拆分阅读:如果你更关心通用方法论,请读 《构建有效 Agents:除 GAIA 之外的核心方法》;如果你更关心具体系统实现,请读 《GAIA Agent:从组件设计到评测闭环》。
本文基于 Anthropic Engineering 的 Building effective agents 和 ReAct 论文,结合我实际开发的 GAIA Agent(一个面向 GAIA benchmark 的 LangGraph ReAct 问答系统),从理论到完整工程实现逐层展开。
TL;DR
- 先别做 Agent:能用单次调用或 workflow 解决,就不要上 agent loop(成本、延迟、失控风险更高)。
- Workflows vs Agents:差别不在"用不用工具",而在"流程控制权在代码还是在模型"。
- 五种 workflow 模式:prompt chaining / routing / parallelization / orchestrator-workers / evaluator-optimizer。
- 可靠性的重点:工具接口(ACI)+ 输出约束 + 评测闭环,而不是更长的提示词。
- ReAct 是一种"轨迹格式/提示词范式",适合把 agent loop 写得更可调试。
GAIA Agent 项目全景
GAIA Agent 是一个基于 LangGraph ReAct 的问答系统,面向 GAIA benchmark 场景,支持工具调用、多模态附件处理(PDF/Excel/图片/音频)、RAG 知识库和批量评测。项目结构如下:
GAIA/
├── config.py # 环境变量驱动的全局配置
├── agent.py # 核心:System Prompt + StateGraph + 答案提取
├── tools.py # 基础工具层(搜索/文件/计算)
├── extension_tools.py # 扩展工具层(PDF/Excel/OCR/音频/视觉)
├── rag.py # RAG 层(FAISS 向量检索 + 解题建议)
├── app.py # Gradio UI + 批量评测入口
└── data_clean.csv # RAG 知识库源数据设计核心:先 workflow,再 agent——RAG 高置信度命中直接短路返回,未命中才进入 LangGraph agent loop;靠近迭代上限时逐步收敛,最后一轮解绑工具强制输出。
GAIA Benchmark:为什么选这个数据集
GAIA(General AI Assistants)是一个评估 AI 助手通用能力的基准测试。它的设计哲学很反直觉:任务对人类很简单,但对 AI 很难。人类平均正确率 92%,而 GPT-4(带插件)仅 15%——这 77% 的差距揭示了当前 AI 系统在多步推理、工具使用和信息整合上的短板。
任务分级
GAIA 包含 466 道题目,按复杂度分为三个级别:
| 级别 | 推理步数 | 特点 | 示例 |
|---|---|---|---|
| Level 1 | ≤5 步 | 无需或仅需少量工具调用 | "What is 15% of 200?" |
| Level 2 | 5-10 步 | 需要推理 + 工具组合使用 | 查 Wikipedia 专辑列表 → 筛选年份 → 计数 |
| Level 3 | 接近完美 | 大量步骤和工具调用,需要精确规划 | NASA 相关问题:多次搜索 → 数据汇总 → 格式化输出 |
任务类型
GAIA 的题目覆盖以下能力维度:
- 信息检索:需要搜索网络、查阅百科、检索论文等外部知识
- 多模态处理:部分题目附带 PDF、Excel、图片、音频等附件文件
- 多步推理:答案通常不能一步到位,需要分解为多个子步骤
- 精确输出:答案必须是简短的事实性回答(数字、人名、日期),不接受冗长解释
评测方式
GAIA 采用准精确匹配评测——答案必须与 ground truth 一致。这意味着 Agent 不仅要"找到信息",还要能把它精确格式化为评测系统期望的格式(比如数字不带千分位逗号、人名不带前缀)。这正是我们在答案提取管道中花大量精力做正则清洗的原因。
这个数据集特别适合验证 Anthropic 的 agent 构建方法论:Level 1 题目用单次调用即可,Level 2 适合 workflow,Level 3 才真正需要 agent loop。自然形成了从简单到复杂的渐进式架构。
先问自己:真的需要 Agent 吗?
| 任务特征 | 更推荐 | 为什么 |
|---|---|---|
| 只需要一次检索/一次工具调用就能结束 | 单次调用(带工具/RAG) | 最便宜、最稳、最好测 |
| 步骤固定、可写成流程(哪怕有分支) | Workflow | 可控、可回放、易做 guardrails |
| 步骤不固定,需要根据中间结果动态决定下一步 | Agent loop | 只有在"必须动态"时才值得付出代价 |
一个经验:很多"看起来需要 agent 的任务",其实是缺评测或工具设计不清晰。先把这两件事补齐,通常就能把复杂度压回 workflow。
GAIA 任务经常"步数不固定 + 需要看附件 + 需要外部检索",所以最终还是用 agent loop;但我们仍然尽量把可控部分前置成 workflow。
Anthropic 的定义:Workflows vs Agents
Anthropic 把 agentic systems 分成两类:
- Workflow:由代码定义流程,LLM 在指定位置做"子决策/子生成"。
- Agent:由 LLM 在运行时决定下一步做什么(包括是否调用工具、调用哪个、是否继续迭代)。
这个定义很实用:它把争论("这算不算 agent?")变成一个工程问题——流程控制权在代码还是在模型。

区分的关键:谁在控制流程
很多人困惑的点在于:Workflow 里明明也有 LLM 调用,甚至也有工具调用,为什么不算 Agent?
答案是:"用不用 LLM"不是分界线,"谁决定下一步做什么"才是。
在 Workflow 中,LLM 的角色是执行者——代码已经规定了"第一步做 X,第二步做 Y,第三步做 Z",LLM 只是在每一步里完成具体的生成或判断任务。流程的走向、步骤的顺序、何时结束,都由代码(if/else、for 循环、函数调用链)硬编码决定。
在 Agent 中,LLM 的角色是决策者——代码只提供了一个循环框架("观察 → 思考 → 行动 → 观察 → …"),但每一轮做什么、调用哪个工具、是否继续迭代,全部由 LLM 在运行时自主决定。
用一个类比:Workflow 中的 LLM 像是流水线上的工人——工位、顺序、交接规则都由工厂(代码)决定,工人只负责在自己的工位上完成任务。Agent 中的 LLM 像是一个独立承包商——你给它一个目标和一套工具,它自己决定先做什么、后做什么、什么时候交付。
为什么 Workflow 里的 LLM 调用不构成 Agent
以 Prompt Chaining 为例,一个典型的"翻译 + 校对"workflow:
# Workflow:代码控制流程,LLM 只做子任务
def translate_and_review(text):
# 第一步:翻译(代码决定先翻译)
translation = llm.invoke("请将以下英文翻译为中文:" + text)
# 第二步:校对(代码决定翻译完再校对)
review = llm.invoke("请校对这段翻译,指出错误:" + translation)
# 第三步:修正(代码决定校对完再修正)
if "错误" in review:
final = llm.invoke("根据校对意见修正翻译:" + review)
else:
final = translation
return final # 代码决定何时结束这里有三次 LLM 调用,但流程完全由 translate_and_review 函数的代码逻辑控制——先翻译、再校对、再修正、然后返回。LLM 在每一步都只是"做一件被指定的事"。
对比 Agent 的写法:
# Agent:LLM 控制流程,代码只提供循环框架
def agent_loop(goal):
messages = [SystemMessage("你是翻译助手,可以使用以下工具...")]
