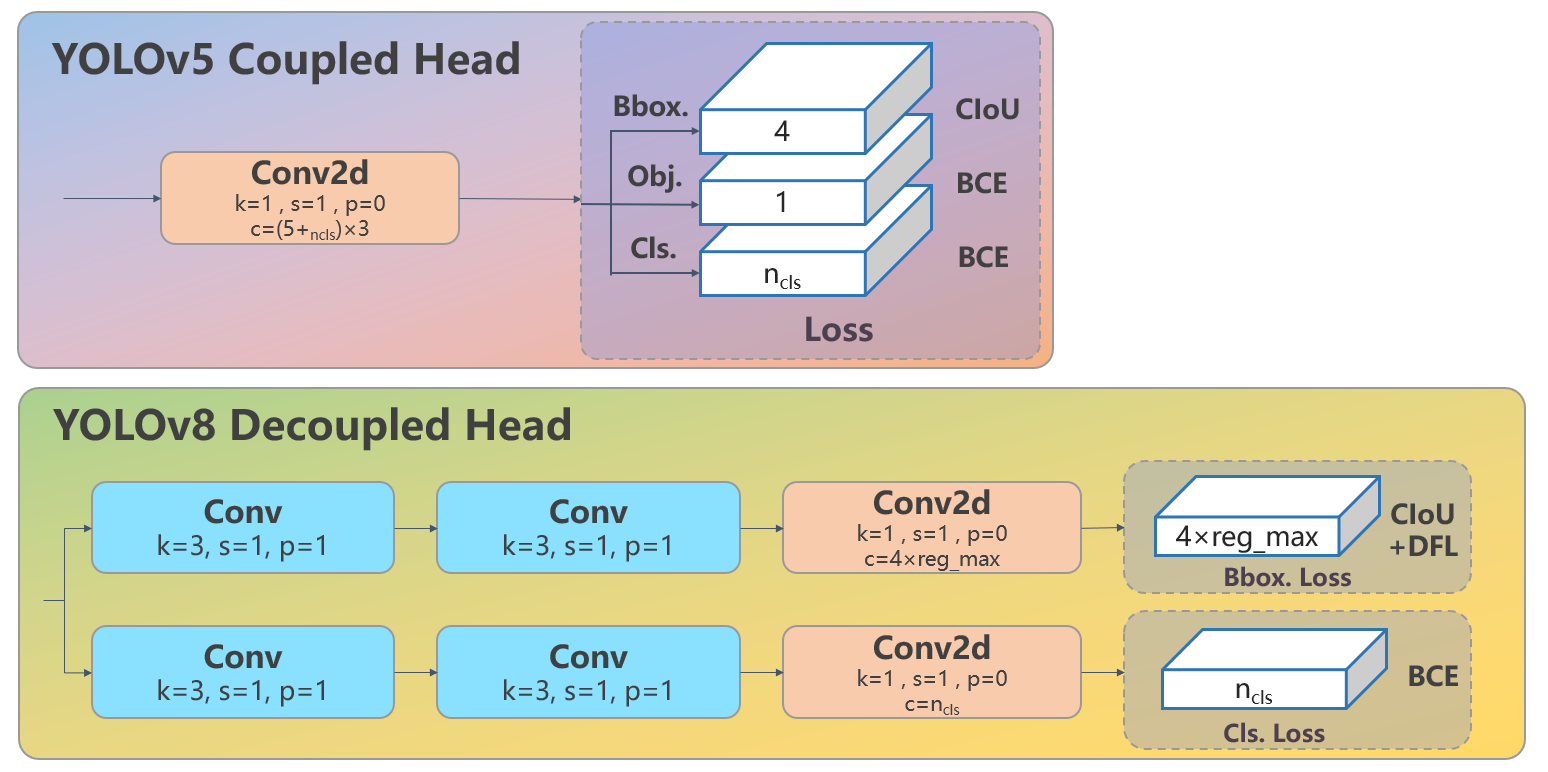
为什么要把分类和回归拆开
分类任务关心的是“这是什么”,回归任务关心的是“它在哪里”。这两件事虽然相关,但并不完全依赖同一类特征。把它们完全绑定在同一个输出头里,会让模型在优化时受到额外牵制。
因此,YOLOv8 采用解耦头的核心逻辑很清楚:
- 分类分支更专注语义判断;
- 回归分支更专注定位质量;
- 两者分别优化,更容易让任务目标对齐;
- 这也为后面的标签分配与损失设计升级创造了条件。
这一步并不是 YOLOv8 独有的发明,但它在 Ultralytics 主线中的落地非常关键,因为这意味着 YOLO 系列正式从过去更传统的共享式头部组织,切到了更现代的任务分离设计。
为什么转向 anchor-free
anchor-free 的意义,并不只是“少几个超参数”。更核心的是,它减少了模型对锚框先验设计的依赖,让检测头能用更直接的方式组织预测目标。
对工程侧而言,这有几个现实收益:
- 降低 anchor 设计与适配的心智负担;
- 简化检测头输出组织;
- 在不同数据分布下更容易迁移;
- 配合新的分配与回归方式时,整体逻辑更统一。
这也正是 YOLOv8 和 YOLOv5 在方法层面最醒目的分界线之一:YOLOv5 更像把成熟的 anchor-based 工作流做到了极致,而 YOLOv8 则开始明确转向 post-anchor 时代的检测头组织方式。
标签分配与回归:为什么 Task-Aligned Assigner 和 DFL 很重要
如果说解耦头和 anchor-free 是 YOLOv8 在结构层面最明显的变化,那么标签分配与回归方式的升级,则是它在训练机制层面的关键补充。因为一旦分类和回归被拆开,系统就必须更认真地处理“哪些样本该被分给谁、回归应该怎么学”这两个问题。
Task-Aligned Assigner:让分类与定位更一致
YOLOv8 训练里广泛被讨论的一点,是引入了更强调任务一致性的样本分配方式。直观理解,它不是只盯着某个单独指标来决定正样本,而是更重视分类质量与定位质量的联合对齐。
这件事为什么重要?因为解耦头虽然让任务分工更清楚,但也会带来新的风险:分类分支觉得这是目标,回归分支却不一定把框回在最合适的位置,反之亦然。如果分配策略不能把这两件事更好地绑在一起,解耦反而可能带来不一致。
因此,Task-Aligned Assigner 的意义可以概括为:
- 正样本分配不再只是粗粒度匹配;
- 分类与回归被更明确地共同考虑;
- 更有利于让 head 的两条分支朝同一目标优化。
DFL 与 IoU 组合:让框回归更细
YOLOv8 另一个关键点,是继续强化了边界框回归这条线。这里最值得关注的,不只是“又换了个损失函数名字”,而是它背后的思路:边界框定位不再只被看作一个粗糙的连续值回归问题,而是希望让模型学到更细的边界分布信息。
DFL(Distribution Focal Loss)和 IoU 类损失的组合,正是在这个方向上起作用:
- IoU 类损失负责从几何重叠角度约束框的位置;
- DFL 则帮助模型对边界位置形成更细粒度的分布式表达;