while True:
response = llm.invoke(messages) # LLM 自己决定下一步
if not response.tool_calls: # LLM 自己决定何时结束
return response.content
results = execute_tools(response.tool_calls) # 执行 LLM 选择的工具
messages.append(results)同样是循环、同样有 LLM 调用,但这里代码不知道会循环几次、不知道 LLM 会选哪个工具、不知道什么时候结束——一切由 LLM 的输出动态决定。
混合体是常态
实际工程中,纯 Workflow 和纯 Agent 都是极端情况,大多数系统是两者的混合。关键是清楚哪些部分你愿意交给模型控制,哪些部分必须由代码硬编码。
GAIA Agent 就是典型的混合体:RAG 短路、文件类型路由、答案格式化都是 workflow(代码硬编码了分支逻辑);只有
StateGraph里的assistant → tools → assistant → …循环才是真正的 agent(LLM 决定调用什么工具、是否继续)。
从最小可行系统开始
Anthropic 将 augmented LLM(增强型 LLM)视为 agentic system 的基本构建单元——在 LLM 核心之上,通过检索、工具调用和记忆三种能力进行增强:
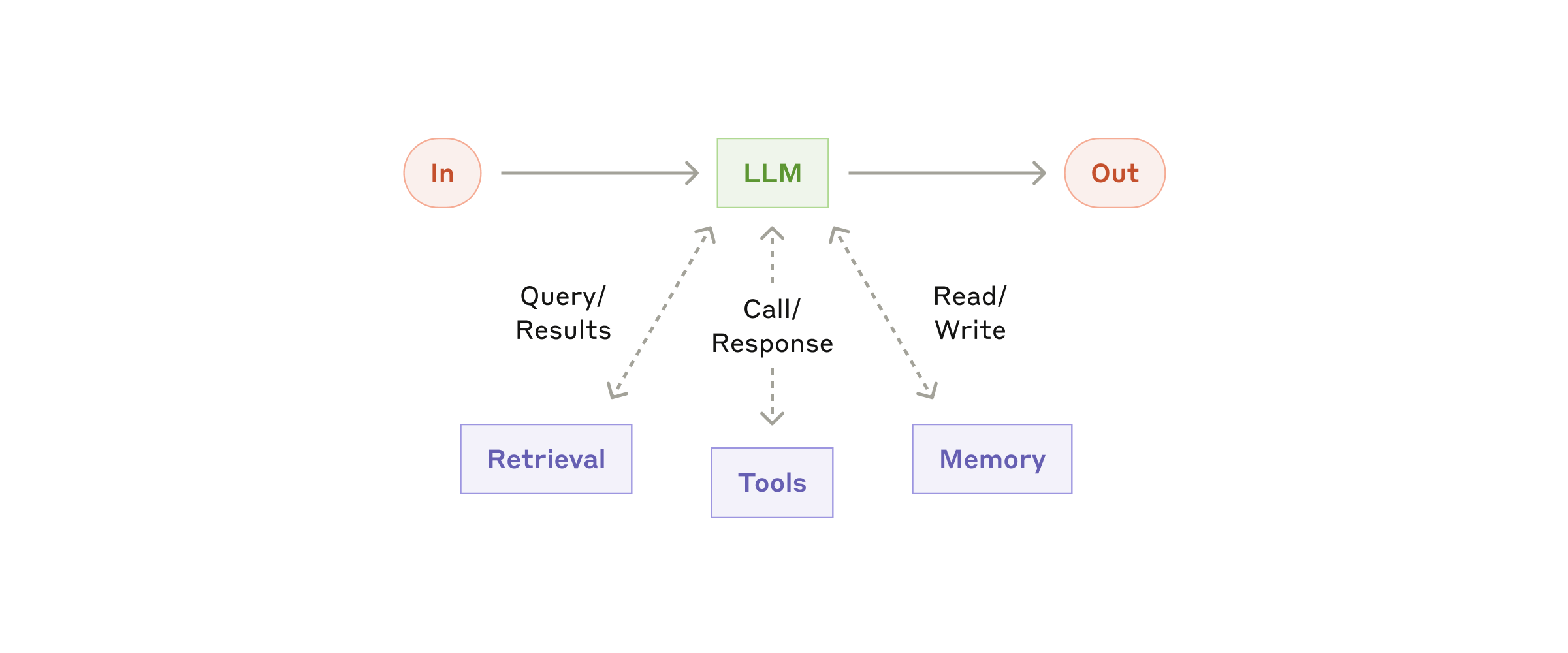
在引入 agent loop 之前,先把三个能力做"稳定":
- 结构化输出:让模型产出可解析的 JSON/表格,而不是自由文本。
- 工具调用:每个工具输入/输出都稳定、可验证、可重试。
- 可观测与回放:日志里能看到每一步输入、输出、工具调用、错误码。
GAIA 的配置管理:环境变量驱动
所有参数通过 config.py 集中管理,使用 .env 文件加载,确保每个维度都可独立调整:
# config.py — 核心配置项
MAX_ITERATIONS = int(os.getenv("MAX_ITERATIONS", "10")) # Agent 最大迭代次数
LLM_TIMEOUT = int(os.getenv("LLM_TIMEOUT", "120")) # LLM 单次调用超时
TOOL_TIMEOUT = int(os.getenv("TOOL_TIMEOUT", "30")) # 工具调用超时
MAX_FILE_SIZE = int(os.getenv("MAX_FILE_SIZE", "10000")) # 工具输出截断长度
RATE_LIMIT_RETRY_MAX = int(os.getenv("RATE_LIMIT_RETRY_MAX", "5")) # 429 重试次数
RATE_LIMIT_RETRY_BASE_DELAY = float(os.getenv("RATE_LIMIT_RETRY_BASE_DELAY", "10")) # 指数退避基数
BATCH_QUESTION_DELAY = float(os.getenv("BATCH_QUESTION_DELAY", "5")) # 批量评测间隔这些配置覆盖了 Agent 行为的关键维度:迭代控制(防无限循环)、超时控制(防工具卡死)、输出控制(防上下文撑爆)、速率控制(防 API 限流)。
五类 Workflow 模式
下面按"复杂度从低到高"展开每种模式,每种模式对应 GAIA Agent 中的具体实现。
Prompt Chaining(串联)
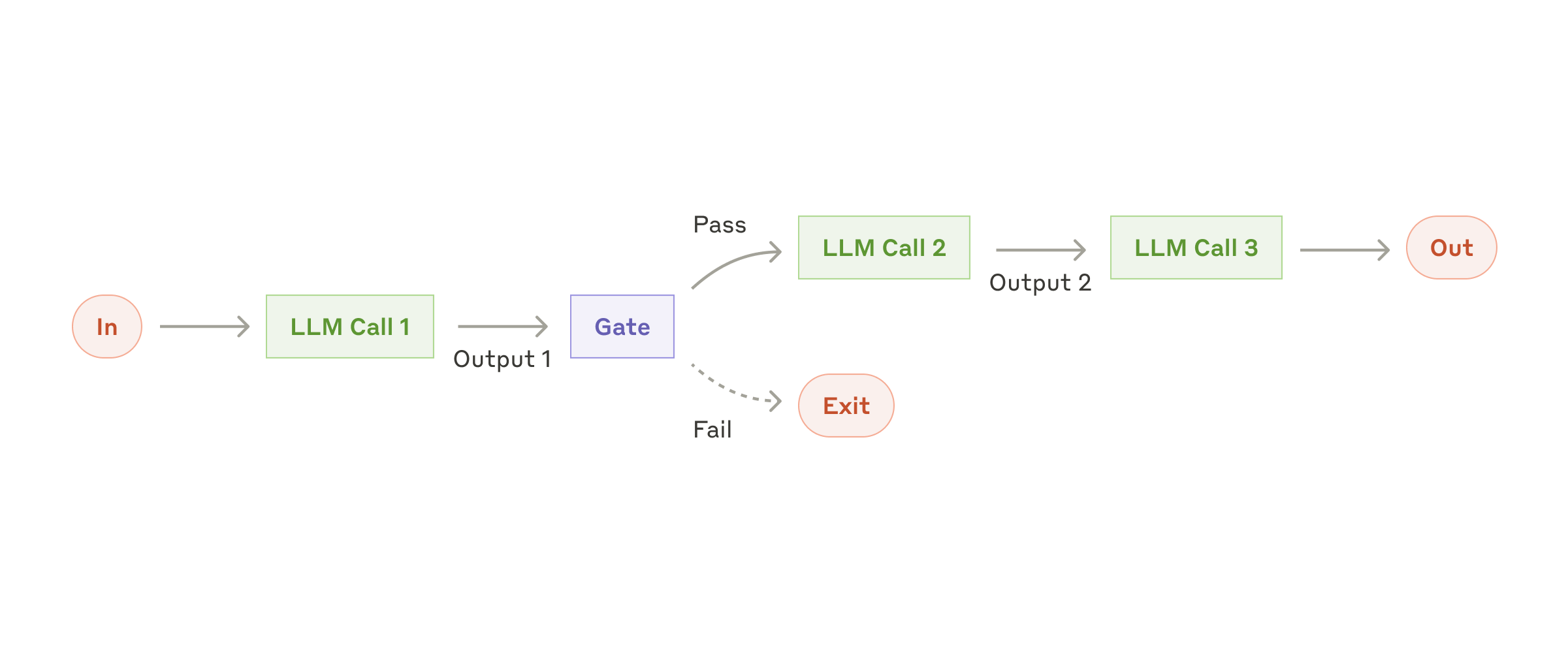
适用:任务天然可拆成 2~5 个固定步骤(提取 -> 验证 -> 生成)。
关键做法:每一步都让输出更简单、更可检验;在链路中插入"闸门"——校验失败就回退/重试。常见坑:链条越长误差越累积,"中间结构化 + 校验"比"更长提示词"更关键。
GAIA 实现:System Prompt 中定义了完整的 prompt chain——把"先查 RAG 知识库、再处理附件、再外部检索、最后计算/代码处理"写成一个明确的优先级顺序:
# agent.py — System Prompt 中的工具使用策略(摘录)
## 工具使用策略
### 优先级顺序
0. **先查知识库**【最高优先级】:
- 首先调用 rag_query(question) 查询知识库
- 如果返回"知识库匹配成功",直接使用该答案
1. **有附件的问题**【重要】:
- 第一步:用 fetch_task_files(task_id) 下载文件
- 第二步:根据扩展名选择正确的解析工具
- 第三步:分析文件内容,进行必要的计算
2. **需要外部信息**: web_search / wikipedia_page / arxiv_search
3. **需要计算**: 简单算术用 calc,复杂处理用 run_python这就是一个写在 System Prompt 里的 prompt chain:每一步都有明确的进入条件和输出预期。
Routing(路由)
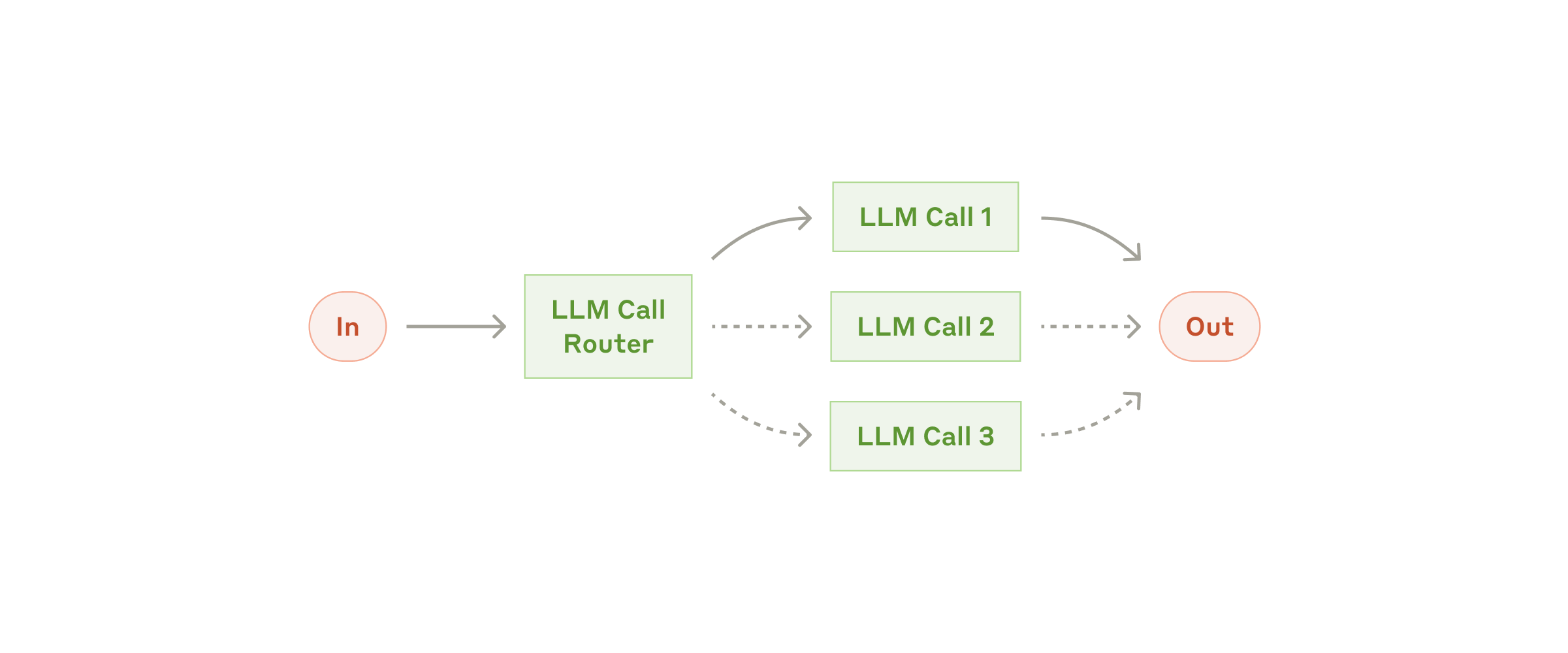
适用:多种问题混在一起,且每类问题有更合适的提示词/工具/模型。常见坑:分类标准写得太玄;建议用清晰的 label + 示例。
GAIA 实现:至少有三层路由在工作。
第一层:RAG 阈值路由——GaiaAgent.__call__ 中,agent loop 之前先查 RAG,相似度超过 0.85 直接短路返回,完全不进入 StateGraph:
# agent.py — RAG 前置短路
def __call__(self, question: str, task_id: str = None) -> str:
# ===== RAG 前置短路:高置信度匹配直接返回 =====
if rag_lookup_answer is not None:
hit = rag_lookup_answer(question, min_similarity=0.85)
if hit and hit.get("answer"):
return str(hit["answer"]).strip()
# ===== 未命中才进入 LangGraph 循环 =====
result = self.graph.invoke(initial_state)
answer = extract_final_answer(result)