- 两者配合,可以进一步提升定位质量。
从系统角度看,这说明 YOLOv8 并不是只把 head 换成了 anchor-free,而是把head、assigner、regression loss 一整套机制都一起推进到了更现代的位置。
从检测器到统一入口:YOLOv8 为什么更像平台化框架
YOLOv8 和 YOLOv5 最容易被一起讨论,但它们在“平台属性”上的重心其实并不完全一样。YOLOv5 更像把检测这件事工程化得非常彻底,而 YOLOv8 则进一步把这种工程化扩展成了更统一的任务入口。
Ultralytics 官方文档与仓库对这一点表达得很明确:同一套框架下,不只是目标检测,还包括:
- 实例分割
- 姿态 / 关键点
- 图像分类
- 旋转框检测
- 以及共享的训练、验证、推理、导出工作流
这件事很重要,因为它意味着用户接触到的不再只是“一个 detector repo”,而是一套带统一 CLI、统一 Python API、统一模型组织方式的视觉任务框架。
对于工程团队来说,这样的价值非常直接:
- 换任务时不必换一整套使用方式;
- 训练、验证、推理、导出接口更统一;
- 文档、生态和模型管理更容易延续;
- 项目从检测扩展到分割、姿态时迁移成本更低。
从这个角度看,YOLOv8 的影响力并不只来自 detector 本身,而来自它把 Ultralytics 这套工作流从“强检测框架”进一步推进成了“统一视觉入口”。
模型缩放与部署生态:YOLOv8 为什么更容易被大规模采用
YOLOv8 延续了 Ultralytics 已经被广泛接受的模型家族组织方式,常见规模仍然是:
n:更偏轻量与边缘部署;s:在轻量与效果之间取平衡;m:更稳健的中间规模;l/x:面向更高精度需求。
这种组织方式的重要性,在 YOLOv8 这里并没有减弱,反而因为多任务统一而变得更实用。因为用户不只是为一个 detector 选型,而是在一个更统一的平台里,按任务和硬件条件选择合适工作点。
同时,官方文档和仓库也继续强调了完整工作流能力,包括:
- Python 与 CLI 双入口;
- 训练、验证、推理与 benchmark 统一;
- 导出到 ONNX、TensorRT 等格式;
- 与更完整的部署和集成生态连接。
模型缩放与部署生态:YOLOv8 为什么更容易被大规模采用
YOLOv8 延续了 Ultralytics 已经被广泛接受的模型家族组织方式,常见规模仍然是:
n:更偏轻量与边缘部署;s:在轻量与效果之间取平衡;m:更稳健的中间规模;l/x:面向更高精度需求。
这种组织方式的重要性,在 YOLOv8 这里并没有减弱,反而因为多任务统一而变得更实用。因为用户不只是为一个 detector 选型,而是在一个更统一的平台里,按任务和硬件条件选择合适工作点。
同时,官方文档和仓库也继续强调了完整工作流能力,包括:
- Python 与 CLI 双入口;
- 训练、验证、推理与 benchmark 统一;
- 导出到 ONNX、TensorRT 等格式;
- 与更完整的部署和集成生态连接。