# 检查答案是否需要格式化
if self._needs_reformatting(answer):
answer = self._force_format_answer(result)
return answer第二层:文件类型路由——System Prompt 中按扩展名强制指定解析工具,不让模型自行猜测:
根据文件扩展名选择正确的读取工具:
.xlsx / .xls → 必须用 parse_excel(file_path)
.pdf → 必须用 parse_pdf(file_path)
.txt / .csv → 用 read_file(file_path)
.png / .jpg → 用 image_ocr() 或 analyze_image()
.mp3 / .wav → 用 transcribe_audio(file_path)第三层:是否继续路由——should_continue 函数决定 agent loop 的走向:
# agent.py — 路由判断
def should_continue(state: AgentState) -> Literal["tools", "end"]:
last_message = state["messages"][-1]
iteration = state.get("iteration_count", 0)
if iteration >= MAX_ITERATIONS: # 达到上限 → 强制结束
return "end"
if hasattr(last_message, "tool_calls") and last_message.tool_calls:
return "tools" # 有工具调用 → 继续
return "end" # 无工具调用 → 返回答案Parallelization(并行)
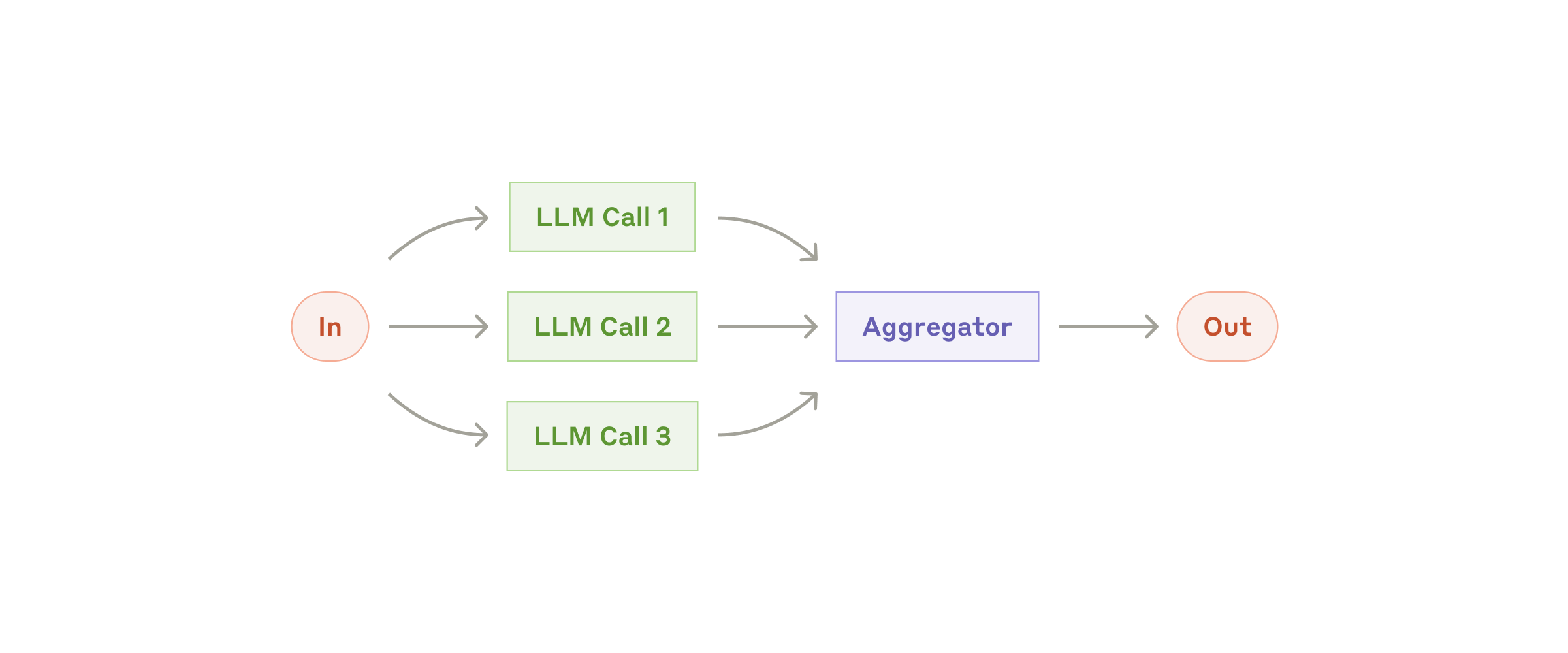
分两种常见用法:Sectioning(把任务分块并行)和 Voting(同题多采样投票)。常见坑:并行很容易"信息重复/风格不一致",需要一个明确的合并策略。
GAIA 现状:搜索类工具很多(web/wiki/arxiv/news/stackoverflow),但目前是"单线程 ReAct 循环"。如果要做并行,更适合把多来源检索做成一次并行,然后由一个汇总器统一合并去重。
Orchestrator-Workers(编排者-工人)
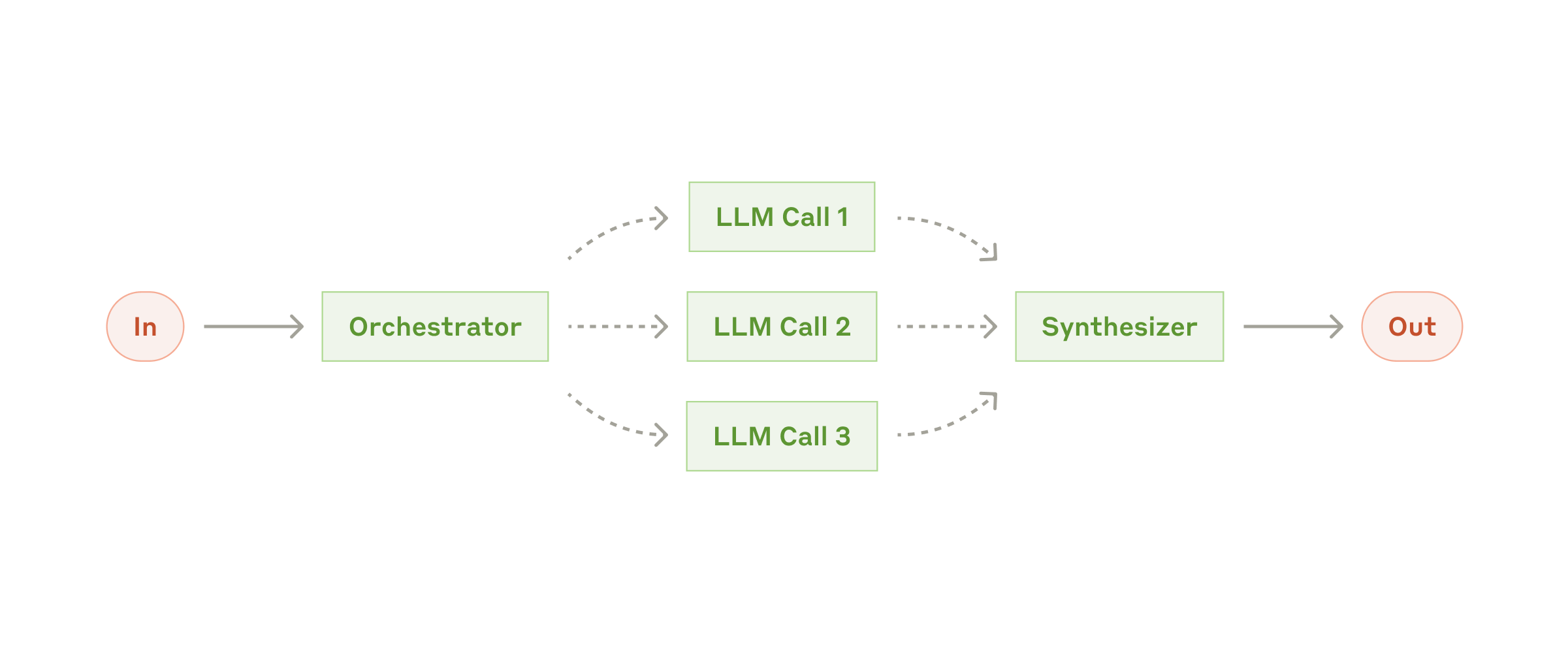
适用:子任务数量和类型不固定。关键做法:编排者负责拆解与分配,工人输入尽量具体、输出结构化。常见坑:编排者反复拆解但不收敛,要加预算和停止条件。
GAIA 可拓展点:GAIA 里常见"一个问题 + 多个附件/多种模态",很适合做成"编排者先决定看哪个文件/用哪个解析器",再把子任务交给对应 worker(PDF/Excel/OCR/音频),最后汇总为一个短答案。
Evaluator-Optimizer(评审-优化)
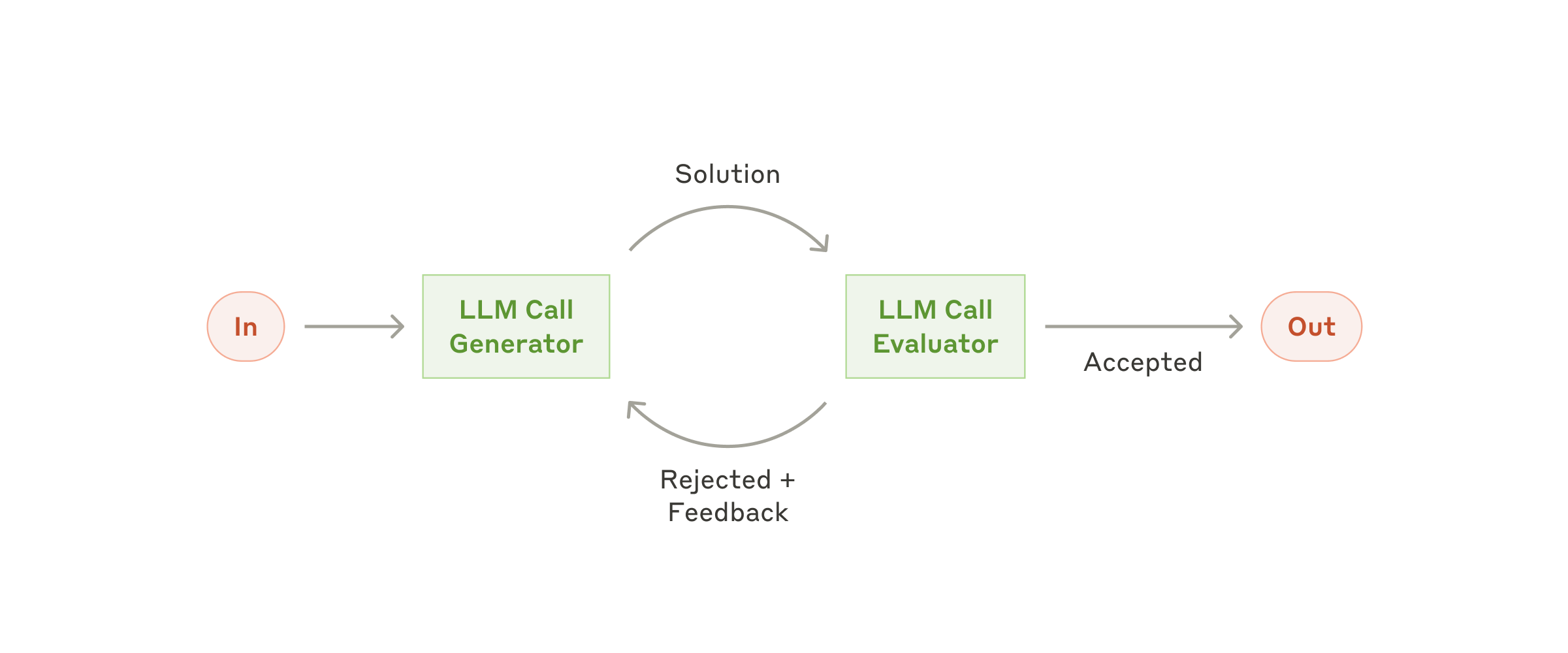
适用:有明确"好坏标准",且多轮改写能显著提升。关键做法:把"生成"和"评审"解耦,评审最好输出可验证的 checklist。
GAIA 实现:在 GaiaAgent 中实现了一个轻量的 evaluator-optimizer 模式。_needs_reformatting 检查答案是否需要重新格式化(如过长、包含 URL、含列表格式),命中后触发 _force_format_answer 进行一轮强制格式化:
# agent.py — 答案格式评审器
def _needs_reformatting(self, answer: str) -> bool:
if not answer or answer == "无法获取答案":
return False
indicators = [
answer.startswith('http'), # 答案是 URL
len(answer) > 300, # 答案过长
answer.count('\n') > 3, # 多段落
answer.startswith('1.') and '2.' in answer, # 列表格式
'...' in answer and len(answer) > 100, # 省略号 + 过长
]
return any(indicators)
def _force_format_answer(self, result: dict) -> str:
format_prompt = (
"根据上述对话收集的信息,输出最终答案。\n\n"
"【强制要求】只输出答案本身,不要解释、不要前缀。\n"
"- 数字:直接输出(如 42)\n"
"- 人名/地名:直接输出(如 Albert Einstein)\n"
"- 日期:YYYY-MM-DD\n"
"- 是/否:Yes 或 No\n"
)
# 用不绑定工具的 LLM 重新格式化
response = invoke_llm_with_retry(get_llm(), full_messages)
return extract_final_answer({"messages": [response]})目标不是写得更好,而是更符合评测输出要求——这恰好是 evaluator-optimizer 模式的典型应用。
五种 Workflow 模式对比
| 模式 | 适用场景 | 延迟 | 实现复杂度 | 核心风险 | GAIA 中的对应 |
|---|---|---|---|---|---|
| Prompt Chaining | 步骤固定、可串行分解 | 随链长线性增长 | 低 | 误差逐步累积,链越长越脆弱 | System Prompt 中的工具优先级链 |
| Routing | 输入类型多样,各需专用处理 | 增加一次分类调用 | 低 | 分类错误导致下游全错 | RAG 阈值路由 + 文件类型路由 |
| Parallelization | 子任务独立、可同时执行 | 取决于最慢分支 | 中 | 结果合并时信息重复或冲突 | 多来源搜索(可拓展方向) |
| Orchestrator-Workers | 子任务数量/类型不可预知 | 取决于编排轮数 | 高 | 编排者反复拆解不收敛 | 多附件多模态处理(可拓展方向) |
| Evaluator-Optimizer | 有明确质量标准、改写有增益 | 至少两倍(生成+评审) | 中 | 评审自身不稳定导致循环无意义 | 答案格式评审 + 强制格式化 |