这类能力看起来不像单篇论文里最容易被突出展示的部分,却往往决定了一个模型会不会成为真正的大规模默认选项。因为对很多团队来说,真正重要的从来不是“某个版本有没有多涨 0.几 个点”,而是它能不能在真实项目里被快速训练、统一调用、顺利导出并稳定上线。
YOLOv8 的优势、局限与历史位置
优势
| 优势 | 说明 |
|---|---|
| 检测头更现代 | anchor-free + decoupled head 让分类与回归分工更清楚 |
| 结构整理更成熟 | C2f、SPPF 与轻量化 neck 调整让整体组织更顺滑 |
| 训练机制更统一 | 分配策略与回归方式和 head 升级配套推进 |
| 多任务入口统一 | 检测、分割、姿态、分类等共享同一套框架语境 |
| 工程生态延续并增强 | CLI、Python API、导出与部署能力继续完善 |
局限
| 局限 | 根源 |
|---|---|
| 并非一篇正式论文驱动的版本 | 很多设计结论主要依赖官方实现与文档传播 |
| 社区二手解读很多 | 容易夹杂非官方扩展说法或过度归因 |
| 结构变化虽关键,但并非彻底换代 | 它更多是沿着既有主线做系统升级 |
| 后续版本仍会继续演化 | Ultralytics 的主线更新速度很快,YOLOv8 不是终点 |
历史位置
YOLOv8 最重要的意义,不在于它像 YOLOv1 那样重新定义了任务,也不在于它像 YOLOv3 那样明确完成了一次经典结构分水岭。它更像一个平台化节点:它让 Ultralytics 这条已经非常成熟的 YOLO 工程主线,进一步从“检测工作流”走向“统一视觉任务框架”。
也就是说,YOLOv8 的影响力并不只是靠 C2f、anchor-free 或 decoupled head 这些关键词堆起来的,而是因为这些变化和统一接口、多任务能力、导出部署生态一起出现,形成了一个更完整的新阶段。这也是为什么很多人谈 YOLOv8 时,谈的往往不只是一个 detector,而是一整套更现代的使用体验。
如果说 YOLOv5 代表的是成熟实时检测器的大规模工程落地,那么 YOLOv8 更像是成熟实时检测器开始进一步整合为统一视觉任务入口。
总结
YOLOv8 并没有离开 YOLO 这条已经被验证有效的主路线,但它把这条路线继续推向了更现代、更统一的方向。
如果把它的核心贡献概括成三点,可以写成:
- 用 C2f、轻量 neck 调整与更现代的 head 设计,进一步整理了实时检测器的结构主线;
- 用 anchor-free、解耦头、Task-Aligned Assigner 与 DFL/IoU 组合,把训练与预测机制推进到新的阶段;
- 用统一的 CLI / Python API 与多任务支持,把 Ultralytics YOLO 从强检测框架进一步推进成统一视觉任务平台。
YOLOv8 的历史地位,更多来自它把“结构升级”和“平台统一”这两件事放到了同一个版本里完成。它未必是 YOLO 系列里最具论文色彩的一版,却极大塑造了后来很多人理解 Ultralytics YOLO 的方式:不只是一个实时检测模型,而是一套围绕多种视觉任务展开的完整工作流。