选型建议:从上往下选。先看 Prompt Chaining 能不能解决,不行再加 Routing,仍不够再考虑 Parallelization 和 Orchestrator-Workers。只有在"需要迭代改进且有可验证标准"时才上 Evaluator-Optimizer。如果五种 Workflow 都无法覆盖——步骤完全不可预测、需要模型自主决策——才考虑下面的 Agent Loop。
Agent Loop:构建与止损
当五种 workflow 模式都无法满足需求时,才引入真正的自主 agent:
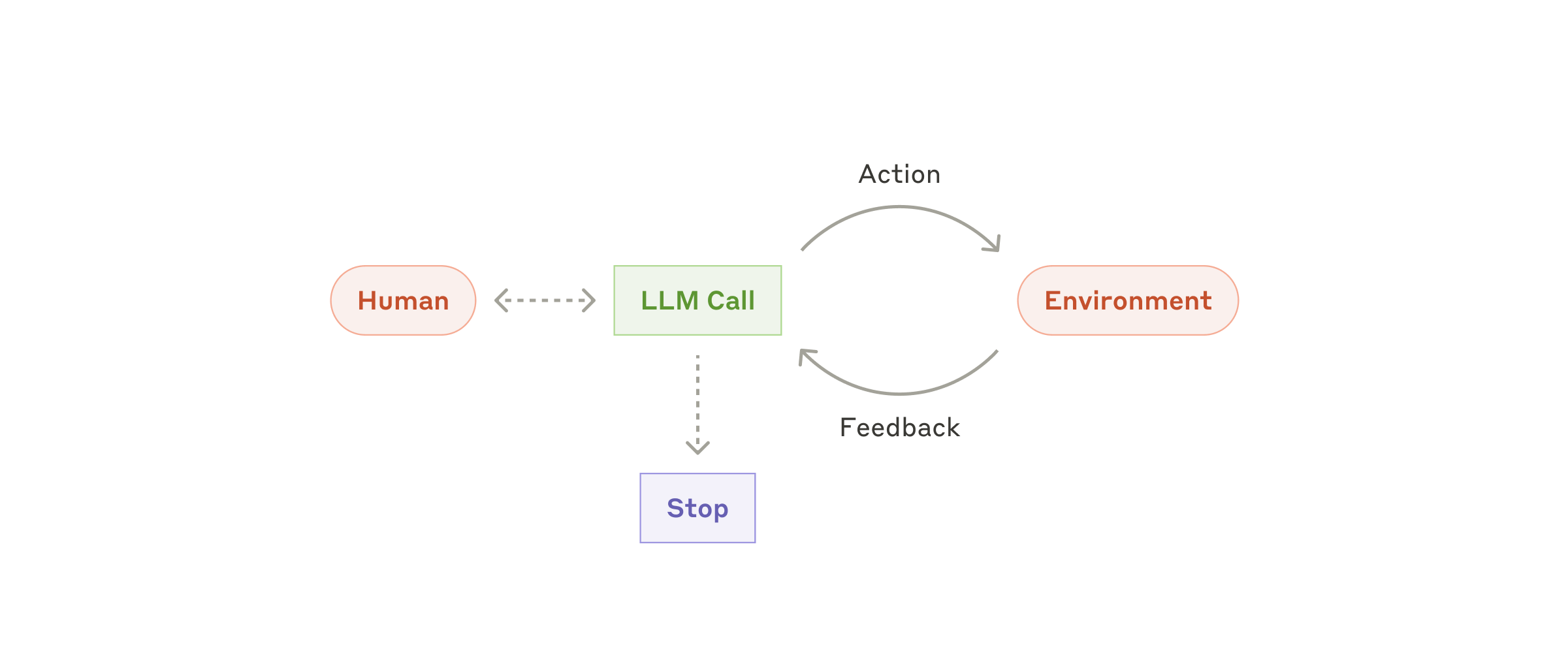
上 agent loop 的三个前提条件:
- 必须动态:你确实写不出固定流程(或固定流程的分支爆炸)。
- 有反馈:每一步都有可验证的 observation(工具返回、测试结果)。
- 能止损:你愿意并能实现预算、超时、最大步数、重复检测。
GAIA 的 Agent Graph
核心 agent loop 通过 LangGraph StateGraph 构建——assistant -> should_continue -> tools -> assistant ... 循环:
# agent.py — Graph 构建
class AgentState(TypedDict):
messages: Annotated[Sequence[BaseMessage], add_messages]
iteration_count: int
def build_agent_graph():
graph = StateGraph(AgentState)
graph.add_node("assistant", assistant)
graph.add_node("tools", ToolNode(ALL_TOOLS))
graph.set_entry_point("assistant")
graph.add_conditional_edges(
"assistant", should_continue,
{"tools": "tools", "end": END}
)
graph.add_edge("tools", "assistant")
return graph.compile()三级止损机制
为了避免"无限循环/越跑越偏",assistant 节点实现了三级止损。这是整个 Agent 最关键的安全网:
# agent.py — assistant 节点(完整逻辑)
def assistant(state: AgentState) -> dict:
messages = state["messages"]
iteration = state.get("iteration_count", 0) + 1
full_messages = [SystemMessage(content=SYSTEM_PROMPT)] + list(messages)
if iteration >= MAX_ITERATIONS - 1:
# 第三级:最后一轮,解绑工具,强制输出纯文本答案
warning = f"⚠️ 【最后机会】已进行 {iteration} 次迭代,达到上限。"
+ "你必须立即给出最终答案!不要再调用任何工具!"
full_messages.append(SystemMessage(content=warning))
response = invoke_llm_with_retry(get_llm(), full_messages) # 注意:不绑定工具
elif iteration >= MAX_ITERATIONS - 2:
# 第二级:倒数第二轮,提醒收敛,但仍允许工具调用
warning = f"⚠️ 警告:已进行 {iteration} 次迭代,接近上限,请尽快给出最终答案。"
full_messages.append(SystemMessage(content=warning))
response = invoke_llm_with_retry(get_llm_with_tools(), full_messages)
else:
# 第一级:正常轮次,允许自由调用工具
response = invoke_llm_with_retry(get_llm_with_tools(), full_messages)
return {"messages": [response], "iteration_count": iteration}关键设计:最后一轮调用 get_llm()(不绑定工具)而非 get_llm_with_tools(),从根本上阻断了模型继续调用工具的可能。这比在 prompt 里写"请不要再调用工具"可靠得多——后者模型可能无视。
速率限制重试
LLM 调用通过 invoke_llm_with_retry 包装,实现指数退避重试:
# agent.py — 带重试的 LLM 调用
def invoke_llm_with_retry(llm, messages, max_retries=None, base_delay=None):
from openai import RateLimitError
if max_retries is None:
max_retries = RATE_LIMIT_RETRY_MAX # 默认 5 次
if base_delay is None:
base_delay = RATE_LIMIT_RETRY_BASE_DELAY # 默认 10 秒
for attempt in range(max_retries + 1):
try:
return llm.invoke(messages)
except RateLimitError:
if attempt < max_retries:
delay = base_delay * (2 ** attempt) # 指数退避:10s, 20s, 40s, 80s, 160s
time.sleep(delay)
else:
raise工具三层架构与 ACI 设计
Anthropic 的文章里最值得强调的一点:很多"agent 不可靠"不是模型不行,而是工具接口不行。
一份对模型友好的工具接口通常具备:
- 名字即意图:动词开头,避免歧义(
search_docs比query好) - 参数少而清晰:宁可拆成两个工具,也别塞 10 个可选参数
- 有示例:至少 2~3 个"正确调用样例 + 返回样例"
- 错误可处理:返回结构化错误码,让模型知道下一步怎么做
- 可回放:每次调用都有日志可追溯
三层工具架构
GAIA Agent 将工具分为三层,按需渐进加载:
# agent.py — 工具渐进加载
from tools import BASE_TOOLS # 第一层:总是可用
try:
from extension_tools import EXTENSION_TOOLS # 第二层:需要额外依赖
ALL_TOOLS = BASE_TOOLS + EXTENSION_TOOLS
except ImportError:
ALL_TOOLS = BASE_TOOLS
try:
from rag import RAG_TOOLS # 第三层:需要向量库
ALL_TOOLS = ALL_TOOLS + RAG_TOOLS
except ImportError:
pass| 层级 | 模块 | 工具 | 依赖 |
|---|---|---|---|
| 基础层 | tools.py | web_search, wikipedia_search, wikipedia_page, tavily_search, arxiv_search, youtube_search, news_search, stackoverflow_search, google_search, fetch_task_files, read_file, calc, run_python | ddgs, requests |
| 扩展层 | extension_tools.py | parse_pdf, parse_excel, image_ocr, transcribe_audio, analyze_image | pdfplumber, pandas, pytesseract, whisper |
| RAG 层 | rag.py | rag_query, rag_retrieve, rag_stats | faiss, sentence-transformers |
这种设计的核心价值:优雅降级。即使 PDF 解析库没装,Agent 仍然能处理文本文件和网络搜索;即使 FAISS 不可用,Agent 仍然能正常工作,只是没有 RAG 加速。
工具输出保护:截断 + 类型提示
每个文件处理工具都有输出长度截断(由 MAX_FILE_SIZE 控制),避免把模型上下文撑爆。同时 fetch_task_files 在下载完成后根据文件扩展名给出下一步操作提示,引导模型使用正确的解析工具:
# tools.py — fetch_task_files 的类型路由提示
next_step_hint = ""
if file_ext in ['.xlsx', '.xls']:
next_step_hint = "\n\n⚠️ 下一步:请立即使用 parse_excel(file_path) 读取此 Excel 文件"
elif file_ext == '.pdf':
next_step_hint = "\n\n⚠️ 下一步:请立即使用 parse_pdf(file_path) 读取此 PDF 文件"
elif file_ext in ['.png', '.jpg', '.jpeg']:
next_step_hint = "\n\n⚠️ 下一步:请使用 image_ocr() 或 analyze_image() 处理此图片"
elif file_ext in ['.mp3', '.wav']:
next_step_hint = "\n\n⚠️ 下一步:请使用 transcribe_audio() 转写此音频文件"
return f"文件已下载到: {file_path}\n文件大小: {file_size} 字节{next_step_hint}"这种设计把"工具选择"从模型的自由推理变成了工具返回值中的结构化引导——比在 System Prompt 里重复强调更可靠。
Python 沙箱:白名单 import + 受限 builtins
run_python 是最危险的工具——它能执行任意代码。GAIA Agent 通过白名单 import + 覆盖 __import__ + 受限 builtins 构建沙箱:
# tools.py — run_python 沙箱核心
ALLOWED_MODULES = {
'math': math, 're': re_module, 'json': json_module,
'datetime': datetime_module, 'collections': collections_module,
'random': random_module, 'string': string_module,
'itertools': itertools_module, 'functools': functools_module,
}
def restricted_import(name, globals=None, locals=None, fromlist=(), level=0):
if name not in ALLOWED_MODULES:
raise ImportError(f"不允许导入模块 '{name}'")
return ALLOWED_MODULES[name]
safe_builtins = {
'list': list, 'dict': dict, 'set': set, 'tuple': tuple,
'str': str, 'int': int, 'float': float, 'bool': bool,
'print': print, 'len': len, 'range': range, 'enumerate': enumerate,
'zip': zip, 'map': map, 'filter': filter, 'sorted': sorted,
'sum': sum, 'min': min, 'max': max, 'abs': abs, 'round': round,
'__import__': restricted_import,
'True': True, 'False': False, 'None': None,
}
namespace = {"__builtins__": safe_builtins}
namespace.update(preloaded) # 预注入 math, re, datetime, Counter 等
old_stdout = sys.stdout
sys.stdout = io.StringIO()
try:
exec(code, namespace)
output = sys.stdout.getvalue()
finally:
sys.stdout = old_stdout三层防护:(1) restricted_import 拦截未授权模块;(2) safe_builtins 移除 open、eval、exec 等危险内置;(3) stdout 重定向确保只返回 print() 输出。
RAG 知识库:检索增强 + 短路加速
RAG 模块不只是"检索相似文档",而是一个完整的分层检索 + 短路 + 解题建议系统。
架构设计
# rag.py — GAIARAGManager 核心结构
class GAIARAGManager:
def __init__(self):
self._embeddings = None # 延迟加载 HuggingFace Embeddings
self._llm = None # 延迟加载 LLM
self._vectorstore = None # 延迟加载 FAISS 索引
def retrieve_with_scores(self, query, k=3):
"""带相似度分数的检索"""
return self.vectorstore.similarity_search_with_score(query, k=k)
def query(self, question, k=3):
"""检索 + LLM 生成解题建议"""
docs = self.retrieve(question, k=k)
chain = self.rag_prompt | self.llm
return chain.invoke({"context": context, "question": question})所有属性都使用 @property 延迟初始化——首次访问时才加载嵌入模型和 FAISS 索引,避免启动时阻塞。
三级响应策略
rag_query 工具根据相似度分数返回不同级别的响应:
# rag.py — rag_query 三级响应
best_doc, best_score = results[0]
similarity = 1 / (1 + best_score) # FAISS L2 距离转相似度
if similarity > 0.85:
# 高相似度:直接返回答案(知识库匹配成功)
return f"【知识库匹配成功】直接答案: {answer}"
if similarity > 0.6:
# 中等相似度:返回答案 + 解题参考
return "【知识库参考】\n" + 参考文档
# 低相似度:调用 LLM 生成解题建议
return manager.query(question)短路机制
在 GaiaAgent.__call__ 中,agent loop 之前先做 RAG 短路检查。rag_lookup_answer 函数用 0.85 相似度阈值判断是否直接返回:
# rag.py — 短路查找
def rag_lookup_answer(question: str, min_similarity: float = 0.85):
manager = get_rag_manager()
results = manager.retrieve_with_scores(question.strip(), k=1)
if not results:
return None
best_doc, best_score = results[0]
similarity = 1.0 / (1.0 + float(best_score))
answer = (best_doc.metadata.get("answer") or "").strip()
if answer and similarity > min_similarity:
return {"answer": answer, "similarity": similarity}
return None这个设计的价值:已知问题零延迟返回。对于 GAIA benchmark 中的重复或高度相似的问题,跳过整个 agent loop,直接从向量库返回答案——成本几乎为零。
答案提取管道
Agent loop 结束后,原始输出往往包含大量推理过程、前缀、后缀。extract_final_answer 实现了一个五步清洗管道:
# agent.py — 答案提取管道
def extract_final_answer(result: dict) -> str:
# Step 0: 优先选择"无 tool_calls 的 AIMessage"(真正的最终答案)
for msg in reversed(messages):
if isinstance(msg, AIMessage) and msg.content:
if not (hasattr(msg, "tool_calls") and msg.tool_calls):
content = msg.content
break
# Step 1: 移除常见前缀
prefix_patterns = [
r'^(?:the\s+)?(?:final\s+)?answer\s*(?:is|:)\s*',
r'^(?:therefore|thus|so|hence)[,:]?\s*',
r'^(?:最终)?答案[是为::]\s*',
r'^根据(?:以上)?(?:分析|信息|计算)[,,::]?\s*',
]
# Step 2: 移除尾部解释
suffix_patterns = [
r'\s*(?:This|That)\s+(?:is|was|represents).*$',
r'\s*[(\(].*[)\)]$',
]
# Step 3: 提取 JSON 格式答案
# Step 4: 清理空白和引号
# Step 5: 数字格式处理(移除千分位逗号)消息选择的三级优先策略值得注意:无 tool_calls 的 AIMessage > 有 tool_calls 的 AIMessage > ToolMessage。这确保我们提取的是模型"最终思考"的输出,而非中间工具调用时附带的文本。
评测与可观测性
如果你只做一件事来提升 agent/workflow 的可靠性,我会选:把评测闭环做出来。
GAIA 的评测架构
app.py 通过 Gradio 提供了三个评测入口:
| 模式 | 功能 | 用途 |
|---|---|---|
| 单题测试 | 输入问题 → Agent 解答 → 提交评分 | 调试单个问题 |
| 批量评测 | 循环解题 → 逐题提交 → 汇总正确率 | 回归测试 |
| 自由问答 | 无 Task ID → 直接问答 | 功能验证 |
批量评测的核心实现:
# app.py — 批量评测
def on_run_evaluation(username: str, num_questions: int, progress=gr.Progress()):
questions = get_questions()[:num_questions]
correct = 0
for i, q in enumerate(questions):
# 问题间延迟(避免触发速率限制)
if i > 0 and BATCH_QUESTION_DELAY > 0:
time.sleep(BATCH_QUESTION_DELAY)
task_id, question = q["task_id"], q["question"]
answer = solve_question(question, task_id)
submit_result = submit_answer(task_id, answer, username)
correct += int(submit_result.get("is_correct", False))
accuracy = correct / len(questions) * 100
return f"正确: {correct}/{len(questions)} ({accuracy:.1f}%)"还有一个容易忽略的工程细节:预加载。Agent 和 LLM 在 Gradio 启动时通过后台线程预初始化,避免首次请求的冷启动延迟:
# app.py — 后台预加载
def preload_agent():
def _preload():
agent = get_agent()
get_llm_with_tools() # 触发 LLM 单例初始化
thread = threading.Thread(target=_preload, daemon=True)
thread.start()
preload_agent() # 启动时执行拓展:ReAct 能带来什么?
ReAct 提供了一个简单但很有用的"轨迹"约定:把推理与行动交织,明确写出这一轮要做什么(Reasoning)、调用哪个动作(Action)、从环境拿到什么反馈(Observation)。
它的工程价值主要有两点:
- 减少幻觉:缺信息就行动去拿 observation,而不是凭空补全。
- 更可调试:你可以沿着 action/observation 回放一次失败轨迹。
GAIA Agent 中,ReAct 的"Action/Observation"体现在:LLM 的
tool_calls(Action)+ 工具返回写入消息流(Observation),再由下一轮assistant继续推理。我们不强制模型把 Thought 逐字写出来,而是把可回放的工具调用轨迹作为调试主线——每轮迭代都打印 iteration 编号、响应摘要和 tool_calls 列表。